機器學習的設計模式 — 資料的呈現

機器學習(以下簡稱ML)的核心其實就是數學運算,而且只能運算特定類型的資料型式。但是在真實世界中,我們的很多資料是無法能夠立刻丟進去做數學運算的。例如,決策樹(decision tree)的數學運算 — 決策樹機器學習軟體通常還包括從資料中學習最佳樹的功能以及讀取和處理不同類型的數字和分類資料的方法。 然而,支撐決策樹的數學函數(如下圖)對boolean變量進行運算並使用諸如 AND或OR 之類的運算(如下圖)。
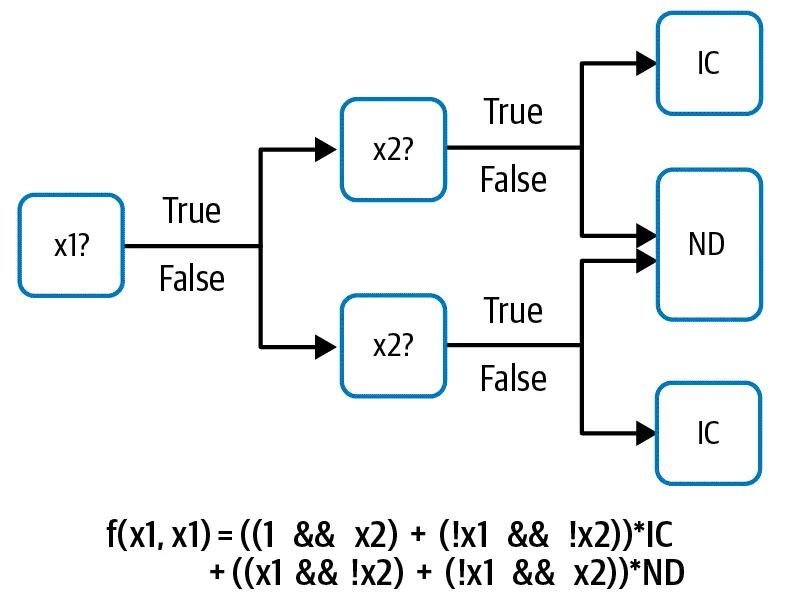
假設我們要對新生兒做出生時需要留院照護(簡稱IC)或是正常出院(簡稱ND),而決策樹會有兩個輸入的變量,分別是x1, x2。哪麼我們的訓練模型就會如上圖。
針對這兩個x1, x2,我們考慮使用新生兒是否在醫院出生與其體重來當作輸入變量。是不是在醫院出生可以當作輸入變量嗎?答案是不行,因為這個變量只有"是(True)"與"不是(False)"兩種輸入值,這樣的輸入是boolean的AND操作無法直接運算的。因為剛剛提到ML只會做數學運算,而True / False不能直接操作的資料型態。當然我們也可以將醫院這個變量轉換成boolean AND可以操作的式子:
x1 = (醫院 IN 台北)
這樣式子就會有醫院在台北就為True,若不式就是False。同樣的,新生兒的體重也無法讓boolean AND/OR 可以直接運作,我們可以加入條件來辨識:
x1 = (新生兒體重 < 2000公克)
我們也可以使用醫院或新生兒體重的權重來當作模型的輸入值。我們可以使用醫院或新生兒體重作為模型的輸入值。 這是輸入值(醫院、複雜object或v新生兒體重、浮點數)如何以模型期望的形式(boolean)呈現的範例。這就是本文的標題 — "資料的呈現"。
本文中,我們會用輸入(input)來呈現真實世界的資料輸入(例如剛剛提到的新生兒體重)與另一個專門術語: feature來呈現經過轉換後的資料(例如低於2000公克的體重),而這個資料是會實際被模型運作的。我們在create feature的過程稱為特徵工程(feature engineering),我們可以想像成特徵工程就是我們選擇資料要怎麼樣的呈現。
當然,與其直接將規則寫死在我們的參數中(體重低於2000公克),在ML的世界中我們比較傾向ML模型通過選擇輸入(input)變量和閾值(threshold)來學習如何創建每個node。決策樹是能夠學習資料呈現的ML模型的一個例子。 我們在本文中看到的許多模式將涉及類似的可學習的資料呈現。
崁入式設計模式是深度神經網路能夠自行學習的資料呈現的典型範例。在嵌入設計模式中,學習到的資料呈現比輸入更密集(dense)且維度更低,輸入可能是稀疏的(spare)。學習演算法需要從輸入中提取最顯著的資訊,並在特徵中以更簡潔的方式來呈現。學習特徵以呈現輸入資料的過程稱為"特徵提取(feature extraction)",我們可以將可學習的資料呈現視為自動化的工程特徵。
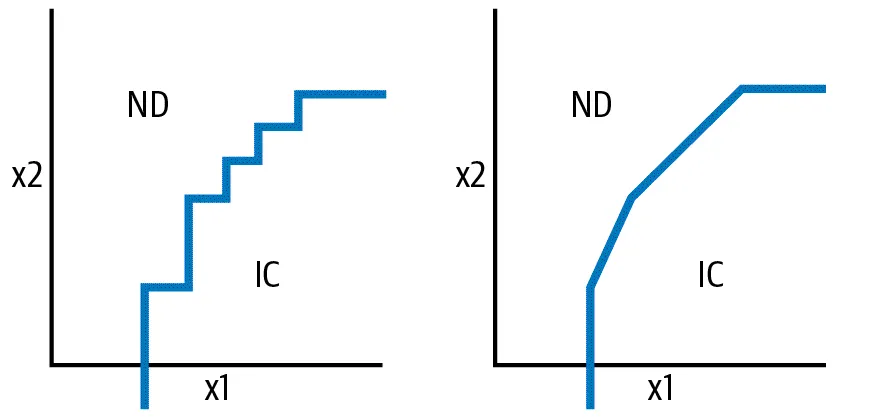
資料呈現甚至不需要是單個輸入變量 — — 例如,傾斜決策樹通過對兩個或多個輸入變量的線性組合進行閾值化(thresholding)來創建boolean feature。每個節點只能表示一個輸入變量的決策樹簡化為逐步線性函數,而每個節點可以表示輸入變量的線性組合的傾斜決策樹簡化為分段線性函數(下圖)。考慮到需要學習多少steps才能充分表示直線,分段線性模型更簡單、更容易學習。這個想法的延伸是Feature Cross設計模式,它簡化了multivalued categorical variables與 AND 之間關係的學習。
資料呈現不需要學習或固定 — — 混合也是可能的。 Hashed Feature 設計模式是確定性的,但不需要模型知道特定輸入可以採用的所有可能的值。 到目前為止我們看到的資呈現都是一對一的。 雖然我們可以分別表示不同類型的輸入資料,也可以將資料的每個部分表示為一個特徵,但使用 Multimodal Input 可能更有利。
簡單的資料呈現
在我們深入研究可學習的資料呈現、特徵交叉(feature crosses)等之前,讓我們看看其他更簡單的資料呈現。 我們可以將這些簡單的資料呈現視為ML中的常見術語——不完全是模式(patterns),但仍然是常用的解決方案。
數字型的輸入
現代化且大規模的ML模型(如隨機森林樹,SVM,神經網路)運算的都是數字,所以這些模型的輸入(input)也是數字。
為什麼縮放(Scaling)是好用的
通常,由於 ML 框架使用優化器(optimizer),該優化器可以很好地處理 – 1到 1 範圍內的數字,因此將數值縮放到該範圍內可能是有效益的。
哪為什麼縮放的數字會是介於 -1 到 1之間呢?
梯度下降(Gradient descent)優化器需要很多步驟(steps)才能到達loss function的谷底。這是因為具有較大相對量級的特徵(features)的導數也會趨於較大,從而導致權重(weight)的更新會變得不正常。 異常大的權重更新將需要更多的步驟來收斂,而越多steps運算的負載就會加重。 將資料“居中”到 [– 1, 1] 範圍內使誤差函數會變得更加球形。 因此,使用轉換資料訓練的模型趨於更快收斂,因此訓練(電腦運算)更快/成本更低。 此外,[– 1, 1] 範圍提供最高的浮點精度。
縮放的另一個重要原因是一些ML演算法和技術對不同特徵的相對大小非常敏感。 例如,使用歐幾里得距離作為其鄰近度度量的 k-means clustering演算法最終將嚴重依賴具有較大量級的特徵。 缺乏縮放也會影響 L1 或 L2 正則化的效果,因為特徵的權重大小取決於該特徵的值的大小,因此不同的特徵會受到正則化的不同影響。 通過將所有特徵縮放到 [– 1, 1] 之間,我們確保不同特徵的相對幅度沒有太大差異。
線性縮放(scaling)
以下為四種常用的線性縮放型式
Min-max scaling
數值是線性縮放的,因此輸入可以取的最小值縮放到 –1,最大可能值縮放到 1:
x1_scaled = (2*x1 — max_x1 -min_x1) / (max_x1- min_x1)
min-max scaling的問題在於最大與最小值(max_x1 and min_x1)的預估通常來自於訓練資料集,而這些資料通常都有"離群值"。所以真實的資料通常會被壓縮在 -1到1之間。
Clipping(剪裁 — 與min-max scaling結合)
通過使用“合理”值而不是從訓練資料集中估計最小值和最大值,幫助解決離群值的問題。 數值在這兩個合理邊界之間做線性縮放,然後裁剪到 – 1到1 範圍內。 這具有將離群值視為 –1 或 1 的效果。
Z-score 正則化
通過使用在訓練資料集上預計的平均值和標準差對輸入(input)進行線性縮放,解決了離群值問題,而無需事先了解合理範圍是多少:
x1_scaled = (x1- x1的平均值) / x1的標準差
這個方法的名稱反映了這樣一個事實,即縮放值的平均值為零並通過標準差進行正則化,因此它在訓練資料集上具有單位方差(unit variance)。 縮放值是無邊界的,但大部分時間確實在 [– 1, 1] 之間(67%,如果資料分佈是鐘型曲線的)。 超出此範圍的值的絕對值越大,它們就越少會出現,但它們仍然存在。
Winsorizing
使用訓練資料集中的經驗分佈將資料集裁剪到資料值的第 10 個和第 90 個百分位(或第 5 個和第 95 個百分位,依此類推)給出的邊界。 winsorized 值是min-max縮放。
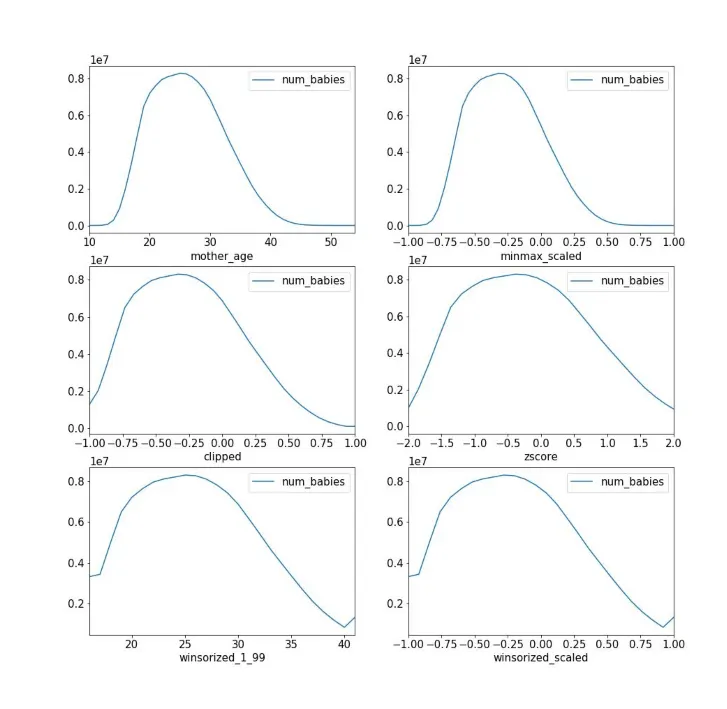
上述提到的所有方法均屬線性縮放資料(在clipping和 winsorizing 的情況下,在正常範圍內線性)。 Min-max 和clipping往往最適均勻分佈(uniformly distributed)的資料,而 Z-score 往往最適合常態分佈(鐘型曲線)的資料。 嬰兒體重預測範例中不同縮放函數對x軸(媽媽的年齡)的影響如下圖所示
不要捨棄離群值
我們將Clipping(裁剪)定義為將小於 –1 的值並將其視為 –1,將大於 1 的值視為 1。不要丟棄此類“離群值”,因為我們期望ML模型在正式環境中會遇到這樣的離群值。以 55 歲母親所生的嬰兒為例。因為我們的資料集中沒有足夠的年長母親,Clipping最終將所有 45 歲以上的母親視為 45歲。同樣的處理將應用於正式環境,因此,我們的模型將能夠處理年長的母親.如果我們簡單地丟棄所有 55 歲以上母親所生嬰兒的訓練樣本,該模型將不會學會反映離群值。另一種思考方式是,雖然丟棄無效輸入是可以接受的,但丟棄有效資料是不可接受的。因此,我們有理由丟棄母親的年齡是負數的(年齡沒有負數),因為這可能是資料輸入錯誤。在正式環境中,輸入資料的驗證將確key in的人必須重新輸入母親的年齡。然而,我們沒有理由丟棄 母親年齡為 55 的資料,因為 55歲 是一個完全有效的輸入,並且一旦模型部署到正式環境中,我們預計將會遇到 55歲甚至年齡更大的母親歲數。
在下圖中,我們可以注意到 minmax_scaled(右上角) 使 x value進入所需的 – 1到 1 範圍內,但在曲線的最末端我們並沒有足夠的資料顯示這些極端值。 Clipping匯總了許多有問題的value,但需要使clipping閾值(thresholds)完全正確 — — 在這裡,40 歲以上母親的嬰兒數量緩慢下降,這給設定hard thresholds帶來了問題。 Winsorizing 與Clipping類似,需要使百分位數閾值完全正確。 Z-score 正則化改進了範圍(但不會將值限制在 [– 1, 1] 之間)並將有問題的值推得更遠。 在這三種方法中,zero-norming最適用於預估母親年齡與新生兒關係間的這個問題,因為年齡的raw data有點像鐘形曲線。 對於其他問題,min-max scaling、Clipping或 winsorizing 可能更適合。
非線性轉換(Nonlinear transformation)
如果我們資料在呈現時是偏斜的並且不是均勻分布也不是鐘形曲線呢?這一類的狀況,解決的方法是在Scaling之前,將非線性轉換apply到input。一種常見的技巧是在Scaling之前取input value的對數。 其他常見的變換包括 sigmoid 和多項式的展開(平方、平方根、立方、立方根等)。 如果轉換後的值的分佈變得均勻或正態分佈,我們就會知道我們有一個很好的轉換函數。
假設我們要建立一個模型來預測一本科幻小說的銷售。其中一個資料input是與這本小說主題有對應到的維基百科頁面的瀏覽數。然而,維基百科頁面的瀏覽量是高度偏斜的,並且佔據了很大的資料範圍(見下圖 左一圖:資料分佈高度偏向於很少瀏覽的頁面,但最常見的頁面被瀏覽了幾千萬次)。 通過取views的對數,然後取這個對數值的四次方根並線性縮放經過四次方的結果,我們得到了一些在所需範圍內並且有點呈現鐘形曲線的東西。

上圖中(左一)維基百科頁面瀏覽量分佈高度偏斜,資料範圍較大。 左二途展示了可以通過使用對數、冪函數和連續線性縮放轉換view number來解決問題。 第三個圖顯示直方圖均衡化的效果,第四個圖則顯示 Box-Cox 轉換的效果。
設計一個使分佈看起來像鐘形曲線的線性化函數可能很困難。 一種更簡單的方法是將視圖數量bucketize,選擇bucket邊界以適合所需的輸出分佈。 選擇這些bucket的原則方法是進行直方圖均衡化(histogram equalization),其中直方圖的bucket是根據原始分佈的分位數選擇的(如上圖 左三)。 在理想情況下,直方圖均衡會導致均勻分佈(儘管在這種情況下並非如此,因為分位數中有重複值)。
另一種處理分布高度偏斜的技術是使用 parametric transformation,例如 Box-Cox 轉換。Box-Cox 選擇其單個參數 lambda 來控制“異方差性(heteroscedasticity)”,以便方差不再取決於幅度(magnitude)。 在這裡,很少查看的維基百科頁面之間的差異將遠小於經常查看頁面之間的差異,Box-Cox 試圖在所有查看次數範圍內均衡差異。
矩陣型數字(Array of numbers)
我們有時遇到的輸入資料會是矩陣型的數字。假設矩陣內的數字是固定長度,資料的呈現就相對簡單: flatten這個矩陣並將每個position視為一個單獨的feature。不過通常的狀況都是矩陣是非固定的。例如,我們一樣要預測科幻小說的銷售數量,這一次的input則是擁有相同主題其他小說的歷史銷售量。假設資料如下:
[3100, 16500, 270000, 2000, 100, 769330]
很顯然我們看到這個array中的每個value差異很大。我們會用一些常見慣用語來處理array of numbers,包含如下:
- 根據批量統計資料呈現input array。 例如,我們可能會使用長度(即之前關於該主題的書籍的數量)、平均值、中位數、最小值、最大值等。
- 根據經驗分佈呈現input array — — 即,按第 10/20/… 百分位數,依此類推。
- 如果array 以特定方式排序(例如,按時間或大小排序),則按最後三個或其他固定數量的項目呈現input array 。
所有這些最終都將可變長度的資料array 呈現為固定長度的特徵。 我們也可以將這個問題描述為時間序列預測問題,即根據前一本書的銷售時間歷史預測該主題下一本書的銷量的問題。 通過將以前書籍的銷量視為array input,我們假設預測一本書銷量的最重要因素是書籍本身的"特徵"(例如:作者、出版商、評論等),而不是帶有著時間連續性的銷售總額。
分類輸入(Categorical Inputs)
現代化且大規模的ML模型(隨機森林樹,SVM,神經網路)都是數字類的value,所以分類式的資料也必須用數字來代替。
簡單地列舉可能的Value並將它們映射到一個ordinal scale將會處理得很差。 假設預測科幻小說類書籍銷量的模型的inpute之一是這本書的語言版本。 我們不能就這樣建立這樣的mapping table(如下圖):
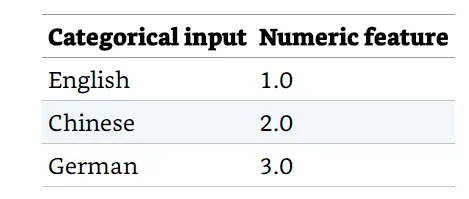
這是因為ML模型會嘗試在德語和英語書籍的受歡迎度之間進行插值(interpolate),以獲得中文書籍的受歡迎度。因為語言之間沒有序數(ordinal)關係,我們需要將分類對映到數字,讓模型能夠獨立學習用這些語版本書籍的市場。
One-hot encoding
在確保變量(variables)獨立的同時對映分類變量的最簡單方法是one-hot encoding。 在我們的下面的範例中,分類輸入變量將使用以下對映為三個元素特徵向量:
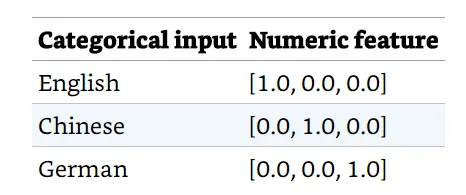
One-hot encoding 要求我們事先要知道分類輸入的詞彙表。 在這裡,詞彙表由三個標記(英語、中文和德語)組成,生成的特徵的長度就是這個詞彙表的大小。
Dummy coding or One-hot encoding?
技術上,兩個元素的特徵向量也足夠呈現我們的範例,如下圖:
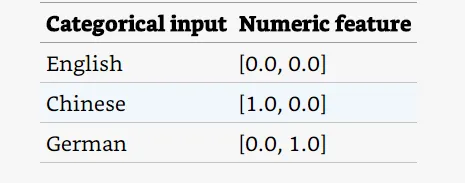
這個方式稱為Dummy coding,因為dummy coding是一種更嚴謹的呈現,所以當input是無關線性時,它在效能更好的統計模型中是首選。 然而,現代ML演算法並不要求它們的input是無關線性,而是使用 L1 正則化等方法來修剪redundant inputs。 額外的自由度允許框架透明地將真實環境中missing input都視為零的資料,因此許多ML框架通常只支援one-hot encoding
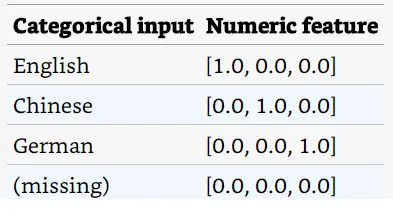
在某些情況下,將分類型資料看成是數字型資料並對映到one-hot encoding column是有幫助的:
當數字型的input是一個index時
例如,如果我們試圖預測交通流量並且我們的inputs之一是一周中的星期幾,我們可以將星期幾視為數字 (1, 2, 3, …, 7),但它有助於認識到這裡的星期幾不是連續的數字,而實際上只是一個index。 所以最好將其視為分類(星期日、一、……、六),因為index是arbitrary。 一周應該從星期日(如美國)、星期一(如台灣)還是星期六(如埃及)為開始?
當input與label之間的關係是不連續的
將星期幾作為分類特徵的評估應該傾向的是周五的交通流量不受週四和周六的影響。
當對數字變量(variable)進行bucket是有利的時
在大多數的城市,交通流量變化分界在於是不是處在周末的時間,而且每個城市的狀況還可能不一樣(有些週六日算周末,有些可能是週四跟周五 — 像是伊斯蘭國家)。這種是不是周末或不是周末的分別,很適合用boolean feature。這種不同input的數量(此處為 7)大於不同特徵值的數量(此處為 2)的映射稱為bucketing。 通常,bucketing是根據range進行的 — — 例如,我們可能將 母親的年齡分入在 25、30、35等處中斷的範圍,並將這些 bin 中的每一個都視有分類的,但我們要意識到這樣做等於失去了ordinal性質的母親的年齡。
當我們想要將數字的input的不同value視為獨立時,當它們對label產生影響時。
例如,嬰兒的體重取決於分娩的次數,因為雙胞胎和三胞胎的體重往往低於一胎。 因此,如果是三胞胎的一部分,體重較輕的嬰兒可能比體重相同的雙胞胎嬰兒更健康。 在這種情況下,我們可以將複數對映到一個分類變量,因為分類變量允許模型為複數的不同value學習獨立的可調參數。 當然,只有在我們的資料集中有足夠多的雙胞胎和三胞胎的資料時,我們才能做到這一點。
分類型變量的陣列(array)
我們之前提到陣列的資料長度通常是多變的。如果我們有一個陣列來呈現母親生產的方式
[Induced, Induced, Natural, Cesarean]
而通常我們常用來處理分類型變量陣列的資料如下:
- 計算每個詞彙item的出現次數。 因此,假設詞彙是誘導(Induced)、自然(Natural)和剖腹產(Cesarean)(按此順序),我們範例資料的呈現將是 [2, 1, 1]。 現在這是一個固定長度的數字array,可以按位置順序攤平和使用。 如果我們有一個array,其中一個item只能出現一次(例如,一個人說的語言),或者如果該特徵僅表示"是或不是"而不是計算它(例如母親是否曾經做過剖腹產手術),那麼計算每個位置為 0 或 1,這稱為multi-hot encoding。
- 為避免大的數字,可以使用相對頻率代替計數。 我們範例資料的呈現將是 [0.5, 0.25, 0.25] 而不是 [2, 1, 1]。 Empty arrays(沒有兄弟姐妹的第一個出生的新生而)表示為 [0, 0, 0]。 在自然語言處理中,單詞(a word)的整體相對頻率通過包含該單詞的文件的相對頻率進行歸一化,以產生 TF-IDF(first-born babies with no previous siblings)。 TF-IDF 反映了一個詞(word)對於文件的唯一性。
- 如果array以特定方式(例如,按時間順序)排序,則通過最後三個項目呈現input array。 少於三個的array用missing values代替。
- 通過批量統計來呈現array,例如array的長度、眾數、中位數、第 10/20/… 百分位數等。
其中,counting/relative-freqency慣用語是最常見的。 請注意,這兩個都是 one-hot encoding的一般化(generalization) — — 如果新生兒沒有哥哥姐姐,則表示將是 [0, 0, 0],如果新生兒有一個自然出生的哥哥姐姐, 表示將是 [0, 1, 0]。 看過簡單的資料呈現後,將有助於我們討論資料呈現的設計模式。
設計模式一: Hashed Feature
Hashed feature設計模式主要為了解決三種分類特徵的可能問題,分別是: incomplete vocabulary,基於cardinality導致的模型大小,還有cold start.它通過對分類特徵進行分群並在資料呈現中接受衝突的取捨來實現。
Problem
對分類輸入變量進行one-hot encoding需要事先知道詞彙表(vocabulary)。如果輸入變量類似於一本書所用的語言或預測交通流量的星期幾,那這不會是問題。
如果所討論的分類變量是嬰兒出生地的醫院 ID (hospital_id)或接生嬰兒的醫生的 ID(physician_id) 之類的東西怎麼辦?這樣分類變量就會出現以下的問題:
- 需要從訓練資料集提取詞彙表。但因為資料會隨機抽樣,它非常有可能無法得知全部可能的醫院ID與醫生的ID。這樣詞彙表就不會完整。
- 分類變量具有high cardinality。 我們擁有長度從數千到數百萬的特徵向量,而不是只具有上述範例的三種語言或 7 天的特徵向量。 這樣的特徵向量在實作中會帶來幾個問題。 它們涉及的權重(weights)太多,以至於訓練資料可能不足。 即使我們可以訓練模型,訓練後的模型也需要大量空間來存儲,因為在模型在運作時需要整個詞彙表。 因此,我們可能無法在較小的設備上部署這個模型。
- 模型進入生產環境後,新的醫院會建立且新的醫生也會被雇用。而我們模型不會知道這些事並且能夠預測它,而處理這一類的問題就要把它分成另一個服務的基礎架構,例如cold start problems。
作為一個具體的例子,讓我們以預測航班到達延誤的問題為例。 模型的輸入之一是出發機場。 在收集資料集時,美國有 347 個機場:
SELECT
DISTINCT(departure_airport)
FROM ‘bigquery-sample.airline_ontine_data.flights’
一些機場在整個時間段內只有一到三個航班,因此我們預計訓練資料詞彙將不完整。 347 足夠大,這個feature將非常稀疏(spare),而且肯定會建造新機場。 如果我們對出發機場進行one-hot encoding,所有三個問題(incomplete vocabulary、high cardinality、cold start)都會存在。
解決方案
Hashed Feature 設計模式通過執行以下操作來呈現分類輸入變量:
- 將分類輸入轉換為唯一字串(string)。 對於出發的機場,我們可以使用機場的IATA 代碼(三個字母)。
- 對字串(string)調用確定性(沒有random seeds或salt)和portable(以便可以在訓練和正式環境中使用相同的演算法)hashing演算法。
- 當hash result除以所需的bucket數量時取餘數。 通常,hash 演算法返回一個可以為負的整數,而負整數的模數(modulo)為負。 因此,取結果的絕對值。
例如,下表範例是一個在一些IATA airport codes使用FarmHash演算法,而我們將這些資料分成三種的bucket分類,別分是3,10,1000個buckets。

為何這樣是有效的
假設我們使用10 buckets來進行hash airport code(如上圖)。這如何解我們的問題呢?
詞彙表之外的input
即使少數的航班資料沒有在訓練資料集中,其feature value仍會被hash 成0–9之間的數字。因此,在運作期間就沒有彈性問題(resilience problem) — 未知的機場將會得到與其他機場相對應的預測。這樣模型就部會出錯。
我們的機場數量有347個,而我們將它們分別丟到10個bucket,平均每個bucket會有35個機場數量。訓練資料集中缺少的機場資料將從hash bucket中其他類似的 35 個機場資料借用其feature。 當然,對模型沒看過的機場資料的預測不會是準確的(期望對未知輸入進行準確預測是不合理的),但它會在正確的"範圍"內。
通過平衡合理處理詞彙表外的input需要和模型準確反映分類輸入的需求來選擇hash bucket的數量。 使用 10 個hash bucket,35 個機場廖被混合。 一個好的經驗法則是選擇hash bucket的數量,使每個bucket獲得大約五個entries。 在這種情況下,這意味著 70 個hash buckets是一個很好的折衷方案。
High cardinality
很容易看的出來只要我們選擇足夠少的hash buckets, High cardinality問題就可以解決。 即使我們有數百萬個機場、醫院或醫生,我們也可以將它們打散到幾百個bucket中,從而使系統的memory和modles大小是實際可運行的。
我們不需要存儲整個詞彙表,因為轉換代碼(airports轉換成三碼的code)與實際資料值無關,並且模型的核心只處理buckets inputs,而不是完整詞彙表。
hash確實是鬆散的(loosy) — — 因為我們有 347 個機場,如果我們將它散在 10 個 bukcets,平均有 35 個機場資料會得到相同的hash bucket code。 但是,當由於變量(variable)太寬而丟棄變量時,loosy encoding是一種可以接受的折衷方案。
Cold Start
cold start的情況類似詞彙表之外的狀況。假如一個新的機場資料進到系統中,它將獲得相同的hash bucket code,它最初將獲得與hash bucket中其他機場資料對應的預測。 隨著某個機場變得越來越熱門,將會有更多的航班從該機場起飛。 只要我們定期保留模型,它的預測就會開始反映新機場的抵達/延誤。 我們會在其他文章中有更詳細的討論。
通過選擇hash bucket的數量,使每個bucket獲得大約五個entries,我們可以確保任何bucket都有合理的初始結果。
取捨(trade-off)與替代
絕大部分的設計模型都會某些的trade-off,而hash feature的設計模式也不例外。有些trade-off會讓我們失去模型的準確性。
Bucket collision
Hashed Feature implementation的modulo部分是lossy operation。 通過選擇 100個 bucket大小,我們選擇讓 3–4 個機場資料共用一個bucket。 我們明確地妥協了準確呈現資料的能力(使用固定的詞彙表和one-hot encoding),以處理 out-of-vocabulary input、cardinality/模型大小限制 和cold-start問題。 天下沒有白吃的午餐。 如果事先知道全部的詞彙表,表示這裡的詞彙量相對較小(對於具有數百萬筆的資料集來說,數以千計是可以接受的),並且如果cold-start不是問題,請不要選擇Hashed Feature。
需要注意的是,我們不能簡單地將bucket的數量增加到非常高,以期待完全避免衝突。 即使我們在只有 347 個機場的情況下將bucket的數量提高到 100,000,至少會有兩個機場共享同一個bucket的概率也是 45% (如下圖)。 因此,只有在我們願意容忍共享相同hash bucket value的多個分類輸入時,我們才應該使用hashed feature。

偏斜(Skew)
當分類輸入的y 資料分佈高度偏斜時,準確性的損失尤其嚴重。 考慮包含 ORD(芝加哥機場的代號) 的hash bucket的情況。 我們可以使用以下方法找到它(以下是在GCP使用GibQuery的範例):

經過運算後,整個資料集大概會有從三千六百萬筆(如下圖)從芝加哥出發的航班,第二名則是從BTV(佛蒙特州的伯靈頓)出發:
資料表明,出於所有實際目的,該模型會將芝加哥推算出長時間出租車和天氣延誤歸因於佛蒙特州伯靈頓的市政機場! BTV 和 MCI(堪薩斯城機場) 的模型精度會很差,因為有很多航班從芝加哥起飛。

聚合特徵(aggregate feature)
在分類變量的分佈偏斜或bucket的數量太少以至於bucket collisions頻繁的情況下,我們可能會發現將聚合特徵作為輸入加入到我們的模型中是很有幫助。 例如,對於每個機場資料,我們可以在訓練資料集中找到準點航班的概率,並將其作為特徵加入到我們的模型中。 這使我們能夠避免在對機場代碼進行hash處理時遺失與各個機場相關的資訊。 在某些情況下,我們可能需要完全避免使用機場名稱作為特徵,因為準點航班的相對頻率可能就足夠了。
超參數調整(Hyperparameter tuning)
由於bucket collision頻率的trade-off,bucket數量到底要怎麼選擇可能很困難。 但它通常取決於問題本身。 因此,我們建議將bucket的數量視為經過調整的超參數:

Cryptographic hash
使Hashed Feature lossy的是實現的modulo部分。如果我們要完全避免modulo怎麼辦?畢竟farm figerprint是固定長度的(一個INT64-64 bits),所以可以用64個feature value來表示,每個value都是0或1,這就是所謂的二進制編碼(binary encoding)。但是,二進制編碼並不能解決out-of-vocabulary或cold start的問題(僅解決High cardinality的問題)。事實上,bitwise coding是一個red herring。如果我們不做modulo,我們可以通過對構成 IATA 代碼的三個字串進行編碼來獲得唯一值的資料呈現(因此使用長度為 3* 26 = 78 的特徵)。這種資料呈現的問題很明顯:名稱以字母 O 開頭的機場在航班延誤特徵方面沒有任何共同點 — — 編碼在以相同字母開頭的機場之間產生了”虛假(spurious)”的相關性。同樣的見解也適用於二進制。因此,我們不建議對farm fingerprint values進行二進制編碼。
MD5 hash的二進制編碼不會受到這種虛假相關問題的影響,因為 MD5 hash的output是均勻分佈的,因此resulting bits將均勻分佈。但是,與 Farm Fingerprint 演算法不同的是,MD5 hash不是確定性的,也不是唯一的 —它是一種單向hash,會發生許多意外的collisions。
在Hased feature設計模式中,我們必須使用fingerprint hash演算法而不是cryptographic hash演算法。 這是因為fingerprint function的目標是產生確定性和唯一性的value。 如果我們能夠仔細想一下,這是ML中preprocessing function的一個關鍵要求,因為我們需要在模型使用期間使用相同的function會得到相同的hash value。 fingerprint function不會產生均勻分佈的輸出。 但MD5 或 SHA1 之類的加密演算法確實會產生均勻分佈的輸出,但它們不是確定性的,而且這種加密計算會使我們電腦運算的成本很高。 因此,cryptographic hash在特徵工程context中是不可用,其中預測期間為特定輸入計算的hash value必須與訓練期間計算的hash value相同,並且hash function不應減慢ML模型的速度。
操作的順序
我們需要先執行modulo,然後才是絕對值:

上面程式中 ABS、MOD 和 FARM_FINGERPRINT 的順序很重要,因為 INT64 的範圍是不對稱。 具體來說,它的範圍在 –9,223,372,036,854,775,808 和 9,223,372,036,854,775,807 之間。 所以,如果我們要這樣做:
ABS(FARM_FINGERPRINT(airport))
如果 FARM_FINGERPRINT operation正好返回 -9,223,372,036,854,775,808,我們將遇到罕見且可能無法重現的overflow error,因為它的絕對值無法使用 INT64 表示。
Empty hash buckets
儘管可能性很小,但即使我們選擇 10 個hash bucket來代表 347 個機場,其中一個hash bucket是空的可能性很小。 因此,當使用hashed feature columns時,使用 L2 正則化可能是有效益的,這樣與空的bucket相關的權重將被推到接近零。 這樣,如果out-of-vocabulary的機場資料真的跑到空的bucket中,則不會導致模型在數值上變得不穩定。
設計模式二: Embeddings
Embedding是一種可學習的資料呈現,它以保留與學習問題相關的資訊的方式將High-cardinality資料映射到低維度空間。 Embedding是現代機器學習的核心,並且在該領域有各種化身。
Problem
ML 模型系統地尋找資料中的模式,以捕捉模型輸入特徵的屬性與輸出標籤的關係。 因此,輸入特徵的資料呈現直接影響最終模型的品質。 雖然處理結構化的數字輸入相對簡單,但訓練 ML 模型所需的資料匯市各式各樣的,例如分類特徵、text、圖像、音頻、時間序列等等。 對於這些資料呈現,我們需要一個有意義的數字值來提供給我們的 ML 模型,以便這些特徵可以適合典型的訓練範例。 Embedding提供了一種處理這些不同資料類型的方法,這種方式可以保留Item之間的相似性,從而提高我們的模型學習這些基本模式的能力。
one-hot encoding是呈現分類輸入變量的常用方法。 例如,考慮新生兒出生資料集(這是在GCP Bigquery一個公開的資料集)中的多個input。 這是一個分類輸入,有六個可能的值:[‘ Single( 1)’, ‘Multiple( 2 +)’, ‘Twins( 2)’, ‘Triplets( 3)’, ‘Quadruplets( 4)’, ‘Quintuplets( 5)’].我們可以使用 one-hot encoding處理這個分類輸入,這個encoding將每個潛在的輸入字串值映射到 R Squares中的單位向量,如下圖所示

當以這種方式編碼時,我們需要六個維度來表示每個不同的類別。 六個維度感覺不是那麼糟糕,但是如果我們有很多很多類別要考慮呢?
例如,如果我們的資料集由客戶對我們vidoe資料庫的觀看歷史組成,而我們的任務是根據客戶之前與video 的interaction建議新的 video list,該怎麼辦? 在這種情況下,customer_id entries可能有數百萬個unique entries。 相同的,以前觀看過的video的 video_id 也可能包含數千個entries。 One-hot encoding 的High-cardinality分類特徵(如視video ID 或customer ID)作為 ML 模型的input會導致sparse maxtrix不適用於許多 ML 算法。
one-hot encoding的第二個問題是它將分類變量視為”獨立的”。 然而,雙胞胎的資料呈現應該接近三胞胎的資料呈現,而與五胞胎的資料呈現相去甚遠。 倍數(multiple)很可能是雙胞胎,但也可能是三胞胎。 例如,下圖顯示了在較低維度中多個 column的替代呈現(alternate representation),它擷取到了這種密切關係。

這些數字當然是任意的。 但是,對於出生問題,是否可以僅使用兩個維度來學習plurality column的最佳呈現? 這就是 Embeddings 設計模式解決的問題。
同樣的High cardinality和dependent data的問題也出現在images和texts中。 imagea由數千個像素組成,它們之間不是相互獨立的。自然語言text是從數千個單詞的text中的一個詞彙中提取的,像walk這樣的單字更接近單字run而不是單字book。
解決方案
Embedding設計模式通過將input data傳遞到具有可訓練權重(weight)的Embedding layer來解決在較低維度上密集的呈現High ccardinality資料的問題。 這會將高維度的分類輸入變量映射到某個低維空間中的real-valued vector。 創建密集呈現的權重作為模型優化的一部分進行學習(如下圖)。 實際上,這些Embedding最終會擷取input data中的密切關係。

小提示
因為Embedding在低維表示中擷取inout data中的密切關係,我們可以使用Embedding layer作為clustering techniques(例如客戶分群)和降維方法(如PCA-principal components analysys)的替代品。 Embedding權重在主要模型訓練loop中會被決定,因此無需事先進行clustering或進行 PCA。
在訓練出生模型時,Embedding layer中的權重將作為梯度下降(gradient descent)過程的一部分進行學習。在訓練結束時,Embedding layer的權重可能是分類變量的編碼(如下圖所示)

Embedding將一個sparse的one-hot encoding向量映射到 R square中的密集(dense)向量。在 TensorFlow 中,我們首先為該特徵構建一個分類特徵column,然後將其包在一個Embedding feature column中。 例如,對於我們的plurality feature,我們將有:

生成的feature column(plurality_embed)被用作神經網絡下游模式的input,而不是one-hot encoded的feature column。
Text embeddings
Text 提供了一個natural setting,使用Embedding layer是有利的。 鑑於詞彙表的cardinalty(通常在數萬個單詞的量級),對每個單詞進行one-hot encoding是不切實際的。 這將創建一個非常大(高維度)和sparse的訓練矩陣。 此外,我們希望相似的詞在Embedding space中的Embeddings很近,而不相關的詞在Embedding space中是相互遠離。 因此,在傳遞給我們的模型之前,我們使用dense word embedding來向量化discrete text input。
為了在 Keras 中實現text embedding,我們首先為詞彙表中的每個單詞創建一個標記化(tokenization),如下圖所示。 然後我們使用這個標記化來對映到一個Embedding layer,類似於plurality column的處理方式。

標記化是一種查找表(lookup table),它將詞彙表中的每個單詞對映到index。 我們可以將其視為每個單詞的 one-hot encoding,其中tokenized index是 one-hot encoding中non-zero element的位置。 這需要完整跑一遍整個資料集以創建查找表,並且可以在 Keras 中完成。

這裡我們可以使用keras library中的Tokenizer class。 對fit_on_texts的呼叫創建了一個查找表,將在我們的title中找到的每個單詞對映到一個index。 通過呼叫tokenizer.index_word,我們可以直接查看這個查找表。

然後,我們可以使用標記器(tokenizer)的 texts_to_sequences 方法呼叫這個mapping。 這將被呈現的text input中的每個單詞序列(這裡,我們假設它們是文章的標題)對映到與每個單詞相對應的標記序列,如下圖所示:

Tokenizer包含我們稍後將用於創建Embedding layer的其他相關資訊。 特別是,VOCAB_SIZE 擷取index lookup table的elements數量,MAX_LEN 包含資料集中text字串的最大長度:

在建立模型之前,需要對資料集中的title進行預處理。 我們需要將充填title的elements來輸入到模型中。 Keras 在 tokenizer method的最上層有helper function pad_sequence 。 函數 create_sequences 將title和最大長度的句子作為input,並返回與傳遞給最大長度句子的token相對應的整數列表(list of the integers):

接下來,我們將在 Keras 中構建一個深度神經網絡 (DNN) 模型,該模型實現了一個簡單的Embedding layer以將單詞整合到一個密集向量(dense vector)。 Keras Embedding layer可以被認為是從特定單詞的整數索引到密集向量的對映。 Embedding的維度由 output_dim 決定。 參數 input_dim 表示詞彙的大小, input_shape 表示輸入序列的長度。 由於在這裡我們在傳遞給模型之前充填了title,我們設定

我們需要在嵌Embedding layer和dense softmax layer之間放置一個自定義的 Keras Lambda layer,以平均Embedding layer返回的word vectors。 這是fed到dense softmax layer的平均值。 通過這樣做,我們建立了一個簡單但loses information 詞彙順序的模型,建立一個將句子視為“詞袋(bag of words)”的模型。
Image embedding
雖然text處理非常稀疏(sparse)的輸入,但其他資料類型(例如圖片或音頻)由密集的高維度向量所組成,通常具有包含原始像素(pixel)或頻率信息的多個channels。 在這種情況下,Embedding會擷取input的相關低維度的呈現。
對於image embedding,複雜的卷積神經網絡CNN(如 Inception 或 ResNet)首先在大型圖片資料集(如 ImageNet)上進行訓練,該資料集包含數百萬張圖片和數千個可能的分類標籤。 然後,從模型中刪除最後一個 softmax layer。 如果沒有最終的 softmax layer classifier,該模型可用於為特定輸入提取特徵向量。 這個 特徵向量包含圖片的所有相關信息,因此它本質上是input image的低維embedding。
類似地,如果要把圖片配上字幕,即生成給定圖片字幕,就會如下圖所示

通過在大量圖片/字幕的資料集上訓練此模型架構,編碼器(encoder)學習了圖片的有效向量呈現。 解碼器(decoder)學習如何將此向量轉換為Text標題。在這個意義上,編碼器成為Image2Vec embedding machine。
為何它是有效的
Embedding layer只是一個在神經網路中的另一個hidden layer。然後將權重與每個High-cardinality維度相關聯,output通過網路的其餘部分。因此,創建Embedding的權重是通過梯度下降過程中學習的,就像神經網路中的任何其他權重一樣。這意味著由此產生的vector embedding呈現了這些feature value相對於learning task的最有效率的低維度呈現。
雖然這種改進的Embedding最終有助於模型,但Embedding本身俱有內在價值,並允許我們對資料集有更多的了解。
讓我們再看一次客戶video資料集。通過僅使用 one-hot encoding,任意兩個獨立的用戶 user_i 和 user_j 將具有相同的相似性度量。 同樣的,對於出生時新生兒為複數的任何兩個不同的六維度一one-hot encoding的點積或餘弦相似度將具有零相似度。 這是有道理的,因為 one-hot encoding 本質上是告訴我們的模型將任何兩個不同的出生時新生兒為複數視為獨立且不相關的。 對於我們的客戶和影片觀賞資料集,我們遺失了客戶或影片之間的任何相似性概念。 但這感覺不太對。 兩個不同的客戶或影片可能確實有相似之處。 出生時新生兒為複數也是如此。 四胞胎和五胞胎的出現可能以統計上相似的方式影響出生體重,而不是單一新生兒出生體重(見下圖)。

當計算多個類別的相似度作為 one-hot encoding向量時,我們得到單位矩陣,因為每個類別都被視為一個不同的特徵(如下圖)

然而,一旦將複數性嵌入到兩個維度中,相似性度量就變得不重要了,不同類別之間的重要關係就會出現(如下圖)

因此,learned embedding允許我們提取兩個獨立類別之間的內在相似性,並且在特定數字向量呈現的情況下,我們可以精確地量化兩個類別特徵之間的相似性。
這很容易用 natality 資料集進行視覺化,但在處理嵌入 20 維空間的 customer_ids 時,同樣的原則也適用。 當使用我們的客戶資料集時,embedding允許我們檢索給特定 customer_id 相似的客戶,並根據相似性提出建議,例如他們可能會觀看哪些影片,如下圖 所示。 此外,在訓練單獨的ML模型時,這些用戶和item embedding可以與其他特徵相結合。 在ML模型中使用已經訓練好的embedding被稱為transfer learning。

取捨與替代方案
使用Embedding的主要取捨是資料間的妥協呈現。 從High-cardinality 呈現到低維呈現都會遺失一些資訊。 作為回報,我們獲得了關於資料與資料間的接近度和context的資訊。
Embedding 維度的選擇
Embedding space 的確切維度是我們作為ML學習工作者所需要選擇的。 那麼,我們應該選擇大的Embedding dimension還是小的? 當然,與ML中的大多數事情一樣,有一個取捨。 資料呈現的損失(lossiness)由Embedding layer的層數來控制。 通過選擇一個非常小的Embedding layer的輸出維度,太多的資訊會被迫進入一個小的向量空間,背景資料(context)可能會遺失。 另一方面,當Embedding dimension太大時,Embedding 失去了學習到的特徵的背景資料重要性。 在極端情況下,我們又回到了 one-hot emcoding遇到的問題。 最佳Embedding dimension通常是通過實找到的,類似於選擇深度神經網路層中的神經元數量。
如果我們訓練模型的時間不夠,一個經驗法則是使用唯一類別元素(elements)總數的四次方根,而另一個Embedding dimension應該大約是類別中唯一元素數量平方根的 1.6 倍 ,並且不少於 600。例如,假設我們想使用Embedding layer對具有 625 個唯一值的特徵進行編碼。 使用第一條經驗法則,我們會選擇 5 個的Embedding dimension,使用第二條經驗法則,我們會選擇 40。如果我們正在進行超參數(hyperparameter)調整,它可能值得在這個範圍內搜索。
自動編碼器(Autoencoders)
以監督方式訓練embedding可能很困難,因為它需要大量labeled data。 為了使像 Inception 這樣的image分類模型能夠產生有效的image embedding,它是在 ImageNet 上訓練的,它有 1400 萬張labeled image。 Autoencoder提供了一種方法來解決對大量labeled資料集的這種需求。
典型的自動編碼器架構,如下圖 所示,由一個bottleneck layer組成,它本質上是一個embedding layer。 bottleneck之前的網路部分(“encoder”)將高維度input map到低維度embedding layer,而後一個網路(“decoder”)將這種資料呈現map回更高維度,通常相同維度為原始大小。 該模型通常在reconstruction error的某個variant上進行訓練,這迫使模型的output盡可能與input相似。

因為input與output相同,所以不需要額外的label。encoder學習input的最佳的非線性降維。類似於 PCA 如何實現線性降維,autoencdoer的bottleneck layer能夠通過embedding獲得非線性降維。
這使我們能夠將困難的 ML 問題分為兩部分。首先,我們使用所有沒有label的資料,通過使用autoencoder作為auxiliary learning task,從High cardinality到lower cardinality。然後,我們使用auxiliary learning task產生的embedding來解決實際圖片分類問題,對於這種問題,我們通常具有更少的labeled data。這可能會提高模型效能,因為現在模型只需要學習低維度的權重(例如,它必須學習更少的權重)
除了image autoencoder,最近的工作重點是將學習技術應用於結構化資料。 TabNet 是一種深度神經網路,專門設計用於從表格式資料中學習,並且可以在unsupervised管理中進行訓練。通過修改模型以具有encoder-decoder結構,TabNet 可用作表格式資料的autoencoder,這允許模型通過feature transformer從結構化資料中學習embedding。
上下文語言模型(Context language models)
是否有適用於文本(text)的auxiliary learning task? 上下文語言模型,如 Word2Vec與masked language models,如Bidirectional Encoder Representations from transformers(BERT)將語言工作變成了一種ML問題,因此在text中,leabel是一大堆的。
word2Vec 是一種眾所周知的方法,它使用淺層神經網路構建Embedding,並結合了兩種技術 — — Continuous Bag of Words (CBOW) and skip-gram model— — 應用於大型文本庫,例如維基百科。 雖然這兩個模型的目標都是通過使用中間的embedding layer將inpit word(s) mapping到target word(s)來學習單一詞彙的上下文,但實現了一個輔助目標,即學習最能捕捉上下文的低維度Embedding 。 通過 Word2Vec 學習到的結果詞彙擷取了詞彙之間的語義關係,以便在embedding space中的向量呈現並保持有意義的距離和方向性(如下圖)。

BERT 使用masked的語言模型和下個一語句預測進行訓練。 對於masked語言模型,從文章中隨機mask單個詞彙,模型去猜測蓋掉的單一詞彙是什麼。 下一句的預測是一種分類(classification)任務,其中模型預測原文中兩個句子是否接連在一起。 所以任何文章資料庫都適合作為被label資料集。 BERT 最初接受了所有英語維基百科和書庫的訓練。 儘管在這些是輔助任務(auxiliary tasks)上學習,但當用於其他下游訓練任務時,來自 BERT 或 WOrd2Vec 的learned embedding已被證明非常強大。 word2vec 的word embedding learned與word appears的句子是無關。 然而,BERT word ebedding的上下文相關的,這意味著embedding vector是不同的,這具體取決於單一詞彙在整段文章被使用的方式。
可以將預先訓練好的text embedding(如 word2vec、NNLM、GLoVE 或 BERT)加入到ML模型中,以結合結構化input以及來自客戶和影片資料集的其他learned embedding來處理text features(如下圖)。
最終,embedding learn保留與規定的訓練任務相關的資訊。 在圖片字幕的情況下,任務是了解圖片與text相關時element的上下文。 在autoencoder架構中,label與feature相同,因此bottleneck的降維嘗試學習所有沒有重要內容的特定上下文。

Embedding in a data warehouse
結構化資料如果要做 ML 最好直接在Data warehouse上的 SQL 中執運作。 這避免了將資料導出warehouse,並mitigate資料隱私和安全問題。
然而,許多問題需要將結構化資料和自然語言文本或圖片資料都混在一起。 在Data warehouse中,自然語言文本(如評論)被直接排序為columns,圖片通常作為 URL 存儲在cloud storage 的bucket中。 在這些情況下,它簡化了後面的 ML作業,以額外存儲text columns或images的embedding作為array-type columns。 這樣做將能夠將此類非結構化資料合併到 ML 模型中。
要建立text embedding,我們可以將預先訓練好的模型(例如 Swivel)從 TensorFlow Hub load到 Bigquery。(範例語法如下)
CREATE OR REPLACE MODEL advata.swivel_text_embed
OPTIONS(model_type = ‘tensorflow’, model_path=’gs://bucket/swivel/*’)
然後,使用模型將自然語言text column轉換為embedding array,並將embedding lookup存儲到新的tbale中:

現在可以加入這個table以獲取任何評論的text embedding。 對於image embeddings,我們可以類似地將圖片 URL 轉換為embedding並將它們load到data warehouse中。
設計模式三: Feature Cross
Feature cross設計模式通過明確地將input value的每個組合作為單獨的特徵來幫助模型更快地學習input資料之間的關係。
問題
下圖 中的資料集以及建立一個用於分隔 加號和 減號label的二元分類器(binary classifier)的作業。 僅使用 x_1 和 x_2 坐標,不可能找到分隔加號和減號的linear boundary。 這意味著要解決這個問題,我們必須使模型更複雜,也許是向模型加上更多的layer。 其實有更簡單的解決方案。

解決方案
在ML領域中,Feature engineering是使用domain knowledge來建立一個新的feature,而這個新的feature有助於ML學習並提高模型預測能力。 一種常用Feature engineering的技術是建立feature cross。
feature cross是通過連接兩個或多個categorical feature以擷取它們之間的interaction而形成的synthetic feature。 通過以這種方式連接兩個feature,可以將非nonlinearity encode到模型中,這可以實現超出每個特徵單獨提供的預測能力。 feature corss提供了一種讓 ML 模型更快地學習特徵之間關係的方法。 雖然像神經網路和tree這樣更複雜的模型可以自己學習feature cross,但明確地使用feature cross可以讓我們擺脫只訓練線性模型的麻煩。因此,feature cross可以加速模型訓練(成本更低)並降低模型複雜性(只需要少許的訓練資料)。
為了為上圖的資料集建立一個feature column,我們可以將 x_1 和 x_2 分別分成兩個bucket,具體取決於它們的符號。 這將 x_1 和 x_2 轉換為categorical features。 讓 A 表示為x_1 > = 0 的bucket,B 表示為x_1 < 0 的bucket。讓 C 表示為 x_2 > = 0 的bucket,D 表示為 x_2 < 0 的bucket

上圖的feature cross 會讓我們產生四個新的boolean features在我們的models:
AC where x_1 ≥ 0 and x_2 ≥ 0
BC where x_1 < 0 and x_2 ≥ 0
AD where x_1 ≥ 0 and x_2 < 0
BD where x_1 < 0 and X-_2 < 0
當在訓練模型時,上面四個的每個boolean features都有它各自的權重。這意味著我們可以將每個象限視為自有的feature。 由於原始資料集被我們建立的bucket完美的分割,A 和 B 的feature cross能夠線性地分離資料集。 但這只是一個例證。哪麼真實世界的數據呢? 讓我們以紐約市計程車的公共資料集(在Bigquery的public dataset)為例(如下圖)


該資料集包含紐約市計程車搭乘資訊,包括接送的timestamp、上下車地點(經緯度)以及乘客人數等feature。 這裡的標籤是 fare_amount,搭小黃的費用。 而哪些feature cross可能與此資料集相關?可能有很多。 讓我們考慮pickup_datetime這一個feature。 通過這個feature,我們可以看到計程車每周被搭乘的天數與小時。 這些中的每一個都是一個cateforical variable,當然兩者都包含確定計程車價錢的預測能力。 對於此資料集,考慮 day_of_week 和 hour_of_day 的featire cross是有意義的,因為可以合理地假設週一下午 5 點的小黃使用量應與週五下午 5 點的小黃分開來看(如下圖)

這兩個feature組成的feature cross會組成一個有168個維度的one-hot encoded vector(24小時 x 7天 = 168),例如星期一下午五點。使用一個單一index來呈現(day_of_week 是星期一,hour_of_day是17)。
雖然這兩個feature本身很重要,但允許 hour_of_day 和 day_of_week 的featire cross使計程車車資預測模型更容易識別週末高峰時間影響計程車乘坐時間,從而再影響回計程車車資。
在BigQuery ML的feature cross
要在BQ中使用 feature cross的功能,我們可以使用 ML.FEATURE_CROSS這個功能並且將它傳送到 day_of_week 與 hour_of_day的STRUCT feature:
ML.FEATURE_CROSS(STRUCT(day_of_weel, hour_of_day)) AS day_x_hour
STRUCT 語法建立兩個特徵的ordered pair。 如果我們的software framework不支援feature cross函數,我們可以使用string concatenation接獲得相同的效果:

新生兒出生問題的完整訓練範例則如下所示,將is_male和多個column的feature cross變成一個feature:

當我們有足夠的資料後,feature cross模式可以讓我們的model變得簡單。在新生兒出生的資料集,具有feature cross模式的線性模型的evaluation set的 RMSE 為 1.056。 或者,在沒有feature cross的相同資料集上用 BQ ML 訓練深度神經網路會產生 1.074 的 RMSE。儘管使用了更簡單的線性模型,但輸出效能略有提高,並且訓練時間也大大減少。
在TensorFlow的feature cross
為了使用 TensorFlow 中的特徵 is_male 和plurality來實現feature cross,我們使用 tf.feature_column.crossed_column。 crossed_column 方法有兩個參數:要交叉的feature key list和hash bucket size。 Feature cross將根據 hash_bucket_szie 進行hash,因此它應該足夠大大的減少collisions的可能性。 由於 is_male 輸入可以取 3 個value(True、False、Unkonwn),而plurality input可以取 6 個value(Single(1)、Twins(2)、Triplets(3)、Quadruplets(4)、Quintuplets(5)、Multiple (2+)),有 18 個可能的(is_male, plurality)個pairs。 如果我們將 hash_bucket_size 設置為 1,000,我們可以 85% 確定沒有collisions。
最後,要在 DNN 模型中使用crossed column,我們需要將其包裝在 indictor_column 或 embedding_column 中,具體取決於我們是要對其進行one-hot encoding還是以較低的維度呈現。

為何它是有效的
Feature cross提供了一種有價值的feature engineering方式。它們為簡單的模型提供了更多的複雜性、更多的呈現力和更多的量能。再回到新生兒出生資料集中 is_male 和plurality的feature cross。這種feature cross模式允許模型將雙胞胎男性與女性雙胞胎,與三胞胎男性分開來看,一胞胎女生通通分開來看。當我們使用 indicator_column 時,模型能夠將每個resulting cross視為獨立變量,基本上是向模型添加了 18 個額外的binary categorical features。

Feature cross可以很好地擴展到大量資料。雖然向深度神經網路添加額外的layer可能會提供足夠的非線性來學習 pair(is_male,plurality)的行為方式,但這會大大增加訓練模型的時間。在新生兒出生資料集上,我們觀察到在 BQ ML 中訓練有feature cross的線性模型與沒有feature cross訓練的 DNN 表現差不多。然而,線性模型的訓練速度卻要快得多。
下圖比較了具有(is_male,plurality)feature cross的線性模型和沒有任何feature cross的深度神經網路的 BQ ML 訓練時間和評估其loss。

簡單的線性回歸在evaluation set上實現了可接受的error,但訓練速度卻快了 100 倍。 將feature cross與大量資料相結合是學習training data中復雜關係的另一種策略。
取捨與替代方案
雖然我們討論了feature cross作為處理分類變量的一種方式,但它們也可以通過一些預處理(preprocessing)應用在數字型的feature。 Feature cross會導致模型的稀疏性(sparsity),並且經常與抵消這種稀疏性的技術一起使用。
處理數字型的feature
我們永遠不想建立具有連續input的feature cross。 請記住,如果一個input採用 m 個possible value而另一個輸入採用 n 個possible value,那麼兩者的feature cross將產生 m*n 個元素。 數字的input是密集的,使用的是連續的values。 在連續的input data的feature cross中列舉所有可能的values是不可能的。
相反,如果我們的資料是連續的,那麼我們可以在應用feature cross之前將y 資料bucketize以使其分類。 例如,緯度和經度是連續輸入,使用這些input建立feature cross具有直觀意義,因為位置是由一對有序的緯度和經度確定的。 然而,我們不是使用原始緯度和經度建立feature cross,而是將這些連續值合併並交叉為 binned_latitude 和 binned_longitude:

處理 high cardinality
因為來自feature cross的結果類別的基數乘法增加input feature。 關於feature cross的cardinality,feature cross導致我們模型輸入的稀疏性(sparsity)。 即使具有 day_of_week 和 hour_of_day 的feature cross,feature cross也將是維度為 168 的稀疏向量(如下圖)。

將feature穿過embedding layer以建立低維度呈現可能是有用的,如下圖所示

因為Embeddin設計模式允許我們捕捉資料資間的密切關係,通過Embedding layer的feature cross允許模型generalize來自hour和day組合的某些feature cross如何影響模型的輸出。 在上面的緯度和經度範例中,我們使用了一個Embedding feature layer來代替indicator column:
crossed_feature = fc.embedding_column(lat_x_lon, dimension=2)
進行正則化(regularization)
當交叉兩個具有large cardinality的分類特徵時,我們產生一個具有乘法基數的cross feature。 自然地,如果為單一個feature提供更多類別,則feature cross中的類別數量可以大大增加。 如果這到了單一個bucket的item很太的話,它將影響模型的generalize能力。 回到緯度和經度的例子。 如果我們對緯度和經度採用非常細緻的bucket,那麼feature cross將非常精確,它可以讓模型記住地圖上的每個點。 然而,如果這種記憶只是基於少數幾個例子,那麼記憶實際上就會overfit。
以計程車車資為範例,以在指定的接送地點和接送時間的情況下預測紐約的 小黃車資:

這裡有兩個feature cross:一個在時間上的(星期幾和一天中哪幾個小時),另一個在地理上的(上下車地點)。尤其是位置是high cardinality,很可能有些bucket的example很少。
出於這個原因,建議將feature cross與 L1 正則化配對,這會加強特徵的稀疏性,或 L2 正則化,這會限制overfitting。這允許 我們的模型忽略由許多合成(synthetic)特徵和打擊overfitting產生的extraneous noise。事實上,在這個資料集上,正則化將 RMSE 略微提高了 0.3%。
作為相關的一點,當選擇要組合哪些特徵進行feature cross時,我們不希望交叉兩個高度相關的特徵。我們可以將feature cross視為組合兩個特徵以建立ordered pair。實際上,“feature corss”的“cross”一詞是指笛卡爾積(Cartesian product)。如果兩個特徵高度相關,那麼它們feature cross的“跨度(span)”不會給模型帶來任何新資訊。一個極端的例子,假設我們有兩個特徵,x_1 和 X_2,其中 x_2 = 5*x_1。通過符號對 x_1 和 x_2 的值進行bucket並建立feature cross將產生四個新的boolean feature。但是,由於x_1和x_2的dependence,這四個特徵中的兩個實際上是空的,另外兩個正是x_1創建的兩個bucket。
設計模式四: Multimodel Input
Multimodal Input 設計模式解決了呈現不同類型的資料或通過連結所有可用資料呈現可以以複雜方式呈現的資料問題。
問題
通常,模型的input可以呈現為數字、類別、圖像或自由格式的文本。 許多現成的模型僅針對特定類型的input來定義 — — 例如,標準圖像分類模型(如 Resnet-50)但無法處理圖像以外的輸入。 為了了解對multimodel input的需求,假設我們有一個鏡頭架在一個十字路口擷取影像以識別交通違規行為。 我們希望我們的模型能夠處理圖像資料(鏡頭)和一些metadata (一天中的時間、一周中的哪一天、天氣等),如下圖 所示。

在ML訓練中的一種input是自由格式文本的結構化資料模型時,也會出現此問題。 與數字型的資料不同,圖像和文本無法直接輸入模型。 因此,我們需要以模型可以理解的方式表示圖像和文本的input(通常使用 Embeddings 設計模式),然後將這些input與其他 表格功能結合起來。 例如,我們可能希望根據他們的評論內容和其他屬性(例如他們支付的費用以及是午餐還是晚餐)來預測餐廳顧客的評分(如下圖)

解決方案
首先,讓我們以上面的對餐廳評分為例,將餐廳評論中的文本與評論所引用餐點的表格metadata相結合。 我們將首先結合數值和分類特徵。 meal_type 有三個可能的選項,因此我們可以將其轉換為 one-hot encoding,並將晚餐資料呈現為 [0, 0, 1]。 將這個分類特徵表示為一個array,我們現在可以通過將餐點的價格變成array的第四個元素:[0, 0, 1, 30.5] 來將它與 meal_total 結合起來。 Embeddings 設計模式是一種常見將text encoding ML模型的方法。 如果我們的模型只有文本(text),我們可以使用以下 tf.keras code將其表示為envedding layer:

在這裡,我們需要flatten Embedding來將 meal_type 與 meal_total結合:
model.add(Flatten())
然後,我們可以使用一系列 Dense layer將非常大的array轉換為較小的array,最後輸出是一個由三個數字組成的array:
model.add(Dense(3, activation=”relu”))
我們現在需要連接這三個數字,這三個數字與之前的input形成了評論的語句embedding:[0, 0, 1, 30.5, 0.75, -0.82, 0.45]
為此,我們將使用 Keras funtional API 並應用相同的步驟。 使用funtional API 構建的layer是callable,使我們能夠從input layer開始將它們連接在一起。 為了利用這一點,我們將首先定義我們的embedding layer和tabular layer:

注意到,我們已將這兩個layer的Input部分定義為它們自己的變量。 這是因為我們在使用functional API 建置模型時需要傳遞 Input layer。 接下來,我們將創建一個concatenated layer,將其輸入到我們的output layer中。 最後通過傳入我們上面定義的最初的input layer來建立模型:

現在我們有一個單一的model可以運作multimodel input.
取捨與替代方案
正如我們所見,multimodal Input設計模式找尋如何在同一模型中呈現不同的input format。 除了混合不同類型的資料之外,我們可能還希望以不同的方式呈現相同的資料,以便我們的模型更容易識別模式。 例如,我們可能有一個等級為 1 到 5顆 星的等級資料,並將該等級資料視為數字型和分類型。 在這裡,我們將multimodal input稱為以下兩種:
- 結合不同類型的資料,如image + metadata
- 以multiple方式呈現複雜的資料
我們會開始來看如何以不同的方式來呈現tabular data, 並且之後我們會看到text 與image data.
Tabular data 的multiple方式
為了了解我們如何為同一模型以不同方式呈現tabular data,讓我們回到餐廳評論範例。 相反的,我們假設評分是我們模型的input,我們試圖預測評論的有用性(就是有多少人喜歡評論)。 作為input,評分既可以表示為從 1到 5 的整數值,也可以表示為categorical feature。 為了分類地表示評分,我們可以他分成幾個bucket。 我們存儲資料的方式取決於我們,並取決於我們的dataset和use case。 為簡單起見,假設我們要創建兩個bucket:“good”和“bad”。 good bucket包括 4 和 5 的評分,ㄎbad bucket包含3到1。 然後我們可以建立一個boolean value來對評bucket進行編碼,並將整數和boolean value連接到一個array中。
以下是對於具有三個data point的小型dataset,可能會是什麼樣子:

這個結果的feature 是一個具有兩個 element的array,包含了整數的評分與boolean value的呈現

如果我們決定創建兩個以上的bucket,我們將對每個input進行one-hot encode並將這個one-hot array附加到整數來呈現。
以兩種方式呈現評分之所以有用,是因為以 1 到 5 顆星衡量的評分值不一定是線性增加。 4 和 5 的評分非常相似,1 到 3 的評分很可能表示評論者不滿意。 無論我們給不喜歡的東西打 1,2 顆星還是 3顆 星,通常都與我們的評論傾向有關,而不是評論本身。 儘管如此,在星級評分中保留更細粒度的資訊仍然很有用,這就是我們以兩種方式對其進行編碼的原因。
此外,可以考慮範圍大於 1 到 5 的feature,例如評論者的住家和餐廳之間的距離。 如果有人開車三個小時去餐廳,他們的評論可能比某些人來自隔一條街的客人更重要,因為它既要在 150 公里之類的數字距離呈現中設定threshold,又要包括距離的單獨分類呈現。 分類特徵可以分為“在州內”、“在國內”和“國外”。
Text的Multimodal 呈現
Text和image都是非結構化的,比表格資料更需要轉換。 以各種格式呈現它們可以幫助我們的模型擷取到更多的pattern。 我們將在上一節中討論text model的基礎上,用不同方法呈現text data。 然後我們將介紹images並深入探討在 ML 模型中呈現image data的幾個選項。
Text data multiple ways
鑑於text data的複雜性,有很多方法可以從中擷取其含義。 Embeddings 設計模式使模型能夠將相似的詞組合在一起,識別詞之間的關係,並理解text的句法元素。 雖然通過word embedding 呈現text最接近地反映了人類天生理解語言的方式,但還有額外的text呈現可以最大限度地提高我們的模型執行預測任務的能力。 在本節中,我們將研究呈現text的bag of words方法,以及從text中提取tabular feature。 為了展示text data的呈現,我們將引用一個資料集,該資料集包含來自 Stack Overflow 的數百萬個問題和答案的文本,以及每個post的metadata。 例如,以下的SQL query將為我們提供tag為“keras”、“matplotlib”或“pandas”的question subset,以及每個問題收到的答案數量:

Query result的輸出將會將會如下:

當使用bags of word(BOW) 方法表示text時,我們將每個text input到我們模型想像為一個 Scrabble tiles,每個tile包含一個單詞而不是一個字母。 BOW 不會保留我們text的順序,但它會檢測我們發送給模型的每段text中是否存在某些單詞。 這種方法是一種multiphot emcoding,其中每個text input都被轉換為 1 和 0 的array。 這個 BOW array中的每個索引index都對應於我們詞彙表中的一個詞。
為什麼 BOW(Bag of work)是有用的
BOW encoding的第一步是選擇我們的詞彙量大小,這將包括我們文本中最常出現的前 N 個單詞。理論上,我們的詞彙量大小可以等於整個資料集中unique words的數量。但是,這將導致非常大的 input array,其中大部分為 0,因為許多單一詞彙對於每個單一問題可能是unique的。相反,我們希望選擇一個足夠小的詞彙量,以包含表達問題的關鍵、重複性出現的詞彙(如“the”、“is”、“and”等)。
我們模型的每個input都將是一個與我們的詞彙表大小相同的array。因此,這種 BOW 呈現完全忽略了我們詞彙表中未包含的單詞。選擇詞彙量大小沒有一個神奇的數字或百分比 — — 嘗試幾個並看看哪個在我們的模型上表現最好是沒有幫助的。
要理解 BOW encoding,讓我們先看一個簡化的例子。對於這個例子。假設我們正在預測stack overflow問題的tag,即三個可能的標tag list:“pands”、“keras”和“matplotlib”。為簡單起見,請確保我們的詞彙表僅包含以下列出的 10 個單詞:
dataframe
layer
series
graph
column
plot
color
axes
read_csv
activation
這是我們的word index,我們輸入模型的每個input都是一個 10 個element的array,其中每個index對應於上面列出的詞之一。 例如,輸入數組的第一個索引中的 a 1 表示特定使用包含單詞“dataframe”。 為了從我們的模型的角度理解 BOW 編碼,想像我們正在學習一種新語言,上面的 10 個單詞是我們唯一知道的單詞。 我們所做的每一個“prediction”都將完全基於這 10 個單詞的存在與否,並將排除此列表之外的任何單詞。
因此,給定問題標題“How to plot dataframe bar graph”,我們將如何將其轉換為 BOW 的資料呈現? 首先,讓我們注意這句話中出現在詞彙表中的詞:plot、dataframe 和 graph。 這句話中的其他詞將被 BOW 忽略。 使用我們上面的word index,這句話變成了:
[1 0 0 1 0 1 0 0 0 0]
需要注意,此array中的 1 分別對應於dataframe、graph和plot的indices。 總而言之,下圖顯示了我們如何根據詞彙表將input從raw text轉換為 BOW-encoded的array。 Keras 有一些實用方法可以將text編碼為 BOW,因此我們不需要編寫code來識別text corpus中的top words並將raw text從頭開始編碼到multi-hot arrays中。

鑑於呈現text有兩種不同的方法(embedding和 BOW),我們應該為哪種的task選擇哪種方法?對於 ML 的許多方面,這取決於我們的資料集、預測任務的性質以及我們計劃使用的模型類型。
Embedding為我們的模型添加了一個額外的layer,並提供了 BOW encoding無法提供的關於詞義的額外資訊。然而,Embedding需要訓練(除非我們可以對我們的問題使用pre-trained的embedding)。雖然深度學習模型可以達到更高的準確率,但我們也可以嘗試在線性回歸或決策樹模型中使用 BOW 編碼,使用框架如 scikit-learn 或 XGBoost。使用具有更簡單模型類型的 BOW encoding對於快速原型設計或驗證我們選擇的預測任務是否適用於我們的資料集非常有用。與Embedding不同,BOW 不考慮text document中單詞的順序或含義。如果其中任何一個對我們的預測任務很重要,Embedding可能是最好的方法。
建立一個結合 BOW 和text embedding呈現的深度模型來從我們的資料中提取更多模式也有好處。為此,我們可以使用 Multimodal Input 方法,期望我們可以連接embedding和 BOW 呈現,而不是連接text和tabular features。在這裡,我們Input layer的形態將是 BOW 呈現的詞彙量大小。以多種方式呈現text的一些效益包括:
- BOW encoding為我們詞彙表中最重要的單詞提供了strong signals,而embedding可以識別更大的詞彙表中單詞之間的關係。
- 如果我們有在語言之間切換的text,我們會為每個text建立embeddings(或 BOW encodings)並進行連接。
- Embedding可以對text中單詞的頻率進行編碼,其中 BOW 將每個單詞的存在視為boolean values。 兩種方式都是可用的。
- BOW encoding可以識別所有包含“amazing”一詞的評論之間的模式,而embedding可以學習將“not amazing”與低於平均水平的評論相關聯。 同樣,這兩種呈現也都是可用的。
從Text擷取tabular features
除了對raw text data進行編碼外,通常還有其他text feature可以呈現為tabular features。 假設我們正在建立一個模型來預測 Stack Overflow 的問題是否會得到回應。 關於text,但與確切單詞本身無關的各種因素可能與針對此任務訓練模型有關。 例如,問題的長度或問號的存在可能會影響答案的可能性。 但是,當我們建力embedding時,我們通常會將單詞截斷到一定長度。 問題的實際長度在該資料呈現中丟失了。 同樣,標點符號經常被刪除。 我們可以使用 Multimodal Input 設計模式將這些丟失的資訊帶回模型。 在下面的查詢中,我們將從 Stack Overflow 資料集的標題字段中提取一些tabular features來預測問題是否會得到答案:

結果會是這樣:

除了直接從problem title中提取的這些特徵之外,我們還可以將有關問題的metadata呈現為feature。 例如,我們可以通過feature來表示問題所具有的tag數量以及它在一周中的哪一天停止。 然後,我們將這些表格特徵與我們的編碼text相結合,並使用 Keras 的連接層將這兩種呈現形式送到我們的模型中,以將 BOW 編碼的text array與描述我們text的tabular metadata相結合。
Images的Multimodal呈現
與我們對文本embedding和 BOW encoding的分析類似,在為 ML 模型準備image資料時,有許多方法可以呈現image資料。 像raw text一樣,image不能直接輸入進模型中,需要轉換成模型可以理解的數字格式。 我們將首先討論一些呈現image資料的常見方法:如 pixel values、tiles sets和windowed sequences。 Multimodal Input 設計模式提供了一種在我們的模型中使用多個image資料呈現的方法。
使用pixel values的方式
Images的核心是pixel values arrays。 例如,一張黑白圖像包含從 0 到 255 的pixel values。因此,我們可以將模型中 28×28 pixel values的黑白image呈現為 28×28 ,其中整數值從 0 到 255. 在這個部分中,我們將參考 MNIST 資料集,這是一種通用的 ML 資料集,包括手寫數字的images。
使用 Sequential API,我們可以使用 Flatten layer呈現pixel values的 MNIST images,這個layer將image flatten為one-dimensional 784 (28 * 28) element array:

對於彩色images,這會變得複雜一些。 RGB(光的三原色) 彩色images中的每個pixel都具有三個value,分別為紅色、綠色和藍色。 如果我們在上面的例子中的image是彩色的,我們會向模型的 input_shape 添加第三個維度,它就會是這樣子:

雖然將images呈現為pixel value arrays對於簡單的image(如 MNIST 資料集中的灰度圖像)效果很好,但當我們在整個過程中引入具有更多邊緣和形狀的images時,它會開始崩潰。 當網路同時接收images中的所有pixel時,它很難專注於包含重要資訊中相鄰pixel的較小範圍。
使用tiled structures的方式
我們需要一種方法來呈現更複雜的實際的images,這將使我們的模型能夠提取有意義的細節資訊並理解其模式。 如果我們一次只向網路提供images的一小部分,則更有可能識別出相鄰pixel中存在的spatial gradients(空間梯度)和edge等內容。 實現這一目標的常見模型架構是卷積神經網路 (CNN)。
卷積神經網路 (CNN)
如下圖。 在這個例子中,我們有一個 4×4 的網格,其中每個方塊代表我們image上的pixel value。 然後我們使用max polling來獲取每個區塊的最大值並生成一個較小的矩陣。 通過將我們的image劃分為tiles grid,我們的模型能夠以不同的粒度級別從image的每個區塊中提取關鍵資訊。

上圖使用的kernel size為 (2, 2)。 kernel size是指我們image的每個區塊的大小。 我們的filter在建立下一個區塊之前移動的空間數,也稱為 stride ,移動的空間數是2。因為我們的 stride 等於kernel size的大小,所以建立的區塊是不會重疊的。
雖然這種tiling方式比將image呈現為pixel value arrays保留了更多的細節 料,但在每個pooling step後都會丟掉相當多的資訊。 在上圖中,下一個polling step將產生 8 的scalar value,只需兩步即可將我們的矩陣從 4 × 4 變為snigle value。 在實際的image中,我們可以想像這會如何使模型偏向於關注具有主導pixel value的區域,同時丟失可能圍繞這些區域的重要細節。 我們如何才能在將image拆分成更小的區塊的同時仍然保留image中的重要細節呢? 我們將通過使這些區塊重疊來做到這一點。 如果上圖中的範例改為使用stride為 1,則輸出將變成 3×3 矩陣(如下圖)。

我們可以把這個3x3的結果在一次轉成2x2的網格(如下圖)

我們以最終值 127 結束。雖然最終值相同,但我們可以看到中間步驟如何從原始矩陣中有著更多細節。
Keras 提供卷積層(convolution layers)來構建模型,image拆分為更小的windowed區塊。 假設我們正在建立一個模型來將 28 × 28 彩色圖片分類成“狗”或“貓”。 由於這些圖片是彩色的,每個圖片將被呈現為一個 28 × 28 × 3 dimensional array,因為每個pixel都有三個color channels。 以下是我們如何使用卷積層和 Sequential API 定義此模型的input:

在這個例子中,我們將輸入圖片分成 3 × 3 區塊,然後將它們通過max polling layer。 建立一個將圖片分割成sliding windows區塊的模型架構,使我們的模型能夠識別圖片中更精細的detail,如edges和shapes。
結合不同的images呈現
此外,與BOW和text embedding一樣,以多種方式呈現相同的image data可能是有用的。 同樣,我們可以使用 Keras functional API 來實現這一點。 以下是我們如何使用 Keras Concatenate layer將pixel values與slideing window的資料呈現相結合:

為了定義一個接受multimodal input呈現的模型,我們可以將我們的連接層輸入到我們的output layer:

選擇使用哪種image呈現或是否使用multimodal 呈現在很大程度上取決於我們正在使用的image data類型。 一般來說,我們的image越詳細(解析度越高),我們就越有可能將它們呈現為tiles或tiles的sliding windows。 對於 MNIST 資料集,僅將images呈現為pixel values就夠了。 另一方面,對於複雜的醫學圖片,我們可能會通過組合多個資料呈現來提高準確性。 為什麼要組合多個image呈現? 將image呈現為pixel value允許模型識別image中的high-level focus point,如dominant、high-contrast objects。 另一方面,Tiled representations有助於模型識別更細粒度、對比度更低的邊緣和形狀。
用metadata在image中
之前我們討論了可能與text相關聯的不同類型的metadata,以及如何提取這些metadata並將其呈現為我們模型的tabular feature。 我們也可以將這個概念應用於image。

為此,讓我們回到之前的交通流量案例(如上圖)中引用的模型範例,該模型使用十字路口的鏡頭來預測它是否包含交通違規。 我們的模型可以自己從交通影片中提取許多模式,但可能還有其他可用資料可以提高我們模型的準確性。 例如,某些行為(例如,紅燈右轉)在高峰時段是不允許的,但在一天中的其他時間是可以的。 或者,司機在惡劣天氣下更有可能違反交通法規。 如果我們從多個交叉點收集影像資料,了解圖像的位置可能對我們的模型也很有用。 我們現在已經確定了三個額外的tabular features,可以增強我們的圖像模型:
- Time of day
- Weather
- Location
接下來,讓我們考慮這些features中的每一個的可能的呈現。 我們可以將時間呈現為一天中的小時整數。 這可能有助於我們識別與尖峰時段等相關的模式。 在此模型的context,了解拍攝影片時是否天黑可能更有用。 在這種情況下,我們可以將時間表示為一個boolean feature。
天氣也可以用各種方式呈現,包括數字和分類值。 我們可以將溫度作為一個特徵,但在這種情況下,馬路上的可視性可能更有用。 表示天氣的另一種選擇是通過分類變量標示是否下雨或下雪。 如果我們從多個位置收集資料,我們可能也希望將其編碼為一個特徵。 這作為分類特徵最有意義,甚至可以是多個特徵(城市、國家、縣市等),具體取決於我們從多少個位置收集資料。 在這個例子中,假設我們想要使用以下表格功能:
- Time as hour of the day(integer)
- Visibility(float)
- Inclement weather(categorical: rain,snow,none)
- Location ID: (categorical with five possible location)
以下是這一個交通資料集的subset(三筆資料)

然後,我們可以將這些tabular feature組合到每個範例的single array中,這樣我們模型的input shape會是 10。第一個範例的input array將如下所示:
[9, 0.2, 0, 0, 1, 0, 1, 0, 0, 0]
我們可以將此input輸入到 Dense fully connected layer,我們模型的輸出將是 0 到 1 之間的single value,指出是否包含交通違規。 為了將其與我們的image data相結合,我們將使用與我們討論的text model類似的方法。 首先,我們定義一個卷積層來處理我們的image data,然後一個 Dense layer來處理我們的tabular data,最後我們將兩者連接成單一輸出。(如下圖)

Multimodal feature呈現和模型可解釋性
深度學習模型本質上難以解釋。如果我們構建了一個準確率達到 99% 的模型,我們仍然不知道我們的模型是如何進行預測的(如果它做出這些預測的方式是正確的)。例如,假設我們在實驗室拍攝的培養皿圖片上訓練了一個模型,這個模型獲得了高準確度分數。這些圖片還包含來自拍攝照片的科學家的註解。我們不知道的是,該模型是否錯誤的使用註解而不是培養皿的內容來進行預測。有幾種解釋圖片模型的技術可以突出顯示模型預測信號的pixel。然而,當我們在單一模型中組合多個資料呈現時,這些特徵變得相互依賴。因此,很難解釋模型是如何進行預測的。第我們在之後會有專章介紹資料的可解釋性。
總結
在本文中,我們學習了為模型呈現資料的不同方法。我們首先研究瞭如何處理numerical input,以及scaling這些input如何加快模型訓練時間並提高準確性。然後我們探索瞭如何對分類輸入進行特徵工程,特別是使用 one-hot 編encoding和使用categorical values arrays。
在本文的其餘部分,我們討論了呈現數據的四種設計模式。第一個是hashed Feature設計模式,它涉及將categorical input編碼成一個unique strings。我們使用 BigQuery 中的機場資料集探索了幾種不同的hasing方法。我們在本文中看到的第二種模式是 Embeddings ,這是一種表示High cardinality資料的技術,例如具有許多可能categories或text data的輸入。Embedding呈現多維空間中的資料,其中維度取決於我們的資料和預測工作。接下來,我們看了 Feature Crosses ,這是一種將兩個特徵結合起來以提取可能無法通過對特徵進行單獨編碼來簡單擷取特徵之間關係的方法。最後,我們通過解決如何將不同類型的input組合到同一模型中以及如何以多種方式表示單一特徵的問題來研究multimodal輸入呈現。本文重點介紹為我們的模型準備輸入資料。之後的文章,我們將通過深入研究表示預測工作的不同方法來關注模型的輸出。
