建置與管理Google Cloud的儲存服務
這一篇我們介紹如何部署GCP的storage system與在這些系統上的資料運作,例如資料的匯出/匯入,設定存取控制,效能調較等。包含了Cloud SQL, Cloud Spanner, Cloud Bigtable,Cloud Firestore,BigQuery,Cloud Memorystore與cloud Storage。同時我們也會討論到如何管理unmanaged Database, 了解各項storage service費用與效能,還有data lifecycle的資料管理。最終目的是要建立我們的Data pipeline。
Cloud SQL
這是一個全託管式的Relational DB。這個服務裡面有三種Database 可以使用— MySQL / PostgreSQL / SQL Server。全託管式Cloud SQL就是Database運行的底層OS是不需要管理的,OS Level相關的維運會由GCP幫你管理。
Cloud SQL support regional-level的運作,資料最多可以儲存30TB。如果要儲存更多的資料或是同時要支援多個region的話則可以考慮Cloud spanner.
設定Cloud SQL
第一步就是選擇你要哪一種RDBMS(MySQL / PostgreSQL / SQL Server)。再來要設定的資訊如下
- Instance ID
- password
- region and zone
- database version
雖然你不用管OS,但是你還是要選機器的規格(vCPU/memory)來運行DB。第二代的Cloud SQL目前可以支援最大到96 vCPU and 64TBmemory.(設定示意圖如下)

之後要網路連到這個DB的instance 可以用public Ip or Private IP, 預設是Public IP. 若是用Public IP你就需要設定防火牆規則讓被允許的IP連線。還有另一個選項是用Cloud SQL Proxy, 使用這一個就不須要設置IP白名單與SSL加密。會由這個服務來幫你做(適用第二代的Cloud SQL)。Proxy manager會幫你做驗證與在傳送時做資料加密。
你可以對Cloud SQL做每天的備分(image backup, 所以你restore是整個DB image )最短可以到四小時備份一次。或是底層的hardward在GCP要做維護時也可以維護前自動備份。備份的資料會在你delete instance時自動一併的delete. 但如果你要在instance delete時還保有備份或是要restore 特定DB裡的 table就要用exports,這個我們稍後會談到。
雖然GCP幫你管理了DB instance creation,但你還是有一些DB的參數可以選(如下圖Flags選項)

基本上Cloud SQL是在一個region裡的一個zone起一個instance。但如果你要對這個instance (可能是production system)做HA. 當你起用HA功能時, GCP會在第二個Zone起第二個instance並開始將primary DB instance 資料同步到這第二個backup instance。當primary inatnce不論甚麼原因掛掉,GCP都會幫你自動fail over到第二個insatce去你不用做任何事。但這個fail over的時間會視你的instance大小而定(筆者等過有幾分鐘才完成fail over的),為了因應這個狀況你的Application layer要做好這一類在fail over時間的error handle.
GCP在這邊的建議是將以前傳統大的DB拆分成眾多小一點的DB, 這樣運作的風險會小一點。例如依使用狀況將read的資料的時間錯開或是同一類的資料(例如地理位置擺在同一個DB)其他的擺在另一個DB.但這樣對傳統Application會有很大的挑戰,因為你的code可能要改。但若是你的Application跑在GKE或是serverless上的話就是適合多。
每一個DB最好不要超過10,000 tables。所有的table都要有primary key以便加速以row-based replication.
建立Read only 的instance 已達到讀寫分離(增加效能)
傳統上我們的Application 都是對同一套DB作read/write,而且有時會同時做read/write動作會造成DB效能不彰。但我們可以在Cloud SQL中起用Read Replica instance這樣一個DB專門read(同一個region)而一個DB專門write. 這個read DB是同步持續update write DB(primary DB)的資料。在啟用這個read DB有以下事項需要注意
- Read replica 的instance 沒有HA功能,所如果它的底層hardward fail了你就要手動再起一個新的(這個你可以透過監控加自動化方式)。
- 而read replica instance的底層維護時間沒有特定,所以它可能隨時會死給你看。
- 在Primary instance要enable Binary logging
- 你可以同時起多個read replica, 但Cloud SQL不會對你的Application 要對這些instance 做 read operation的 load-balance. 你的Application要處理這一段。
- read replica instance不能backup
- read replica instance可以從primary instance獨立出來變成一個單獨的DB instance(可以read/write)但你無法再把這個與primary instance切斷關係的instance逆轉回read replica
- 如果你要restore primary instance, read repliac要先delete掉。等到restore好後再起一個新的read replica
- Read replica and primary instance 要在同一個region
Importing and exporting data
就跟一般的RDBMS一樣資料可以備import/export。Cloud SQL也支援這個功能。
- MySQL — mysqldump
- PostgreSQL — pg_dump
- SQL server — bcp(bulk copy)
一般來說data import/export的來源與目的端大都是 Cloud stroage的buckets.都是以檔案格式存在CSV or SQL dump format.
在使用command line做data export時有一些flags需要特別被設定後面將資料import回來才不會有問題。在import data到Cloud SQL時你需要排除非資料的部分,如views/triggers/stored procedures/function。因為這些objects可以在data import到DB裡重新create(用scripts方式)。
而在export data(CSV/ SQL dump)到cloud storage時這些檔案可以被壓縮以節省cloud storage的費用(假如你的檔案真的很多的話)。而檔案的壓縮與解壓縮都可以在import / export指定做好不用再手動做這件事。
Cloud Spanner
這是Google專屬的Relational, horizontally scalable, global的DB。 因為它是relational DB所以也support fixed schema(是合規ANSI SQL 2011的)。Cloud Spanner提供data 的strong consistency. 所以所有對DB的平行處理程序看到的DB狀態都是一樣的。Cloud Spanner的data consistency跟No SQL的 eventually consistent是不一樣的,因為每個處理程序看到的NOSQL DB states是不一樣的。Cloud Spanner原生就是HA的,而且不需要failover instance(像Cloud SQL). 它是自動replica data到所有的節點的。
設定Cloud Spanner
設定方式跟Cloud SQL很類似(如下圖),以下在create instance時需要指定以下資訊
- instance name
- instance ID
- Regional or Multi-Regional
- Number of nodes
- Region in which to create the instance
其中上面第四與第五項的選擇關乎到你的費用。因為在不同的region有費用會有稍許的差異。 nodes的數量跟你資料的負載有關。 Google 建議如果只有一個Region跑Spanner,哪麼instance CPU要低於65%。如果是multi-regional instance就要低於45%. 每一個node可以儲存2TB的資料。
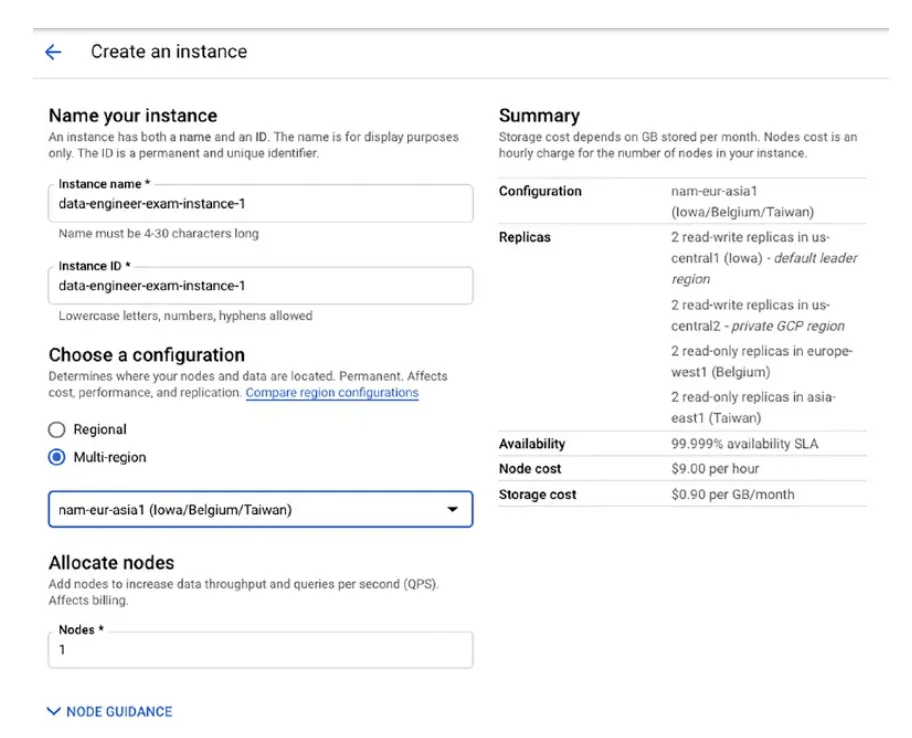
Replication in Cloud Spanner
Spanner會負責將這些散落在不同region的DB instance做data replica(by rows)。當Spanne開始將這些instance做全球性的資料同步,你可以從任一個replica讀得到最新的資料(row)。 Row會被拆分,拆分是一起copy的連續性blocks of row。這一群replica其中一個會被指定為leader,這個leader負責將資料寫入。由於資料與需要資料的Application在地理位置上接近,因此使用replica可以提data 的HA並減少latency。同樣,你需要拿捏添加nodes的效益與一直往上加node的費用取得一個平衡。
因為這樣分散式的特性對Spanner寫入資料時造成了挑戰。為了讓所有的replica保持資料同步,Spanner使用投票機制來決定資料寫入會發生的衝突狀況。Spanner使用這個投票機制使用"conflict value"來決定哪一資料是最新的資料寫入。
Spanner有三種replica型式
- Read-write replicas
- Read-only replicas
- Witness replicas
Regional instance只能只用 Read-only replicas; 而Mutli-regional instance則是三種都可以使用。Read-write replicas維持full copies的data以及讀取的操作,它們也可以選出write operation. Read-only replicas除能不能選出write operation之外,其他功能都跟Read-write replicas一樣。Witness replicas沒有保有全部的資料,但是會參與write投票。Read-write replicas最大的功用在於完成選舉的法定人數機制。
Regional instance可以維持三個Read-write replicas. 而使用Multi-regional instance我們可以考慮在兩個region使用 Read-write replicas,每個region 有兩個replicas。在這兩個region裡面選出一個leader replicas。而Witness replicas則選擇放置在第三個region。
Database 設計考量
就像NoSQL DB一樣, Spanner 也會發生同時對一個node 有過多的read-write operation而沒有將同時大量的read-write平行處理分流到多個node,這個我們稱為hotspots. 會發生這樣的狀況通常都是你使用的primary key是有順序性的,例如自動增加計數或timestamp的欄位資料。如果真的要用這一類的值作為primary key,哪麼就要將這些值(value)做hash.
如同我們之前提到的Relational DB的資料是經過正規化的。這意味著你在讀取資料時通常這些資料是分散在不同的table,哪麼 join table就會經常使用到。而這也是讀取DB效能最差的動作,因為DB需要從storage擷取不同的data block來組合資料。而Clud Spanner採用了一種parent-child 的方法讓這一類的資料儲存在一起(同一個data block),這一個方法需要你在Design schema時指定。需要注意的是採用parent-child方式的table它們的row size不可以超過4GB.
匯入/匯出資料
資料可以被從 Cloud storage import/export到 Cloud Spanner. export的檔案格式為CSV 或Apache Avro. 這個匯出的流程我們可以使用 Cloud Dataflow connector來完成。
以下有幾個因素會影響資料的import/export的速度
- DB的大小
- 有多少的secondary indexes
- 資料的位置
- Spanner的負載與node的數量
Cloud Bigtable
一種用在幾豪秒內寫入大量資料的wide-column NoSQL DB.通常用在資料是IoT,time-series, finance 等相似的Application上使用。
設定 Bigtable
這也使一個全託管式的服務,像Cloud SQL, Cloud Spanner一樣,你只需要指定instance的相關資訊就可以。
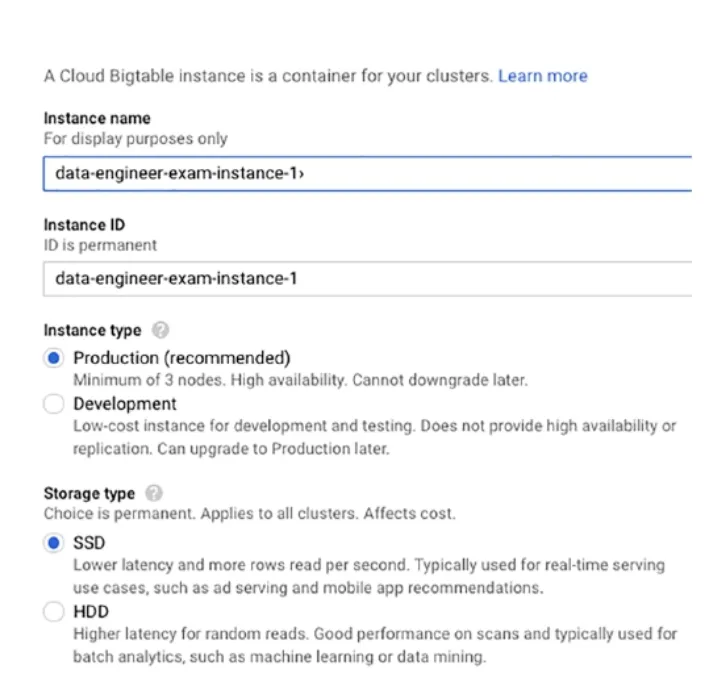
除了需要指定Instance name , Instance ID外。你還需要確定這一個Bigtable的Cluster是要用在Production or Development的環境上(如下圖)。Production 環境提供了HA環境(至少需要三個node)費用貴了一點,而Developementc環境則不用HA提供了較低的費用進行測試而已。
當Create cluster時我們需要提供cluster ID/ region/ zone/nodes的數量等資料。Bigtable的效能與nodes的數量呈線性關係,也就是說node數量越多效能越好。例如production cluster使用三個nodes並也採用SSD硬碟,哪麼每秒鐘可以同時read and write 3000筆row。如果有6 nodes則row的數量就加倍到6000。
雖然Bigtable的 cluster的node都在同一個region,但是你可以為這一個preoduction cluster在另一個region 做一個replica cluster, 資料會同步在這兩個cluster之間,你的cluster HA功能就可以到region level。如果你的primary cluster沒有反應它你可以手動的fail over過去。若是你的Application有multicluster routing功能,哪Application就會自動切換過去。
但Bigtable是一個稍微貴一點的服務(但若跟你在機房自建跟需要維運的能力技巧,你可以算一算這一筆帳,看哪個比較划算)。下圖是一個範例計算
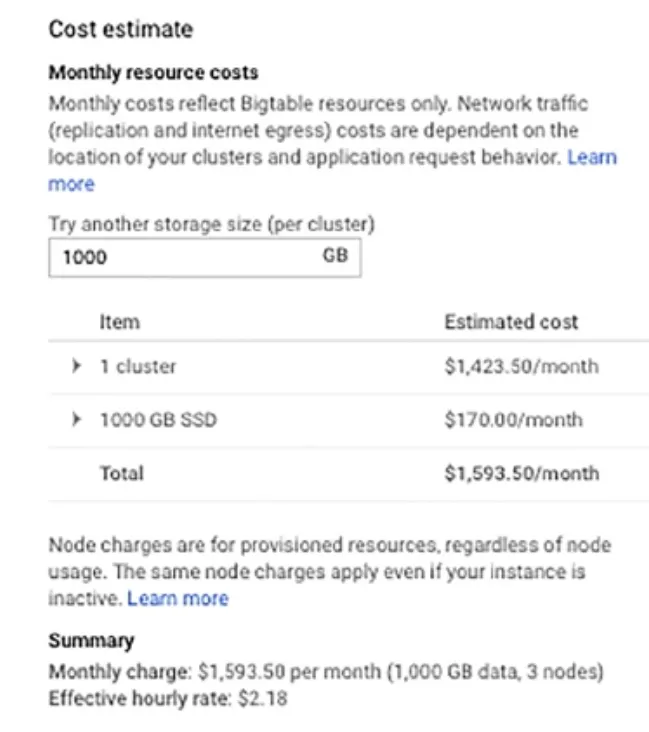
當你migrate 你地端的hadoop 跟Hbase到Bigtable時,如果你的JAVA是用到原來的HBase shell and HBase client則Bigtable提供一模一樣的功能。Bigtable也提供 "cbt"的command-line工具來操作Bigtable。
Bigtable可以被Bigquery access。 資料可以不用存在Bigquery而是以external型式存放在Bigtable。這讓你可以存放經常變動的資料在Bigtable裡(例如IoT資料),這樣做的好處在於如果你要對資料使用有機器學習功能的服務你就不用常常要將資料倒到BigQuery裡。
Database設計考量
這跟設計Relational DB的schema有非常大的不同,Bigtable 的table是非正規化的,一個table裡可能有上千個column。它沒有join table這樣的功能也沒有secondary indexes,資料存放在Bigtable是採用row-key的方式(這個我們Google Cloud的儲存服務介紹文章有介紹過),它是一種在Bigtable的indexed-cloumn. 它會讓相關的資料盡量存放在鄰近的row,因為這樣就可以加快讀取的效能。
所有的operation在row-level都是atomic,而不是transactional level. 例如我們有一個Application 要寫兩筆row進去,有可能會一筆成功一筆失敗。而這樣會造成DB的不一致性發生,為了避免這個問題你的資料在write/update時最好相關的資料都在同一筆row中。
因為Bigtable沒有seconday indexes的功能,所以在查詢資料時只有兩種方式 — row-key-based or full table scan。後者大家都知道是很沒效率的做法,相反的單一的row-key或一個區間的row-key查詢方式才是比較有效的。但這需要你很小心的設計你想要怎麼query data哪row-key就要適合哪種query的方式。在Bigtable設計row-key的目標就是Bigtable儲存資料是有排序順序的。
好的row-key有著以下特徵
- Using a prefix for multitenancy。這會將不同客戶(或是類別)的資料隔離開來。因為是隔離開的所以在read / scan data將會變得有效率。
- Columns不會經常的update,像是 User ID或timestamp
- 在row-key的first part是非連續性資料,以免有hotspots的狀況發生
另外一個增加效能的方式是column families,它是一組資料相關的columns。這一類的資料會被一起儲存一起讀取。
匯入/匯出資料
Bigtable的data import /export跟Cloud Spanner一樣是用Cloud Dataflow來完成的。資料可以被從Cloud Storage import/export而資料格式則是 Avro或SequenceFile。CSV 檔案也可以用Dataflow完成。
Cloud Firestore
這個服務是來取代原來Cloud Datastore 的Document DB。 Document DB是當資料結構因record而異所使用的。Cloud Firestore有著之前Cloud Datastore所有沒的其他功能:
- Strongly consistent storage layer(Datastore and Native mode)
- Real-time updates(only native mode)
- Mobile and Web client libraries(only native mode)
- A new collection and document data model(only native mode)
Cloud Firestore有兩種運作模式: Native mode(只有這個模式支援上述的全部功能) and Cloud datastore mode. 使用Datastore mode時,firestore運作方式跟datastore一樣只是使用 firestore 的storage system。這時不會有datastore 的eventual consistency 而是 strongly consistency的特性。原來Datastore的特一些限制 : 25 entity groups, ancestor/descendent relations/ maximum of one writer per second to an entity groups都沒有了。
Cloud Firestore data model
使用Datastore mode的話, data model會是由 consistents of entities, entity groups, properties與key所組成。
Entities就像是Relational DB的table. 它描述一種東西的特別型態,稱作enrity kind. Entities有一個identifiers,這個identifiers會被系統自動的assign或是由你的Application來assign. 假如在datastore mode這個identifiers是被隨機assign的話,identifiers就會從一個uniformly distributed set of identifiers隨機產生出來。這個隨機的distribution最主要是避免當有一個很大數量的entities在短時間產生後會有hot spot的狀況發生。
Entities會有properties, 它是name-value的組成。例如 'color’:’blue’ . 不同的entities會有著不同的形態的values. property 不是strongly type,property也可以被indexes.
properties可以有一個或多個values。 多個values會被儲存成array properties. 例如一個新聞標題是 topic 而values是
{'technology’, ‘business’, ‘finance’}.
property 的value也以是另一個entity,這樣子的架構就會是hierarchical. 如下範例

在這個範例我們看到 Line_item既是value同時也是一個entity. 所以以entity的關係來說, order是Line_item的parent entity. order也是root entity, 因為再往上沒有paretn entity了。如果是一個entity要reference另一個entity你就需要指定path 稱作ancestor path. 這個path也包含了一種從root到descendent 的identifier。例如如果你要查詢 Green shirt,你應該使用這樣的reference
[order:1, line_item: 20]
總結一下,entities的properties可以是atomic values, arrays或者也是可以一個entities。Automic value的值可以是integers, floating value number, strings, dates. Arrays是property有一個以上的Value才會用到。Child entities上一層會有一個entities稱作parent entities. 這是最複雜的用法,因為 parent/child entities裡的objects會在propoerty包含到多個atomic value/array/ entity.
一個entity與其下層所包含的所有entity稱為entity groups.
每一個entity會有一個unique key,這是來辨識不同的entity. 這個key的組成是一個自選的ancestor path.所以這個key可以被用來找尋相對應的entity與其property. 或者你也可以用property跟valuse來找尋entity(很像是SQL語法的 where句型)。不過如果你要查詢property value的話property需要被indexes.
Indexing and Querying
Cloud Firestore有兩種型態的indexes: built-in and composite. built-in在你create entity就會自動有了。而composite則是entity的多個value組成的。
Indexes是使用在query跟在做property reference 的filter時一定要有的。例如我們要Query “color” = “blue”,就需要color這個property的indexes一定要有。如果沒有indexes,哪Firestore不會回覆任何entity的訊息,那怕這個entity只有一組 “color”=”blue”的值。built-in indexes只能用在查詢中有等於或不等於的語法狀況,若是在更複雜的查詢就要用composite indexes. 這是用在在查詢中有多個filter條件的狀況下使用。例如我們要filter color = ‘blue’ 加上 size = ‘small’就需要使用使用composite來對color and size這兩個porperty做indexes.
composite indexes被定義在一個index.yaml的設定檔中。你也可以在這個檔案中把built-in indexes的設定給去掉(畢竟indexes也是會佔空間)。有些property你可能永遠也不需要做filter,哪你就可以再把這個property排除做indeses,這樣又再省一次空間而且每哪麼多indexes效能也會變好(因為不用做不需要的indexes update).
Cloud Firestore使用 SQL-Like的語法稱作GQL(GraphQL)。Query通常包含必要的entity kind, filters。 以下為一個Query的範例
SELECT * FROM
WHERE item_count > 1 and status = ‘shipping’
ORDER_BY item-count DESC
就上面例子來看我們需要對 item_count 跟status做composite indexes這樣才會有訊息回覆。
匯入/匯出資料
資料一樣可以從Cloud Firestore import/export。 在export entity時只會有資料不會有indexes,indexes必須要資料import的過程中會重建。當export data時你可以使用filter來export你只想要匯出的資料。
如果你export出來的資料有使用到filter,哪麼你就可以用Bigquery 的bq command將資料import 到BigQuery(Cloud firestore export到cloud stroage).當你要這麼做時有一些條件必須要符合
- 這個exported的檔案在cloud storage URI必須不是wildcard
- 已經存在的table(已經有定義好的schema)資料不可以被append上去
- entities在export檔案中是有consistent schema的
- 任何的property在export的過程中,如果value是大於64KB的。哪麼該Value會被自動truncate到64KB
Cloud firestore適合儲存半結構話的資料並且不需要高速的寫入資料(<10ms).低延遲的資料寫入應該用Bigtable.
BigQuery(底下會簡稱BQ)
BQ是一個全託管式並且儲存與分析的資料可以到PB等級的Data warehouse解決方案。我們在BQ經常會實行的工作如下
- Interacting with Data set
- Importing / exporting Data
- Streaming inserts
- Monitoring and logging
- Optimizing table and queries
BQ在整個Data life cycle中的Process and Analyze階段是重要的服務。
BQ Datasets
Datasets在整個BQ的整個組織裡最基本的單位。datasets裡面可以有很多個tables。當我們在create datasets時需要指定以下資訊
- Dataset ID
- Data location
- Default table expiration
dataset ID就是dataset的名稱, location是指你要將資料放在哪一個有BQ服務的region。 default table expiration使指你的資料放在BQ上要放多久,時間如果到了就會自動刪除。你可以用BQ的web介面或bq command line來create table。table完成後你就可以開始載入資料。底下一個範例用SQL來query 一個dataset
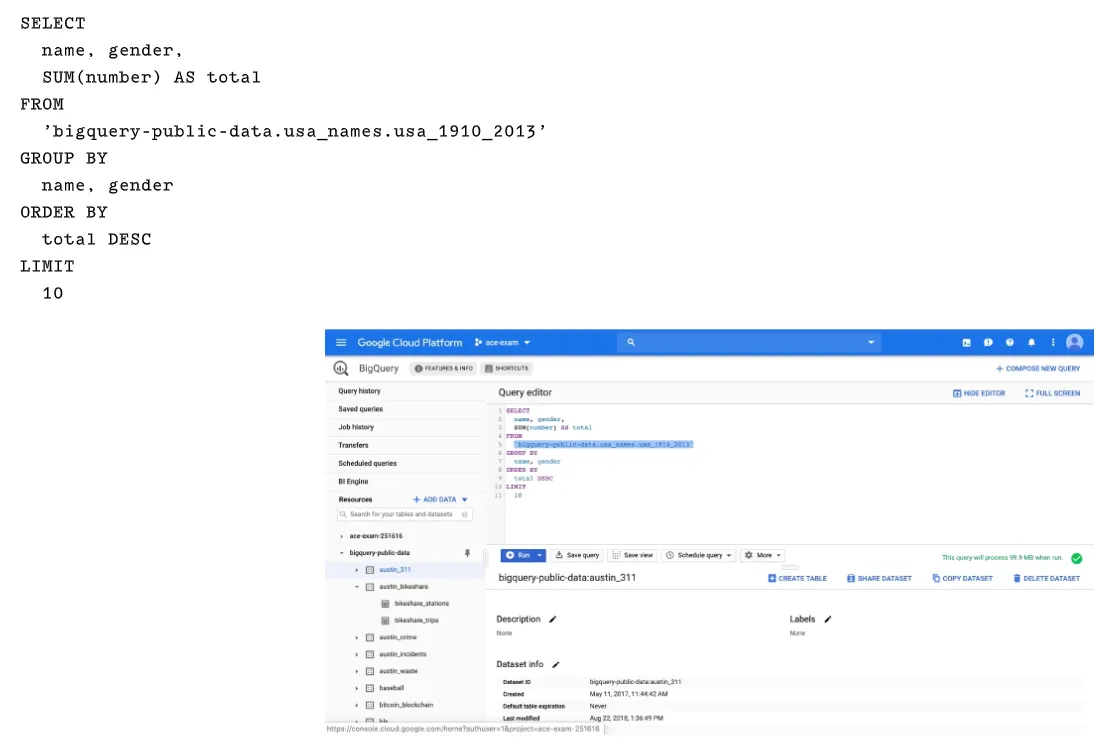
用過SQL語法的人應該很熟悉這一類的語法。唯一不同的是 FROM的table name必須要用full path來指定, 由三種資訊組成
'project_name.dataset_name.table_name'
你也可以在bq command-line模式下使用SQL與法來查詢,如下範例

BQ支援兩種不同的語法 , legacy 跟standard。建議上使用Standardm語法。Standard SQL支援advanced SQL feature,像是 correlated subsqueries, ARRAY與 STRUCT的data type,也支援complex join expressions.
BQ使用一種slots的概念來分配運算資源執行Query. 大部分的人使用預設的slot來查詢資料是足夠的,不過如果你是很非常大量的data query(一次處理的資料不超過100G)或是有很多人經常同時會做查詢,就會需要額外的slot來增加效能。整個slot(預設是2000) 的資源是以GCP的project來計算的.
載入與匯入資料
在現有的datasets中你還可繼續create table並將資料載入。你可以使用UI 或command 介面來做資料查詢,在做查詢時你需要明定以下資訊
- 資料來源: 可以是Cloud storage, 本機上傳檔案, Google driver, Cloud Bigtable, 跟 Data transfer service(DTS)。
- 檔案格式: Avro, CSV, JSON(newline delimited), ORC, or Parquet. 你也可以從Cloud Firestore的exports載入資料。
- 如果你要匯出到另一個BQ table,就要 project_name.dataset_name.table_name三種資訊
- Schema,這個可以被自動偵測import的檔案 ,明定在文字檔案中或是每個column單獨輸入並且要指定column name/type/mode. Mode有三種 NULLABLE/REQUIRED/REPEATED.
- Partitioning, 可以要或不要做partition. 如果需要做partition就要以ingestion time來分割。如果table是有partition的,你就可以使用clustering order,這一個功能可以優化column data儲存跟Query的效能。你也可以使用WHERE語法來查詢特定的partition以加速查詢速度並節省查詢費用。
BQ在接收資料檔案時會認定它收到的是UTF-8的編碼格式,如果你的CSV檔案不是URF-8格式BQ會試著covert。 但coveret可能永遠不會是正確,所以載入CSV檔案前還是需要檢查一下編碼。但JSON就一定要是HTF-8, BQ不會幫你covert.
Avro檔案則是BQ匯入資料的完美檔案格式(它沒有UTF-8編碼問題),因為data的block可以被平行處理的讀取到BQ中,並且當按在壓縮狀態中也可以被讀取。不過CSV/JSON則是要解壓縮後讀取資料的速度才比快(因為它們無法被平行處理讀取資料)。Parquet也是用cloumn mode的方式來儲存資料。
BQ的Data transfer service則可以從Google的各項服務自動的將資料載入BQ,例如Google Ad manager, Google Ads, Google play, YouTube channel Report. 當然也可以從AWS S3載入資料。
Cloud Dataflow也可以直接將資料載入到BQ中。
Clustering, Partitioning and Sharding Table
BQ提供一種稱為clustered table的功能,它是基於資料的 內容會把一個以上的cloumn 組成一個資料有相關的cluster table. 這樣的作法可以在某些Queries加快讀取的效能,特別是在查詢使用到cloumn來filter row的方式。Cluster tables也可以被partation. 如果你的資料量很大分成很多個小的partation才會加快查詢效能。我們可以用date or timestamp來分割資料。如果是用attribute將資料分割到數個table我們則可以用sharding功能。
sharding利用一種稱為template table,這種table也有定義好的schema只是它是放在template中,這個template會用來create一個或多個以上的table 而這些table會有targer table name與table suffix這些資訊。 target table name就跟在create BQ 的table一樣的table名稱,但 table suffix在create table時會有一些不同。
Streaming Inserts
上面提及的都是Batch loading. BQ也支援streaming insert。但BQ是一個 Data warehosue的solution, 它還是適合analytical的作業而不是transactional作業。
streaming insert提供的是一種best effort de-duplication. 當我們insert每一筆資料(row)時會我們需要對每筆資料有"insertID"來確認資料不會有重複的狀況。但如果該筆資料沒有insertID的話,哪BQ就沒有辦法偵測是不是資料有重複。如果有使用insertID並使用de-duplication功能,哪麼每秒鐘只能寫入100MB資料並且小於100,000 筆row。如果de-duplication沒有enable哪insert資料就可以拉到每秒1GB並且是低於1,000,000筆資料。
使用template tables的好處是你不用預先create全部的tables。例如你有一堆的火災感測器 device每一個device都要有一個table,你可以把每個火災感測器 device的辨識ID當成是suffix ,當第一筆資料進來資料 table會從template自動被create.
所以用Standard SQL來作wildcard的table name來查詢會變得很容易。例如你的table name的命名規則是 ‘fire_device_’ + <device_id>, 哪這一堆device的名稱就可能可以是 fire_device_001, fire_device_002, fire_device_003等。你就可以用where 語法來作查詢全部的devices,範例如下
FROM ‘fire_project.fire_dataset-fire_device_*’
但wildcard不能使用在view or external tables.
Monitoring and Logging in BQ
BQ的相關監控是使用GCP stackdriver的監控服務。Stackstriver Monitoring提供效能量測,像是query counts and time. Stackdriver Logging 是用來追蹤events,像是running job or create table. Stackdriver monitoring 監控一些以下的維運面的監測資料
- Number of scanned bytes
- Query time
- Slots allocated
- Slots available
- Number of tables in dataset
- Uploaded rows
你可以在stackdriver monitoring上建立dashboard來追蹤關鍵的效能指標,像是跑最久的查詢作業跟95% query time.
stackdriver lgooing追蹤的events其實就是log entries。Events 有 resource type (project or datasets)跟type-specific attributes, 像是storage events的location. 可以追蹤的指標如下
- Inserting, updating, patching, and deleting tables
- Inserting jobs
- Executing queries
BQ的費用
使用費有著這些的計算,儲存的總容量,被stream data的總容量,被執行query的工作負載。但這些數字其實是很動態的,意思是你都是下個月收到帳單才會知道花多少。但是了解這些基本的資訊是幫你選擇怎麼樣的場景才是有效的使用BQ並能在一定費用的控制上。不過也有免費的:loading/copying/exporting data. 另外還有個別在BQ之外計費服務的,BigQuery ML machine learning service(BQML) ,是BQ原生的Machine learning服務。還有BigQuery Data transfer service也是獨立計費的。
BQ的優化重點
雖然BQ好用效能也很好,但是它如同之前講的是以一些用量來計費的,所以如果你的用法跟設計上不得當然後它當成地端機房的服務用的話,哪麼下個月的帳單保證會讓你嚇到吃手手。所以有一些要點如下
- SQL語法盡量不要用 SECLECT *
- 使用參數 — dry-run 來預估Query的費用
- 設定計費的最大bytes數
- 盡可能用時間來切Partition
- 將資料denormalize也不要用join table(雖然BQ還是有支援)
盡量不要用select *的原因是,這會scan某一個table或view裡所有的column. 你應該要明確的select你要的column才對。如果你真的要看table/view裡的全部cloumn,你應該要使用BQ提供的preview功能(在GUI介面 )或是bq的head功能,它類似Linux 的head功能,是擷取整個table前面幾筆資料。當然也有人會說也要看前幾筆資料也可以用LIMIT這個語法,但是它還是scan 整個table(沒有效能又多花錢),只是dispaly前幾筆資料。
如果你想要確認這一次的Query會花多少錢,你可以在BQ的GUI介面的Query validator上看到。或是使用 bq query 加上 — dry-run 的參數來查看。
如果你想要限制每次Query最大的資料量以避免大量費用產生可以設定計費的最大bytes數。這個設定在於如果你在Query時,scan的資料量超過你原先的設定,哪麼這一項作業就會失敗並且不列入計費。這一項設定可以在 BQ GUI設定或是 bq query 的命令列參數加上 — maxium_bytes_billed.
而盡可能用時間來切Partition。這會幫助我們不用scan到整個table的資料。BQ會在partition table create pseudo-colum稱作_PARTITIONTIME,這個可以被用在WHERE的句型上使用,避免我們scan table的全部資料。例如我在where 條件這邊要找 2021年四月一整個月的資料,我們的可以寫成如下語法
WHERE _PARTITIONTIME
BETWEEN TIMESTAMP(“20210401”)
AND TIMESTAMP(“20210430”)
BQ支援nested 跟repeated structure。Nested data在SQL是以STRUCT type呈現,而repeated data 則是ARRAY type。
Cloud Memorystore
這是一個全託管式的Redis服務,通常是要做資料的cache。你在create Redis instance可以透過GCP的GUI介面或gcloud命令列。在create時有以下資訊需要指定
- Instance ID
- Size spefification
- Region and zone
- Redis version
- Instance tier, basic的沒有HA功能,standard有failover replica而且是在不同的zone
- memory的容量可以從1G到300G
如果我們還要再做一些細部化的設定,例如maximum memory policy, eviction policy,像是least frequently used可以在Redis configuration做參數修改.
Redis也support資料的import /export。資料會以檔案的形式export到cloud storage的bucket. 在export的狀態時,資料對Redis的read/write還是持續,但有一些管理性的操作就不被允許,例如scaling. 而在將資料import到Redis cache時所有的read/write不被允許,而原來在該Redis cahce裡的資料將全部被overwrite.
Cloud Memorystore裡的Redis cache可以擴展用更多的memory或是縮小使用。當擴展到basic等時,過程中read/write都不能用。resize的動作完成後所以cahce裡的資料都會被清掉。但當你從basic 變成standard時,過程中你所有資料的read/write 操作仍然可以持續。這是因為replica會先被啟用然後將資料持續同步從primary instance(原來basic 等級的),然後primary 跟replica的角色互換。雖然write operation在升級過程中是有支援的,但是若你的write operation的loading很重。你就會觀察到升級的過程可能要等久,所以建議在不是peak time時再來做升級比較好。
當Redis 使用的系統的memory達到80%時,Instance會認為它已經到達壓力點了。為了避免這個問題有幾種方式解決,可以將instance升級(有更多的memory使用),或降低instance的最大memory 使用量(例如拉到85%),或修改eviction policy, 或在volitale keys設定TTL參數, 或手動在instance裡將資料刪除。TTL的設定是指你的key可以在這個cahce裡存活多久。frequently updated的值應該小於TTL值而key的值(這個值不會經常變更)可以有很大TTL。有些eviction policies的目標只有key有TTL值的而其他的policies瞄準其他的key。如果你發現你的 memory常常會面臨到壓力點,你當前的eviction policies僅適用於具有TTL的key,並且有些key不具有TTL,然後切換到以所有key為目標的eviction policies可能會減輕部分memory壓力.
Eviction policies可以有好多個,當memory的使用率到達最大後根據這些policies一順序來決定要先移那些key. 預設上Redis會先移除最近最少用到的key。其他的選項還有移除最不常用的key或隨機選key來移除。
這雖然是一個全託管的服務,但我們還是需要監控它。特別是memory usage, duration periods of memory overload, cache-hit ration, 跟有多少的expirable keys.
Cloud Storage
這是一個Object storage system。用來儲存非結構化資料,像是Video/images/ backup file/ data file等等。很像你在地端機房用的file server,但是不一樣的是file server是將檔案放在block storage device。而放在上面不論甚麼樣的檔案都是會被cloud stroage當成是atomic的。所以你在cloud storage access檔案時,你access是整個檔案。它讀取檔案的方式不像哪種file server的以block level來讀取檔案。所以每一個放在Cloud storage的檔案都是一個Object.
Organizing Objects in Namespace
Cloud storage有一個階層式的結構。Cloud storage使用bukcte來放object,而你可以在bucket level這邊做Access control ,每一個bucket 的access control都是獨立的。例如GCP的VM的service account有對一個bucket write的權限,對另一個bucket有read的權限。而在bucket裡的object的權限預設都是跟bucket是一樣的,但你也可以針對單一的object設定權限。
而Cloud storage是使用一種稱作Global namespace的方式來為bucket命名,所以每一個bucket的name都是unique,而object的name則不用有unique。bucket name在create時就好決定後,因為create後就不能改名。唯一能做的就是create新的bucket,然後copy object到新的bucket。
Google有以下bucket的命名建議
- 不要使用你的個人識別資料,例如你的名字/email/ip address等等。因為bucket name是公開的會被有心人士收集資料。
- 使用DNS命名慣例,因為bucket name會在DNS CNAME的record中
- 如果要create一堆bucket,使用globally unique identifiers(GUIDs)
- 如果你要upload 一堆檔案並且想要平行處理寫入這一堆檔案到cloud storage,檔案名稱不要有順序性或是用timestamp當檔案名稱 。因為這樣會造成hotspot的狀況。
- bucket name可以是subdomain name,例如 mybucket.example.com(先確認這個doamin是你的)
Cloud storage因為不是使用filesystem的方式,所以它不像你再在用本機電腦或file server的方式可以讓你用檔案路徑/檔案夾名稱來瀏覽整個檔案目錄結構。如果真的要這麼做可以參考Cloud storage FUSE功能。
Storage Tiers
Cloud storage提供四種等級的服務。
- Regional
- Multi-Regional
- Nearline
- Coldline
Regional level會將你每一個object 複製成很多份,散在這個region的所有zone。所有的Clous storage Tier都提供High durability(達到99.999999999%),意思是當你儲存檔案(例如1000個object)平暈每一千萬年才會lose掉一個檔案。
能達這種程度的durability(11個9)是因為一個object在底層機器會複製成很多份。另外一個就是Avalability,這是指object可以被access的能力。如果只有durability沒有availability,哪object只是存在於Cloud storage而你無法去存取它。例如Cloud Storage or GCP的網路發生問題了,哪麼這時object就失去了availability.
Multi-Regional level 減低當一個GCP的region失去了它的availability,而我們仍可以在多個其他的region去access我們檔案。這除了能加強我們的cloud storage 的availability另外也因為object是在多個不同的region,網路的latency就會更低。例如你是一間跨國公司(分屬歐洲與台灣),Cloud storage上面的資料全公司都會用到但放在哪個GCP的region好像都會讓另一邊的latecny變高。使用multi-regional的方式,哪麼兩邊都會access離自己最近的region.而兩邊之間object的同步則由Clous storage來負責。而create bucket可以在各自的region 上create,Clous storage一樣會負責同步。同步的速度取決於兩個region之間的網路速度。
上面我們提到我們要去access object的網路latency我們是用public Internet network infrastructure來估算的。我們知道public internet網路提供的是best-effort,意味著這是不穩定的。所以Google提供了兩種不同的網路層級服務: Standard and Premium。 Standard使用的是public Internet network infrastructure所以這中間的網路狀況與路由不是Google能決定的。兩邊region的資料同步可能就沒哪麼快。另一個是Premium,你用的就是Google在全球的自己拉海底電纜的網路專線。效能與速度一定是比Internet還要好。
Nearline / coldline等級的storage服務大都則是拿來放不常使用的檔案資料。Google的建議是少於於30天內會access的data放Nearline storage, 少於一年的放coldstroage. 所有等級的Cloud Stroage服務在取得資料的first byte的網路latecny都是一樣的,意思是當你access 這些檔案時你不會感覺因為他是放在coldline而覺得馬上要看到它會很慢,但重點在於你去存取這些不同等級的服務價錢都是不一樣的。所以Cloud storage的管理工作與AWS S3的服務比起來是簡單的多,準備作業也不用哪麼複雜(下圖為比較表)。

而在Availavility的部分GCP保證的各等級的availability SLA如下
- Multi-regional 99.95%
- Regional 99.9%
- Nearline / Coldline with Multi-reginal 99.9%
- Nearline / Coldline with Regional 99%
資料保存與其生命週期管理
資料都會有它的生命週期,從create, active use到不經常使用但需要保存它最後可能要刪除它。可能不是所有都資料都會經歷所有應該走的階段,帶是做好storage planning是非常重要的.
大部分我們所用的storage system technology 並不會直接影響我們的資料抱存與生命週期管理,但它可能會對我們要實施的data policies會有衝擊。例如: Cloud Storage的lifecycle policies可以是object在一段時間沒有使用後可以移到Nearline or Coldline storage. 又如當partition table使用在BigQuery時,單一的partition可以被刪掉而不會影響其他的partition 也不中斷你在做full table scan這種耗時的作業。
如果我們要儲存資料,要先考慮它有多常被存取以及它須要多快被存取。以下是一些建議
- 如果你的資料要被access 的時間是屬於 sub-millisecond 的話,使用cahce服務(Cloud Memorystore)
- 如果資料要被經常存取跟update而且還要屬於持久性儲存的話,使用Database. 在Relational 跟NoSQL之間是用資料結構來決定,如果你的schema需要動態性變動請選NoSQL.
- 如果資料被access的可能性越來越小哪麼資料就會變得越舊,哪麼將資料儲存在有support time-partition table的功能。通常會使用BigQuery,而Bigtable也有類似使用時間的特性來組織它的tbale.
- 如果資料不是經常被access也不需要用語法來查詢它,可以使用Cloud storage. cloud storage可以被用來在Database 已經很難用到的資料,然後會被DB export出來的儲存地。但當有需要時可以再次被import到DB中。
- 當你的檔案想要封存(類似以前資料磁帶)並且省錢時可以將資料放在cloud storage 的nearline/coldline等級服務。
Cloud storage有提供object lifecycle management policies的功能,這個功能可以根據你定的規則將object自動調整成的storage 服務等級或刪除它。這些policies是被assign到bucket level的。這些policies的rule也可以根據object的age被trigger , 像是保留幾個object的最新版本或一開始要放哪種等級服務。
另外一個data management的控制是retention policies. 這是使用在Cloud storage bucket的bucket lock功能上來強制object 的retention. 這個功能可以指定某個bucket中的所有object都不能被刪除,直到 object的age到了之後。這個設定特別適合用在政府單位或產業的規範中,當rention policy是設定lock它就不能被撤銷了。
自我管理的Database
雖然GCP提供了這麼多託管式的DB服務。但可能出各種原因你還是要自行管理DB(就是將DB安裝在GCP的VM上),這意味著你有一大堆的管理工作要做(如下)。
- Updating and patching the operating system
- Updating and patching the database system
- Backing up and, if needed, recovering data
- Configuring network access
- Managing disk space
- Monitoring database performance and resource utilization
- Configuring for high availability and managing failovers
- Configuring and managing read replicas
如果是這樣的話,哪麼監控的工作就必定不可少。使用Stackdriver的Monitoring and logging就是必要的。Monitoring監控一般性的指標,例如CPU/memory/Disk IO等,這在你create VM instance就已經內建可以看到了不用做特別的設定。但如果你想要看到Application layer(Database)的效能指標的話你就需要安裝 Stackdriver Monitoring and Logging agents.
Logging agent可以收集application log(包括Database log),Stackdriver Logging使用Fluentd(log的open source collector)配置。
Monitoring agent 則收集Application 的效能相關數據,但需要搭配相對DB的plugin,例如MySQL / PostgreSQL.
