部署Google Cloud的機器學習 Pipeline
關於GCP 機器學習(後面會簡稱ML)的pipeline部署分為好幾個階段。從data ingestion/preparation再到根據訓練出來的模型來做data segregation. GCP提供幾種方式來實行ML pipeline. 我們也會介紹使用一般的computing services(例如:Compute engine/ Kubernetes engine)或託管性的服務(Dataflow/ DataProc)到特殊的ML服務,像是AI platform(之前叫做Cloud ML)來實行ML pipeline.
整個ML pipeline包含了幾個階段,從 Data Ingestion / preparation之後是 data segregation, 其次是model training 與evalution. 與其他軟體開發過程一樣,models與其他軟體一樣,應該以結構化的方式進行部署和監控。
ML Pipeline的結構
ML project起始於問題的定義。問題可能是: 如何通過向客戶推薦產品來提高銷售收入,如何評估醫學圖像以檢測腫瘤,或者如何識別欺詐性金融交易。這是三種非常不同類型的問題,但是它們卻可以透用使用ML技術來解決。
ML pipeline的階段分為以下幾個階段:
- Data Ingestion
- Data preparation
- Data segregation
- Model training
- Model evaluation
- Model deployment
- Model monitoring
雖然上面所列出的階段像是線性方式,但ML pipeline卻有著比線性方式更多的循環(如下圖所示)。這一部分就不會是主要以線性方式為主的 dataflow pipeline(ingest, transform, store data)。

Data Ingestion
在這個階段,Data ingestion可以是 batch or streaming.
Batch Data Ingestion
這種方式應該使用專門的process來為每個不同的data source做資料匯入。例如,使用一個process來處理 e-commerec的交易資料,而使用另一個process來ingest客戶資料。這種方式通常會是一個固定的時間區間來驅動,非常像是data warehouse的ETL(extraction/load/transformation)程序。而能夠追踪哪個batch data來自哪裡很重要,因此我們必須在每個ingestion的record中包含一個batch identifier。它使我們可以更輕鬆地比較跨dataset的結果。
Batch data可以用好幾種方式儲存。其中存放在Cloud storage是一個好的選擇,因為可以存放非結構化資就像file-based, 半結構化以及結構化資料。而Cloud storage 的lifecycle management功能也幫助我們管理資料的生命週期將資料在處理過後移動到Nearline or Coldline storage。 Object storage也適合來做Data lakes,這是一個可以存放各式各樣的資料格式的儲存庫。假若你的組織已經有很好的Data lakes, 你就可以有一些效益在裡面,像是使用 metadata catalog服務給ML使用。
Streaming Data Ingestion
Cloud Pub/Sub是被設計用來使用在可擴充的訊息傳遞,其中就包含了streaming data ingestion。使用Cloud Pub/Sub來處理 streaming data ingestion有幾種效益。Cloud Pub/Sub是一個全託管式的serverless服務。Client 可以push 每秒1GB的資料,而在subscribers方面針對pull subscriptions可以處理最高每秒2GB及push subscriptions 每秒100MB的資料量。Message 屬性是由key-value pairs組成的。Key最高是256 bytes,而value可以到 1024 bytes.
經由Cloud Pub/Sub處理後的資料可以儲存到像是Bigtable或Firebase, 或是直接被ML 流程中使用到的服務(Dataflow/ Dataproc/ GKE/ Compute engine)直接處理.
使用 Bigquery 時,我們可以選擇使用streaming insert。 data通常可以在ingesting後的幾秒鐘內使用,但最多可能需要 90 分鐘才能export或copy操作data。 streaming insert支持重複資料刪除。
要進行重複刪除,我們需要為每條record傳遞一個名為 insert ID 的插入標識符號。 Bigquery 將該標識符號緩存至少一分鐘,並將盡最大努力執行重複資料刪除。 如果我們需要最大化ingestion rate並且可以容忍資料重複,如果不傳遞 InsertID 的值則將允許更高的ingestion rate。 data可以被ingest到ingestion time partitioned table以及按日期和timestamp partitioned table。
資料被傳輸到GCP之後,下一步是準備用於機器學習眼算法的data
Data Preparation
資料準備是將資料從原始資料轉換為適合機器學習演算法分析的結構和格式的過程。下面是資料準備階段的三個步驟
- Data exploration
- Data transformation
- Feature engineering
Data exploration
資料探索是處理新data source或發生重大變化的data source的第一步。 此階段的目標是了解資料的分佈和資料的整體質量。
為了瞭解資料的分佈,我們需要來看一下基本的數字屬性的描述性統計,像是數字的最大,最小,平均與mode。當我們處理數字型資料時,使用直方圖就是有用的。它能幫助我們了解屬性中不同值的數量,也就是屬性的基數(cardinality),與每個value出現的頻率。
通過確定dataset中缺失或無效值的數量來評估資料的整體質量。假如record的某些屬性是遺失的,基於使用情況我們也許會丟棄這筆資料或用預設來填補。相同的,若這筆屬性的value是無效的,可能是沒有這個郵遞區號,也需我們會參考另外一個屬性來修正這個value,像是對照在哪一區哪一鄉鎮來修正。
我們在Google Cloud的資料靈活性與可攜性有提到Cloud Dataprep就是來設計這一類的資料探索與資料轉換使用的。而Cloud Data Fusion,也是用來與Cloud dataprep一樣的使用目的,不過它是一個全託管是並且是code-free的data ingestion 服務。
Data Transformation
Data transformation是將data從其原始形式mapping到允許機器學習的資料結構和格式的過程。 轉換可以包括以下內容:
- 使用預設值填補缺失值
- 用基於這筆record中其他屬性的推斷值替換缺失值
- 用基於其他records中其他屬性的推斷值替換缺失值
- 用基於其他records中的同個屬性推斷的值替換缺失值
- 更改數值的格式,例如將real unmber截斷或四捨五入為整數
- 根據業務邏輯移除或修正attribute value,像是無效的產品編號
- 去除重複的records
- join兩個不同dataset的records
- Aggregating data, 將一分鐘或五分鐘的監控值加總平均。
Cloud Dataprep是用來使用在進行交互式的data transformation。但如果是資料量較大或是轉換的過程較為複雜,這時使用Cloud dataflow就是一個好選擇。Cloud dataflow同時支援batch 與streaming processing.
Feature engineering
Feature engineering是添加或修改特徵的呈現以讓資料的隱式模式更加明確的過程。例如,如果兩個數字特徵的比率對分類很重要,那麼計算該比率並將其作為特徵包含在內可能會提高模型質量。
當我們使用採用某種線性分離的模型進行預測時,特徵工程尤其重要。 例如,考慮具有兩個標記為正或負的特徵的dataset。 Dataset可以繪製在 x-y 軸上。 如果二元分類器可以找到一條線來分隔正例和負例。 這稱為線性問題(如下圖範例)。
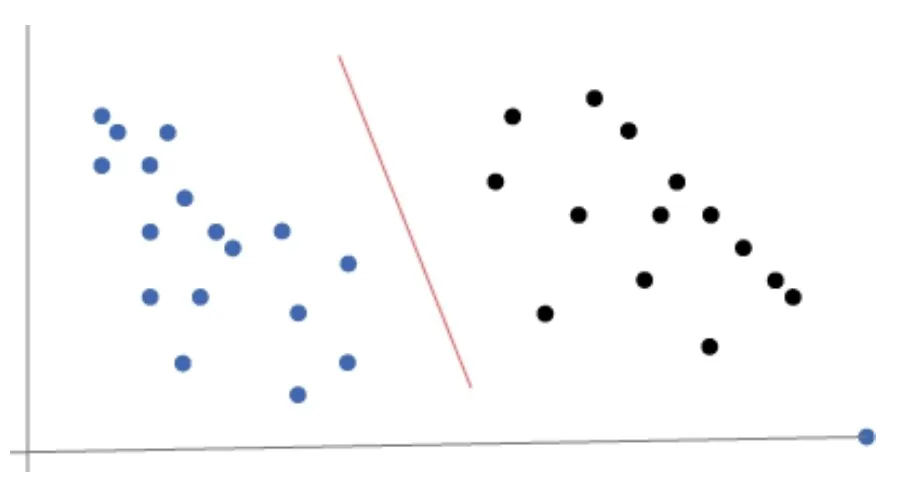
現在讓我們再考量沒有一條直線就可以讓我們做分類的例子,如下圖

根據上圖範例,我們可以創建新功能,允許我們在更高維空間中表示每個instance,其中線性模型可以分離instance。 一種方法是使用cross product。 它是通過將兩個或多個數字特徵相乘而創建的。 例如,如果我們有兩個數字特徵 x 和 y,我們可以將它們相乘以創建一個新特徵 z; 也就是說,z = x * y。 現在不是在二維空間中重新表示每個instance,而是在三維空間中表示。 cross product對非線性信息進行編碼。 因此可以使用線性模型來構建分類器。
此特徵對於cross-categorical features也很常見。 例如,一個電商構建模型來預測客戶會有多少錢,可能會使用郵遞區號和信用評等的組合來創建新特徵。 假設有 1,00 個郵遞區號和四類信用評等,這些特徵的交叉將創建一個具有 4,00 個可能值的新特徵。
另一種常見的特徵工程技術是one-hoting encoding。 此過程將分類值列表映射到一系列二進制數,其中單個值設置為 1,所有其他值設置為 0(如下圖範例)。
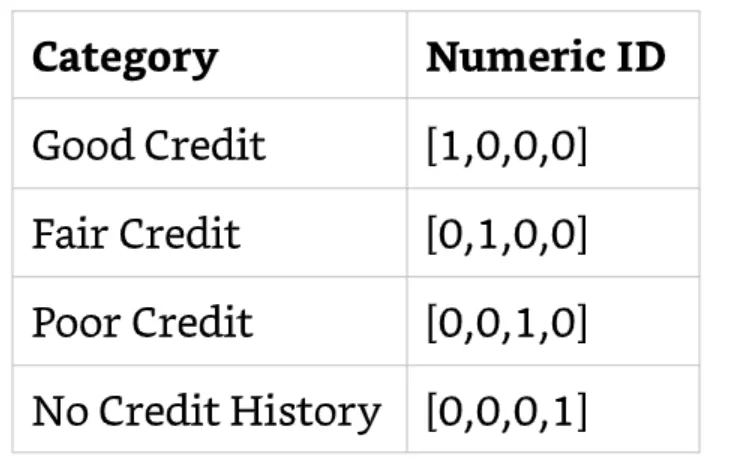
One-hot encoding通常與神經網路和其他不直接處理分類值的演算法一起使用。 決策樹和隨機森林直接使用分類值,因此不需要One-hot encoding。
Data Segregation
這是一個資料拆分為三種資料的過程,三種資料分別是training, validation, and test 。
Training Data
ML的model是靠將有些資料的輸入映射到可以預測輸出的函數功能。這種映射的產生是來自於資料本身而非我們手動的程序設計。而這些產生映射資料就稱為training data.
Validation Data
雖然ML演算法可以從資料中學習到一些values, 也稱為 parameters, 而這些是從training data學習到的。而有些vaules則是ML工程師所定義的。而這些人為定義的我們稱為hyperparameters。 Hyperparameters是一種拿來配置 modle的Values,與它們可以包括神經網路中的layer數或隨機森林模型中tree的最大深度。Hyperparameters會因演算法不同而有所差異。我們可以參考下面兩張圖參考
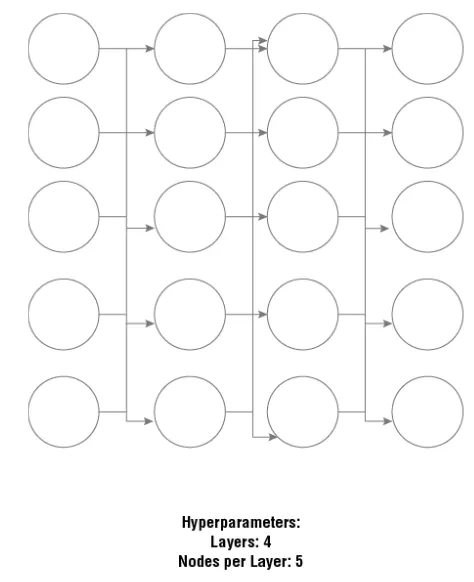
上圖為用hyperparameters為神經網路定義layer數量以及每個layer要有多少node
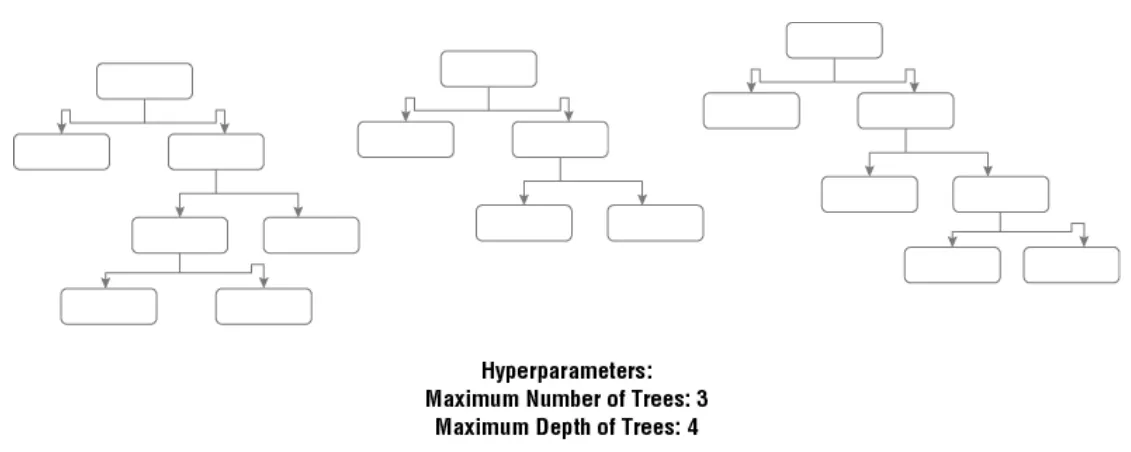
上圖為用hyperparameters為隨機森林樹定義要有幾個tree及tree的深度。
而Validation data set是用來調整hyperparameters。調整通常需要靠使用不同的值來實驗。例如,在神經網路中,我們可以不斷調整layer數量以及每個layer要有多少node, 以及學習率(learning rate)。
神經網路中的layer數量以及每個layer要有多少node決定了我們的模型將起作用以及訓練需要多長時間。這裡沒有一個可用的計算方式來決定最佳的layer and node的數量,意思是,我們需要用不同的數量組合來試驗來達到最佳的設定配置。
而Learning rate決定當在training時有多少的神經網路權重需要被調整。Learning rate如果越大則權重的變動也越大,也許model可以學習的很快。然而我們可能會錯過一組最佳的權重,因為權重的變動程度太大可能會導致我們錯過最佳權重。Learning rate如果幅度較小model學習的時間就會比較慢,但我們找到最佳權重的機會就會更高。
每次我們在嘗試不同的hyperparameters vlaue組合時,我們需要訓練模型並驗證結果。我們不應該針對不同的hyperparameters組合使用不同的資料。而這些為不同hyperparameters組合來訓練model訓練的資料稱為validation data。
Test data
當我們找到最佳的hyperparameters之後,接下來就需要進行測試。而我們就需要使用到測試資料,這些資料必須是要在驗證階段沒有用到過的才行。而測試的結果就可以拿來評估模型是否真的可以進行實際作業。
以下有一些我們將資料拆分成三個部份的主要準則
- 確認test 與valitation的dataset大到可以產生統計意義的結果
- 確認test 與valitation的dataset可以代表整體資料
- 確認 training dataset大到可以建模學習以便以合理的精確度和recall做出準確的預測
分拆資料完成後,下一步就是ML pipeline中的 Model training
Model Training
這是使用training data來建立模型是可以執行預測的流程,有時又稱為 fitting a model to data。
Feature Selection
這是建模的另一個部份。這是一個評估有沒有特別的attribute 或feature能夠對建立模型的預測性是有幫助的。目標是能夠讓dataset的feature能夠讓模型學到更正確的預測。選擇Feature來達成如下目的:
- 減少訓練模型所需的時間和資料量
- 讓模型容易被理解
- 減少必須納入考量的特徵數量,這個也稱curse of dimensionality(維度的詛咒或維度災難)
- 降低模型overfitting(過適)訓練資料的風險,這反過來又會降低模型對訓練期間未遇到的資料的準確性
有許多不同的演算法來選擇features。 最簡單的方法是用每個features subset訓練一個模型,然後看看哪個subset的效能最好。 儘管它簡單且易於實現,但這種天真的方法是無法擴展。
另一種方法是features subset從開始,測量其效能,然後對features subset進行增量修改。 如果修改後的subset的效能更好,則保留修改,並重複該過程。 否則,這個修改就被丟棄,另一種很累。 這種技術被稱為greedy hill climbing。
還有許多其他基於資訊理論、Features之間的相關性以及啟發式的feature選擇方法。
Underfitting, Overfitting, and Regularization
在我們順練模型時會發生兩個問題, underfitting與overfitting.
Underfitting創建的模型無法正確預測訓練資料的值或訓練期間未使用的新資料。如果模型在多個演算法中表現不好,並且在使用用於訓練它的相同資料評估模型時,則為underfitting,這可能是由於訓練資料不足造成的。underfitting問題可以通過增加訓練資料量、使用不同的機器學習眼算法或修改hyperparameters來修正。在改變hyperparameters的情況下,這可能包括在神經網路中使用更多node或layer,神經網路是用於進行計算的互連人工神經元的集合,或者增加 隨機森林中tree的數量和深度 — — 換句話說,集合決策樹,它是確定label的特徵的有序連接。
當模型太適合訓練資料時,就會發生overfitting。當資料中存在雜訊並且模型將雜訊fit為正確的data pont時,就會發生這種情況。雜訊是從信號處理借用的術語,用於描述dataset中但不是由正在建模的底層過程生成的data point。例如,網路中發生的一個問題,在這種情況下,該data point將會是雜訊。例如下圖,當training data和validation data不明顯或training data很少時,可能會發生overfitting。
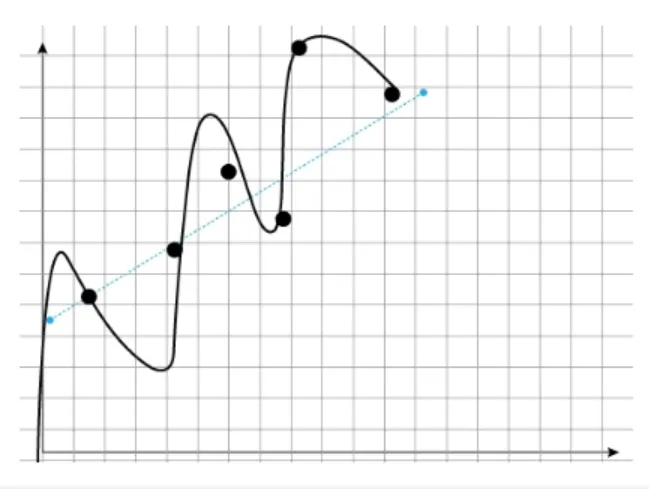
上圖虛線的部分是一個沒有ovetfit的線性模型,而實線的部分我們可以看到有些離群的data point並沒有落在虛線上,而這樣就造成了overfitting.
一個可以減少這類離群值造成的overfitting, 就是增加大量的data point來減少可能會發生overfitting的風險,但這樣也會讓模型更加的複雜。而這樣的過程就稱為regularization(正則化). 正則化有兩種 L1 regularization(也稱為 Lasso regularization)與 L2 regularization(也稱為Ridge regularization).
在L1 and L2 regularization中,我們在function加入了penalty(懲罰項),這個function是模型在預測過程中會得到error(overfitting 就是在training data會很低但在testing data卻很高),也稱為 cost function。 ML演算法使用了這些cost functions來增加預測的品質。 在 L1 正則化中,懲罰項是基於模型中係數的大小或絕對值。 在 L2 正則化中,懲罰項是基於係數大小的平方。
L1正則化可以將一個特徵的係數縮小為零,有效地將特徵排除在外.下圖為一個overfitting, underfitting 與我們想要的資料模型
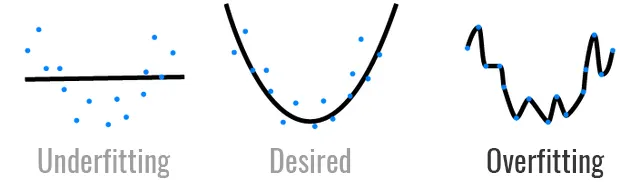
(圖片來源 : Memorizing is not learning! — 6 tricks to prevent overfitting in machine learning.)
Model Evaluation
以下幾種方式來幫我們理解與評估ML模型的品質,包括:
- Individual evaluation metrics
- K-fold validation
- Confusion matrices
- Bias and variance
Individual evaluation metrics
ML模型可以依據多個指標來評估,包含以下
Accuracy 這是量測 ML模型有多常做出正確的預測,計算方式
Accuracy = True Positive/ Total Predicted
Precision 這是被正確識別到的positive cases的比例。這種量測方式也稱 positive predictive value. 公式如下:
Precision = True Positive / (True Positive + False Positive)
Recall 這是被正確識別到的實際positive case數,而不是被識別為positive的negative cases數量。公式如下:
Recall = True Positive / (True Positive + False Negative)
F1 Score 這是將 precision與Recall組合起來的方式,而計算F值的公式如下:
2*((precision * recall) / (precision + recall))
在最佳化preision或recall時會有一些trad-offs。因為F1是將precision與recall組合起來的方式,所以它經常被拿來評估模型。
K-fold validation
這是將資料拆分到一個名為 k segments(k是一個整數)來評估模型效能的方式。例如,我們將資料拆分成5個相同size的subset,那將是一個五重交叉驗證dataset.
K-fold cross-validation dataset的運用方式如下。整個dataset拆分資料是shuffle 或 random的分配到 k 個群組。其中一個群組是用來做evaluation,而其他的group 則是用來train model的。所以當model train完後,當初沒有進train mode的dataset就被拿來做validation。之後整個過程重來一遍,但是這一次的validation 的dataset換成別組,然後再拿剩餘的dataset來train model。如此重複這個過程直到所有的group都當過validation的dataset。
如何選擇 k 的值,以便每個segment都夠代表整個dataset。 在大多數情況下,將 k 設置為 10 似乎效果很好。當設置 k 等於dataset的records數時,稱為 leave-one-out-cross-validation.
Confusion Matrices
一起使用Confusion matrices與classification models會顯示模型的相對性能。以Binary分類器來說,confusion matrices將會是一個 2x2的矩陣(如下圖)。
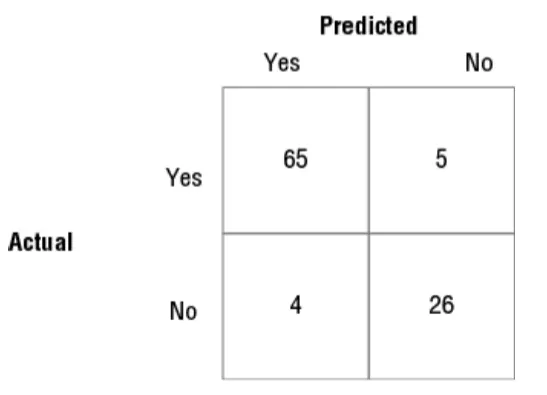
上圖中是進行 100 次預測的分類器的confusion matrix(n=100)。在這個100次的預測中,Predicted with Actual Yes一共有70次, Actual Yes是65次預測正確, Actual NO是5次 . Predicted with Actual No一共有30次, 其中26次是預測正確的,另外四次則是不正確。使用這種方式的好處在於我們可以很快的模型的正確性。
Bias and variance
預測模型產生的誤差可以通過Bias(偏差) 與variance(方差)來理解。資料科學家通常都會用不同sets and size的訓練資料來跑多次訓練模型的循環。這會讓他們更能理解到這模型的bias and variance。
偏差是模型的平均預測與模型的正確預測之間的差異。 具有高偏差的模型往往會過度簡化生成訓練資料的過程; 這模型是uderfitting。 當資料科學家使用不同的dataset訓練模型時,偏差是通過平均預測值與目標值的差異來衡量的。
方差是模型預測的可變性。 它有助於了解模型預測在多個訓練dataset上有何不同。 它不衡量來自目標值的預測有多準確,而是衡量要預測的模型的可變性。 具有高方差的模型往往會overfitting訓練資料,因此該模型在對訓練資料進行預測時效果很好,但它不能概括到這模型以前從未見過的資料。
理想情況下,模型應該同時具有低偏差和低方差,這是通過處理多個training datasets來降低模型的mean squared error(MSE) 來實現的。
Model Deployment
ML模型 program是與其他programs沒有甚麼不同。 部署時,一樣使用與寫coded application相同的最佳實踐來管理它們,包括版本控制、測試以及CI和部署。
Model Monitoring
ML 模型監控也與一般程式開發的方法相同。 第一個就是效能監控,來看模型使用資源的狀況。GCP的Stackdriver的Monitoring就可以被用來收集這一類的效能數據,而Logging則可以用來擷取模型在運作時event的資訊。
除了效能監控外,模型的正確性也應該要被監控。這可以通過使用模型來預測模型未訓練的new instance的值來完成。例如,如果一周前部署了一個模型,並且自那時起有新資料可用,並且預測特徵的實際值是已知的,那麼這個新資料可用於評估模型的準確性。
但是,請注意,即使模型沒有改變,如果流程或正在建模的實體發生變化,模型的準確性也會發生變化。例如,考慮開發一個模型來預測客戶將在特定類型的產品上花費多少。模型使用在某個時間點收集的資料進行訓練。現在想像一下公司改變了它的定價策略。用於訓練模型的資料並沒有反映到客戶對新定價策略的反應是甚麼,因此會根據先前的策略進行預測。在這種情況下,應該通過對自採用新的訂價策略以來收集的資料進行訓練來更新模型。
用於部署 ML Pipeline的GCP服務選項
我們使用GCP的服務來運行ML pipeline的選擇有很多種,從自己寫code/application放在compute engine到使用全託管的GCP ML服務。我們以下會介紹使用四種GCP的ML能力的效益。它們是
- Cloud AutoML
- BigQuery ML
- Kubeflow
- Spark Machine Learning
Cloud AutoML
Cloud AutoML是一種ML服務,專為希望將ML融入其應用程序而無需學習ML的許多細節的開發人員而設計。 這些服務使用 GUI 來訓練和評估模型,從而減少開始構建模型所需的工作量。 以下幾種 是AutoML 產品:
- AutoML Vision
- AutoML Video Intelligence
- AutoML Natural Language
- AutoML Translation
- AutoML Tables
AutoML Vision有幾種能力:
AutoML Vision Classification 這讓使用者可以用這個服務來分類圖片
AutoML Vision Edge — Image Classification 這個可以讓使用這客製他們的image classification models並部署到edge devices. 這個方式的好處是Application需要跑在local端並能及時回應分類的結果。
AutoML Vision Object Detection 這個能讓user偵測images裡的object並提供相關資訊,像是這張圖片在哪裡拍的。
AutoML Vision Edge — Object Detection 這個與上面一樣的功能,不一樣的地方在於運行的位置可能是分佈系統的devcie或是remote or edge processing.
AutoML Video Intelligence classificationd這是被用來訓練ML modelsg使用自定義標籤集來分類video的segments. AutoML Video Intelligence Object Tracking 則用來訓練模型能夠偵測與追蹤video segments的多個objects.
AutoML Natural Language 能讓我們部署能夠分析文件並分類,辨認在text裡的entities與決定在text 中情緒或屬性的ML Application。
AutoML Translation 讓我們能有能力create 自訂義的 translation models. 如果你正在為具有自己命名法的領域(例如科學或工程領域)開發翻譯應用程序,這將非常有用。
AutoML Tables 這是基於結構式資料建立的ML models. AutoML提供工具能購清理與分析datasets, 包括偵測missing data與確定每個特徵的資料分佈。它也夠進行一般的feature engineering 工作像是normalizing numeric values, creating buckets for continuous value features 與extracting date and time features from timestamp. AutoML使用多個ML演算法來建立模型,包含線性回歸,深度神經網路,gradient-boosted decision trees, AdaNet與 由各種演算法生成的模型集合。這一些可以讓AutoML table 來針對每種狀況來決定使用哪種演算法。
BigQuery ML
這是在BigQuery中加上ML的功能,並且透過SQL函數的方式來建立Model.這樣跟其他GCP service比較起來的好處是我們不用在建立ML Model時將資料搬來搬去。
BigQuery ML的function可以透過以下介面完成
- Bigquery web user interface
- bq command-line tool
- Bigquery REST API
- 外部工具,如Jupyter Notebooks
BigQuery支援以下幾種ML演算法
- 線性回歸,做foreast的
- Binary logistic regression(二元邏輯迴歸),針對兩個label做分類
- Multiple logistic regression(多元邏輯迴歸),針對兩個以上的label做分類
- K-means clustering, 對資料做分割
- TensorFlow model importing , 讓bigquery的user可以使用自定義的TensorFlow models
在某些使用案例中我們可以使用 AutoML Tables或 Bigquery ML. 差異在於如果你很懶或是沒有太多的經驗來使用不同的演算法或特徵工程來優化你的模型,哪麼用AutoML Tables是比較好的選擇。又或者你有很多features需要做特徵工程,哪麼使用AutoML Tables來自動化一些通用特徵工程作業也是很好的選擇。但如果你經驗夠多技巧夠好,哪麼使用Bigquery ML比較能節省你的時間。因為使用AutoML tables通常會去對你的資料嘗試測試它所有已知的建模方式,所以會多花一些時間。
Kubeflow
這是一個open source project. 主要是將建模的worload 放在 Kubernetes平台上跑。這樣的方法可以好處是你的workload是可擴充的並且是具可攜性的。kubeflow原本始於一個幫助TensorFlow job運行在Kubernetes 上的工具,不過現在已經延伸成執行ML pipeline 的多雲運作的框架。所以它也可以將ML workload運作在混合雲的環境中。
Kubeflow由以下元件組成:
- 支援 training Tensorflow models
- TensorFlow服務,是用在已經train好的model並讓它對其他的服務是可用的
- A JupyterHUB installation, 這是一個用於生成和管理 單一使用者Jupyter Notebook server 的多個instance的平台
- kubeflow Pipelines, 用來定義ML workflow
kubeflow workflow會訂出ML worflow裡所有會需要用的元件。 Pipeline會被封裝成Docker images.
會使用的kubeflow可能是因為你已經在使用Kubernetes engine並有ML 建模的經驗。使用kubeflow會有一些手工要做但卻可以將ML worload進行擴展,但它提供的功能卻沒有AutoML或BigQuery ML多。
Sparking Machine Learning
我們之前提到過Cloud Dataproc是一個託管式的Spark and Hadoop服務。spark 包含一個名為 MLib 的機器學習庫。不管你是已經在用Cloud Dataproc或自建的Spark Cluster, 都可以用Mlib來跑ML workload。
Spark MLib 包含了以下幾種工具:
- 用在推薦引擎中的classification, regression, clustering, and collaborate filtering的演算法
- 支援特徵工程,data transformation與dimensionality reduction(降維)
- 可以執行 multistep workload的 ML pipeline
- 其他工具,如math libraries與data management tools
Spark MLib的API支援將ML pipeline多個步驟連接再一起。Pipeline由以下幾種類型的components組成:
Data Frames 以表格(tabular)型式存放在memory的資料
Transformation 將函數運用在data frames中,包含應用ML Modles來產生預測
Estimators 使用ML演算法來創建模型的演算法
Parameters 被Transformation 與estimators所使用
Spark MLib有著廣泛的ML演算法。若GCP內ML服務沒有你要的演算法,擬就可以使用Spark MLib. 以下是它包含的演算法
- 支援用在分類的向量機
- 支援用在forcast的線性迴歸
- 用於分類的決策數,隨機森林樹,gradient-boosted trees
- 用於分類的Naive Bayes
- 用於資料分割的 K-means clustering 與streaming k-means
- 用於資料分割的Latent Dirichlet allocation
- 用於降維的Singular value decomposition 與principal component analysis
- Frequent Pattern(FP) — 來自頻繁模式挖掘的增長和關聯規則, 常用在零售業來挖掘客戶最常一起買那些商品。最有名的案例就是Walmark啤酒與尿布商品的故事。
以上就是GCP ML Pipeline簡單的介紹
