Google Cloud — GKE的使用指南

GKE是GCP所提供目前市面上最成熟的Container orchestration服務。即使沒有GKE相關的使用經驗,GKE也提供了Autopilot 的操作模式來協助沒有經驗或無專責的IT人員的組織來運作GKE服務。GEK同時也提供了領先整個K8S業界的多項功能,如 release channels, multi-cluster, unique four-way auto scaling, node auto repair等,並且可以在單一個K8S cluster中支援高達1萬五千個nodes。
GCP的現代end-to-end平台建立在我們都熟悉的雲原生(cloud-native)原理之上,並以與其他雲端平台以極大的差異的方式優先考慮速度、安全性和靈活性。
本篇將作為您開始 GKE 開發之旅的參考指南,涵蓋從code到build到run再到operate和manage的所有內容。 即使您是第一次使用 GKE,這也是一個很好的參考,重點介紹重要的注意事項和最佳實踐。 通過實施技術建議、遵循步驟並利用本篇文章中提到的工具,您可以實現以下目標:
- 使用GCP的Cloud Code與 Cloud Shell可以加速我們代碼的編寫,佈署與除錯(Debug)。
- 使用GCP的Cloud Build持續整合(CI)並交付Updates
- 在GKE下能夠簡易的,安全的,具成本效益的進行大規模運作
- 使用 GCP的 operations suite來除錯(Debug)與障礙排除(troubleshooting)
Code — 使用K8S的開發人員工具
為了專注在編碼,開發人員需要正確的工具來排除需要管理Infrastructure的工作。使用能幫助我們提高開發效率的工具開始在 GKE 上編碼,並且能夠在熟悉的IDE中更快地編寫、部署和debug。
使用 Cloud Shell 開始 Kubernetes 的應用開發
當我們開始使用 GKE 進行開發時,需要記住以下幾點。 任何擁有 GCP account的人都可以 access cloud-based IDE,包括以下:
- Cloud Code : IDE plug-in,可幫助開發人員在開發雲原生應用程式時保持高效
- Minikube : 在Cloud Shell可以運作單一個node的K8S cluster,以方便開發人員進行測試
- Cloud Build Local Builder: 一個可以運行我們 CI(continuous integration) 流程的工具
在我們覺得舒服熟悉的地方使用GKE進行開發
如果我們想要在自己的機器運作我們的K8S application,我們可以使用Cloud Code進行本地開發。Cloud Code可以佈署到我們的 Docker Desktop或是建立minikube cluster。
Cloud Code同時也能夠將我們的K8S Application佈署到遠端的K8S cluster來減輕本機的負載。這個遠端的K8S clutser可以是 GKE或者是自建與其他第三方的Cluster。
開發人員最具生產力的時間就是在他們熟悉的IDE環境中進行編碼。Cloud Code的內建功能可以加速此一開發人員的工作流程。更重要是context switching不僅浪費時間而且容易打斷開發人員的心流(也就是高度專注力)。Cloud Code 通過包含無需干預的hot-code reloading來減少這種context switching,因此我們可以在開發系統中即時查看changes update。 它可以整合 Kubernetes Explorer,可幫助我們查看和debug應用程式資源。
使用 Cloud Code 內建的log viewer, Kubernetes 的開發將更容易、更輕鬆。 通過one click revision和service logs,它使查看每個revision的logs變得更簡單。
獲得有關雲原生配置和工具的協助
Cloud Code讓我們有更多的時間在編碼而花較少的時間在配置我們的Application,透過authoring support features,例如 inline documentation, completions與schema validation,也就是”linting”。隨著 Kubernetes 變得越來越流行,許多開發人員使用新的operators和 CRD(Customer Resource Definitions) 擴展了 Kubernetes API。 這些新的 Operator 和 CRD 通過CI/CD、機器學習和網路安全等新功能擴展了 Kubernetes 生態系統。 Cloud Code 支援 400 多個開箱即用的 Kubernetes CRD,同時提供authoring support,以便更輕鬆地編寫、理解和查看 YAML 中各種 Kubernetes CRD 的錯誤。 Cloud Code 強化的authoring support讓我們可以通過建立符合 CRD 的resource file來利用此自定義 Kubernetes 功能。
作為開發人員,我們希望專注於編寫代碼,而不是將其容器化。 Buildpacks 是一種開源技術,可讓我們快速輕鬆地從source code創建安全的、可用於生產的container image — 無需 Dockerfile。
通過hot-reloading的雲原生應用程式可以快速迭代
創建 Kubernetes-native Applications的開發人員花費大量時間管理多個conatiner registries構建和管理container images、手動更新其 Kubernetes manifests,並在每次進行最小的代碼異動時重新部署其應用程式。 Cloud Code 和 Skaffold 是自動化這些重複性任務的關鍵。
Skaffold 簡化了我們在 Kubernetes 上開發時執行的常見操作任務,讓我們專注於代碼變更並快速查看它們在cluster上的狀況。 啟用 Skaffold Watch mode可監控local source code的變動,並即時重建應用程序並將其重新部署到我們的cluster。
Cloud Code 還處理將port從我們的 Kubernetes Application轉發到我們的local machine,以便我們可以使用local browsers和client端輕鬆查看我們的 UI 和 API 並與之交互。
即時的除錯(Debug)
在 Kubernetes 開發過程中,快速有效地修復錯誤通常很困難。 Cloud Code 可讓我們即時的debug,在開發時為我們節省寶貴的時間,並允許我們以與本地相同的方式debug Kubernetes services。 使用 Cloud Code,我們可以簡單地在代碼中放置breakpoints。 在應用程式中觸發該code path後,我們可以一步步執行code、將滑鼠停在變量屬性(variable properties)上並查看容器中的日誌。
Build-CI/CD
當大量開發人員在相關系統上工作時,協調code updates可能是一個大問題,不同開發人員的變動可能不相容。 CI(continuous integration)的實作允許開發人員盡可能頻繁地將所有代碼改回整合回主要分支,通過在流程中儘早發覺問題以更快地顯示失敗之處。 CI pipeline包括validate changes的步驟,例如 linting、testing和building。
CI pipeline通常會生成一個artifact,我們可以在部署過程的後期階段使用CD(continuous delivery)進行部署。 CD 可讓我們隨時發布新的代碼。 CD 對 CI pipeline產生的artifact進行運作。 CD pipeline的運行時間比 CI pipeline較久,尤其是在我們使用更複雜的部署策略時。
為了更清楚地說明這一點, 下圖顯示了使用 GCP工具處理在 GKE 上運行的容器的 CI/CD pipeline的整個流程。

創建支援快速迭代的Pipeline
從開發人員更改代碼的版本到Application運行版本之間的時間應該盡可能短。在開發快速迭代的feature branches時,速度尤其重要。通過實施自動化構建過程以及在幾分鐘或更短時間內運行的automated unit tests的套件,我們可以獲得對軟體按時程上線的信心。
Cloud Build 是 GCP的 CI/CD 平台,可以通過多種方式幫助推動快速反饋。首先,我們可以在每個branch上觸發 CI。小批量工作還可以確保開發人員定期獲得有關其工作影響的feedback。其次,由於 Cloud Build 允許我們為每個project運行多個concurrent builds,因此我們可以優化構建速度,進而優化開發人員的工作效率。第三,我們可以從四種高效的 CPU 虛擬機類型中進行選擇,以提高構建速度。最後,Cloud Build 允許我們使用 Kaniko caches container 構建artifacts。通過在container image registry(例如 GCP的GCR)中存儲和索引intermediate layers, Kaniko 使它們可供後續構建使用。有關更多信息,請參閱使用 Kaniko cache。
將一切視為代碼(code)
CI/CD 的一個核心原則是,應用程式所有內容的實際來源都應該呈現為resource repo中的文本(text)。這意味著應用程式本身、documentation、runtime policy和config — — 以及關鍵的是,交付應用程式的 CI/CD pipeline— — 都以相同的方式進行變更與管理。這允許將所有 CI/CD practices 實行在對應用程式所做的任何更改。和source code一樣,所有變更都通過 Git 進行管理,這反過來又標準化了工作流程、簡易的rollback以及詳細的稽核。
Cloud Build 允許我們以多種方式執行“一切皆為代碼”的想法。首先,對於 Cloud Build,容器被視為第一級物件。其次,每個構建步驟都在 docker conatiner中作為 docker run 的一個實例執行。構建步驟指定我們希望 Cloud Build 執行的操作。第三,Cloud Build 提供了預建立好的images,我們可以在 Cloud Build 配置文件中引用這些images來執行我們的工作。
在Pipelines中及早確認安全性問題
在開發生命週期中儘早實施安全性檢查很重要。 DevOps Research and Assement(DORA) 的研究表明,通過在構建artifacts或deploy之前發現安全性風險,我們可以減少解決這些風險所花費的時間和成本。 為了及早發現風險,我們可以在pipeline中實施以下安全措施:
從被批准的代碼來建構(build):
讓資安團隊建立預先審核過的、易於使用的libraries、packages、tollchains和processes,供開發人員和 IT 維營人員在他們的作業中使用。
弱點掃描:
軟體漏洞可能導致意外的系統故障或被利用。 這正是 Cloud Build 創建的images會自動掃描漏洞的原因。 它支援Linux商業版的package vulnerability scanning,並從Debian、Ubuntu、Alpine、National Vulnerability Database、 Red Hat Enterprise Linux、Red Hat和CentOS等來源獲取CVE資料。
不要佈署含有弱點的images:
這需要部署時有安全控制機制,以確保僅部署受信任的container image。 例如,通過整合 Binary Authorization 和 Container Registry vulnerability scanning,我們可以將基於弱點掃描結果的部署作為整體部署策略的一部分。 Binary Authorization還允許我們要求來自不同實體或系統的驗證。 例如,這些驗證可能包括以下內容:
- 通過弱點掃描
- 通過QA測試
- 有Product owner的簽名
以下為一個示意範例流程,在佈署到K8S環境前經過一些資安驗證的確認

投資一個無伺服器(serverless)的CI/CD Pipeline
近來,無伺務器解決方案已被證明是不可或缺的。 各種規模和行業的組織都利用無伺務器解決方案來推出全新產品或服務並提供新功能來回應市場需求。 特別是,無伺務器的按pay-per-use以及自動擴展使IT團隊能夠在降低維運費用的同時滿足激增的需求。 我們已經看到越來越多的 CI/CD pipeline交付到無伺務器運行時,主要是因為企業不想花費寶貴的IT資源(人力/設備)來構建、維護和維運他們的應用程式交付時所需要用到的IT基礎設施。
Cloud Build就是這一種 serverless 的CI/CD pipeline,它可以根據負載進行擴展和縮減,無需預先配置服務器或提前支付額外容量。 最重要的是,使用 Cloud Build,我們只需為使用的內容付費。
衡量正確的改進指標
你無法衡量的,你就無法改進。 因此,擁有正確的指標來衡量軟體開發和交付實踐的有效性至關重要。 DORA 已確定並驗證了一組可推動更高軟體交付和組織績效的功能。 這些指標包括:
- 佈署的頻率 — 我們有多常成功的將軟體發布到正式環境
- 變更的等待時間 — 從我們下達佈署指令時到正時環境時,總共花了多少時間
- 變更的失敗率 — 我們佈署到正式環境的失敗比率為何
- 又回到第一步,佈署的頻率 — 我們有多常成功的將軟體發布到正式環境
借助以上四個關鍵項目,我們可以衡量這些指標,並不斷迭代以改進它們。 這樣,團隊就可以取得明顯更好的業務成果。 四個關鍵項目會自動設置從我們的 GitHub 或 GitLab repos通過 GCP的服務進入 GCP DataStudio 的資料匯入管道。 然後它會匯總我們的資料並將其編譯到包含這些關鍵指標的儀表板中,我們可以使用這些指標來追踪一個區間時間內的進度。
Run — GCP GKE
Google Kubernetes Engine 是一個用於部署容器化應用程式的託管環境,它帶來了我們在開發人員的生產力、資源效率、自動化運作和開源靈活性方面的最新創新,以加快我們的上線時間並降低我們的IT基礎架構成本。 借助 GKE,我們可以輕鬆管理和解決組織業務在速度、規模、安全性和可用性方面的需求。
這個部分將概述在 GKE 中運行應用程式時的一些重要注意事項,以及可幫助我們在安全性、具成本效益且最終更簡易的運作 Kubernetes workload的工具和功能。
運行更容易
運作和管理 K8S Cluster可能具有挑戰性。 雖然“從頭開始”使用cluster可能是一個很好的學習練習或一些特殊需求的程式的好的解決方案,但通常可以通過使用託管服務來簡化cluster管理的細項工作。 GKE通過方便的工具和整合以及將 K8S cluster作為託管服務提供的便利性,使運行 K8S變得更加容易。
此外,隨著 GKE Autopilot 的推出,GKE 使用者可以選擇標準或Autopilot,每種模式都提供了我們可以控制程度。 Autopilot 是一種無需干預的全託管 K8S服務讓我們可以更多地專注在我們的程式,而不是管理Cluster infrastructure。
運行是安全的
GKE 提供並使用各種工具來控制整個 K8S infrastructure的可訪問性,從而實現安全、零信任的環境,在這個環境中,每個使用者只擁有他們應該有的access level — — 僅此而已。 使用 GKE,我們可以:
- 透過 K8S的namespace與RBAC我們可以細緻化控制使用者訪問cluster
- 使用GKE沙盒(sandbox)來隔離一些POD(可能是我們還不信任的程式)
- 使用network policies或 Anthos Service Mesh來控制Pod與Pod之間的連線
- 使用 Workload Identity 限制 pod 到 GCP 的access
- 使用policies來防止偏離我們的的security baselines
更多的GKE的security harding,可參考GCP的文件庫。
運行是具成本效益的
通過在整個團隊中提升成本意識文化來實現工作負載(以及隨後的業務)來達到成本和效能之間的平衡。 雖然在我們的雲端旅程開始時只考慮成本很誘人,但了解我們的應用程式在其中運行的環境的功能則更重要。
在 GKE 中找尋成本、效能和可靠性之間的平衡意味著調整自動縮放、機器類型、區域等功能和配置。正確的配置取決於我們的工作負載的性質,如果我們了解我們的工作負載,我們將獲得最佳成果工作負載的特徵(例如,面向終端使用者的應用程式、批次處理作業等)並將它們與環境的功能相匹配。 最後,我們必須監控我們的花費並建立一種圍欄,以便我們可以在開發週期的早期實施最佳實踐。
以下是將上述考量視覺化的整理

從強調開發生命週期早期成本優化的文化基本開始,GKE 通過自動擴展和調整機器大小等功能進一步提高成本效率,並讓我們根據工作負載類型配置環境。
運行是可以大規模的
在 Kubernetes cluster中,可擴展性(scalability)是指cluster在保持其SLO(Service Level objectives)的同時又能增長的能力。 K8S是一個複雜的系統,其擴展能力由多種因素來決定。 其中一些因素包括在一個node pool中node的類型和數量、一群node pool的類型和數量、可用的 Pod 數量、資源如何分配給 Pod,以及服務或服務背後的backend數量。 GKE 是可擴展性最強的 K8S服務,支持 15k node cluster。 以下是一些重要的設置,可幫助我們開始大規模運行:
- 對正式環境使用regional cluster
- 永遠使用 VPC-native 的網路
- 使用Private clusters來避免不必要的大量外部IP
- 使用 NodeLocal DNS cahce來避免DNS可靠度問題
- 經常升級並儘可能嘗試在最新版本上運行(同時仍然要平衡升級與更長的發布作業時間的需要)
管理Cluster的網路
K8S 讓我們以聲明式(declaratively)的方式定義應用程式的部署方式、應用程式彼此之間以及與 K8S control plane的通訊方式,以及client端如何access我們的應用程式。 以下是一些在開始使用 GKE 網路時需要牢記的最佳實踐:
- 使用 Shared VPC網路與VPC-native clusters。在我們建立cluster後就無法再變動VPC 的設計
- 管理我們的IP區段。GKE cluster是 IP address-intensive,需要對subnet分配和連接選項要有很深入的了解。 create cluster後,我們通常無法擴展 IP address的分配。
- 牢固我們的GKE cluster。一些安全性建議包括使用private cluster、VPC firewall rules和Network policy。 使用這些Network policy template可以快速上手。 下圖顯示受信任的用戶能夠通過public endpoint與 GKE control plane進行通訊,因為他們是授權網絡的一部分,而不受信任的人的access被阻檔。 進出 GKE cluster的通訊通過control plane的private endpoint進行

- 規劃服務的規模和接觸點。NodeLocal DNSCache, CloudNAT, and container-native load-balancing是建議運用在大規模的服務中的
- 確保雲端維運者有相符的IAM roles。因為這些人需要有正確的管控權限
- 運用Network Policy logging 與 GKE annotations for VPC Flow Logs來觀察cluster內的網路traffic
OPERATE — 監控與故障排除
監控與故障排除是在K8S後續維運時不可缺少的重要部分,但它可能會讓沒有專責維運人員的組織無法專注在開發自己的程式上。以下我們會描述一些概述的最佳實踐來提供一種兼顧的方式來收集和使用有關系統和應用程式運行狀況的資料,同時保留開發人員和維運的時間和費用。
建立或使用日誌管理系統
當我們的應用程式遇到問題時,日誌會提供有關時間點事件的資料,使我們能夠進行故障排除、執行根本原因分析(RCA)和修復。 當我們的環境擴展到數百或數千個容器時,這一點尤其重要。
雲端平台提供工具來自動擷取系統日誌,例如audit logs和service logs,但是對於自建的K8S cluster,我們就需要自行建立一個日誌管理系統(見下圖),以便我們的應用程式日誌可以被擷取並導出到分析/可視化工具。
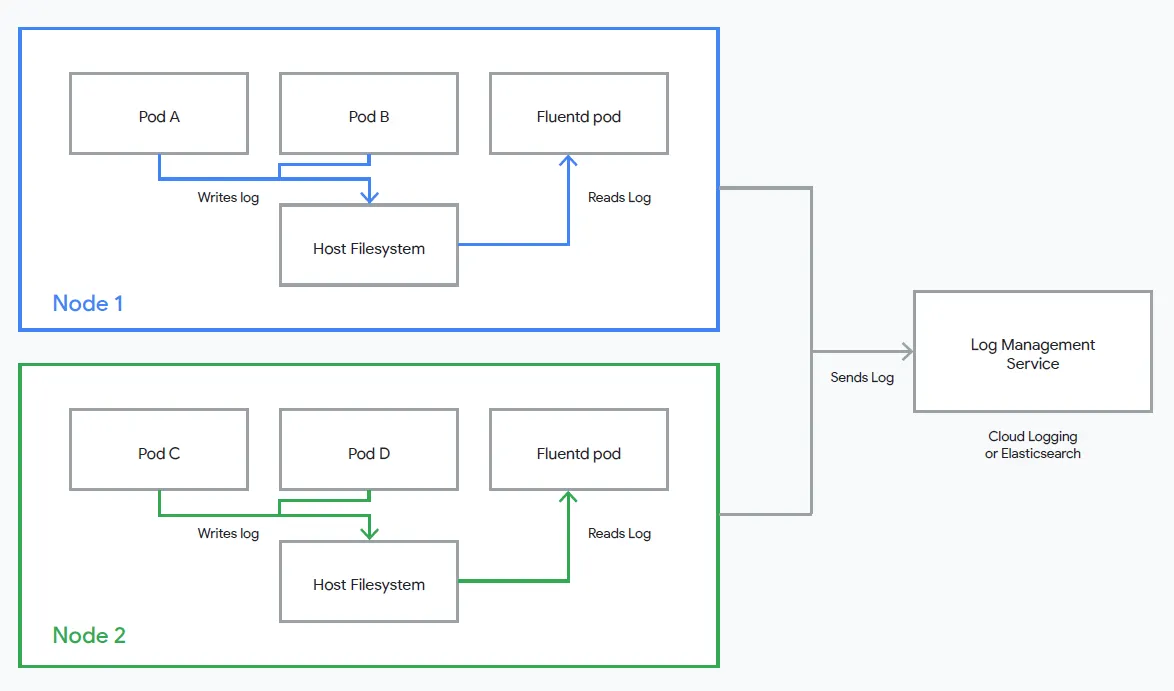
GKE 這類的託管式 K8S 服務預設提供日誌管理系統。 當我們部署託管的k8S cluster時,會安裝每個node的logging agent,該agent讀取容器日誌、添加metadata,然後將它們存儲在persistent datastore中。 K8S cluster中的資源是動態的,意思是資源經常會被刪除與重建,因此需要將這類的資料存放到persistent datastore,這樣日誌就不會不見。
我們需要設定在容器上運行的應用程式,以便logging agent擷取它們的日誌。 GKE logging agent會檢查來自容器化processes、kubelet、container runtime logs和系統組件日誌的standard output(stdout) 和standard error logs(stderr) 中的日誌。 為了確保我們的容器應用程式日誌被擷取,需要使用容器的native logging mechanisms並將結構化日誌(如 JSON objects)在一行上序列化到上述 stdout 或 stderr。 或者,我們可以使用慣用的logging library來擷取應用程式日誌,因為 GKE 中整合了多種開發語言runtime。
當我們準備好分析我們的日誌時,我們可以使用 kubectl 命令來簡易的查看,但我們還是需要一個日誌管理服務來進行更複雜的查詢、過濾。 如果我們使用的是 GKE 服務,則可以使用服務的內建日誌記錄工具來分析日誌。
主動進行有效的容器監控
監控可幫助我們快速識別出現問題,以便我們可以找到受影響的資源並對其進行故障排除。
K8S cluster有許多component,了解每個component是必須的。 因此,我們應該使用儀表板,或使用來自託管 K8S 服務的開箱即用的儀表板,這使我們能夠按每個 K8S component查看我們的整體服務:cluster、namespace、node、workload、services、pod 和containers。 為了調查隨時間發生的問題,我們應該能使用時間區間的方式來filter resources。 對於每個資源,我們應該看到資源的顯示名稱、該資源及其子資源的告警的顯示愈確認的數量、容器重新啟動、錯誤日誌計數、CPU 使用率、memory使用率和 pod 的disk使用率 等這些可以被歸為資源的component。
當我們有這種精細度的監控指標時,就要建立告警服務,以便在指標超出可接受範圍時收到主動通知。 雲服務原生的監控工具可以進行深度整合,讓我們可以從告警連結到相關的監控儀表板,然後從該儀表板連結到資源日誌,從而更快地解決問題( 下圖為Cloud Monitoring 的 GKE 儀表板示意圖)。
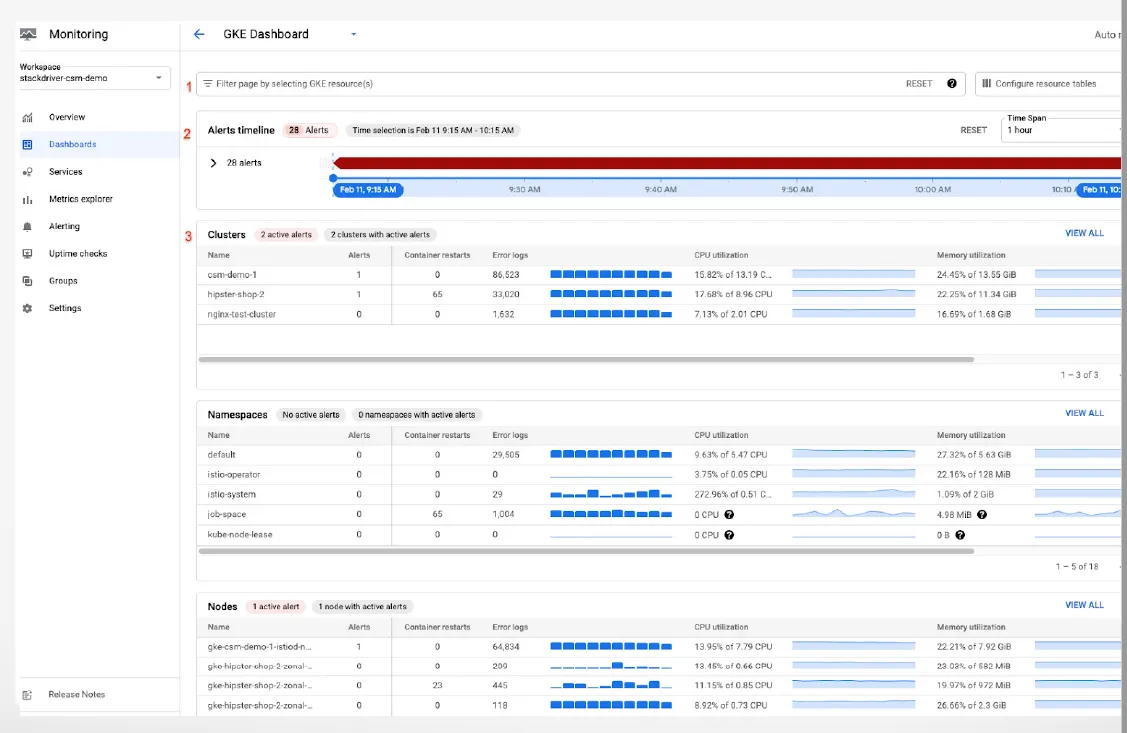
上圖中的 GKE 儀表板。 紅字1) 篩選器欄位,用於選擇儀表板內要篩選的 GKE 資源,紅字2) 整合告警的時間線,紅字3) clusters、namespaces、nodes、workloads、services、pods 和conatiners的詳細細分。
將監控提升到一個新的水平
主動監控和告警對於標記問題很有用,但它們可能無助於推動開發團隊和維運團隊之間的共同責任感,開發人員尋求更快地發布新功能,維運團隊努力提高穩定性。 SLO(Service Level Objectives)是兩個團隊共同負責實現的應用程式或服務正常運行時間的協議結果。 除了有助於組織業務的成功之外,SLO 還減輕了解決不會導致超過SLO的告警的負擔。
檢測我們的應用程式以取得深度的可視性(observability)
應用程式中的單一operation稱為spans,構成transaction的operations集合稱為trace。 當我們的應用程式被監控以擷取和導出日誌時,我們可以監控和排除trace的latency。
使用開源的遙測工具(例如 OpenTelemetry )來檢測我們的應用程式以實現trace observability。 許多開源項目和雲端平台業者(例如 GCP的 operations suite,之前叫stackdriver)都整合在一起來擷取log資料。
提高應用程式的開發速度和為大規模運行做準備可能是我們選擇使用容器的一些原因。 這些最佳實踐為開發團隊或 DevOps 團隊在快節奏的大規模環境中快速有效地採取行動奠定了基礎。
總結
若組織沒有專屬的維運團隊或人員,開發團隊可以利用本篇所說的指導原則來開發與維運GKE,以此簡化end-to-end的開發:
- 加速在K8S上的開發 時間— 使用如 Cloud Code這類工具來讓開發人員專注於程式開發使其更具生產力
- 促進K8S的開發效能 — 使用GCP的CI/CD工具使從一開始的程式開發到佈署到生產環境的的作業自動化
- 運作K8S更簡易 — 使用 GKE Autopilot 或Standard 模式,具體取決於我們希望對 K8S cluster的靈活性與控制程度。
- K8S大規模的可視性 — 使用GCP的operations suite來處理GEK上的workload。
