Google Cloud — 資料的儲存與處理服務

Storage對於OS來說可以分為Block與File。Block就是OS要掛載的HD,File就是類似我們一般企業中的File Server。
Block Storage

通常來說一個Block Device(HDD)只能同時掛載給一個OS,而一個OS卻可以掛載多個Block Devices。但是有時也可以掛載給多個OS,通常該Device只有read-only,不過也有一些特殊技術可以讓多個OS對同一個Block Device進行write/read。
在一般的資料中心或雲端平台中,Block device分為以下兩種
- DAS(Direct-attached storage) — 就是一台伺服器(肚子)中的HD
- SAN(Storage Area Network) — 透過高速網路連接到一個Storage Pool
File Storage

類似透過網路的檔案分享方式,在地端機房中通常透過CIFS協定來分享檔案。
GCP的Block與File服務

GCP上的Block storage為Persistent Disk,而File storage則是Filestore。Persistent Disk走的是NAS的方式(Network Block Storage),並且有兩種模式:
- Zonal: 資料會在通一個Zone裡被不斷複製,以防某個硬體損壞
- Regional: 資料會在不同的Zone被複製,以防某個Zone(Data center)掛掉
GCP — Block Storage
在我們啟用GCE時,有兩種的block storage可供選擇:
- Local SSDs — 這可以存放暫時性的資料,因為如果掛載的該台VM掛掉或停機。裡面的資料就會消失。但不是所有的Machine type都有支援。
- Persistent Disks — 這是存放長期資料,並且是受到保護的。
Local SSD的特點有:
- 它的效能比Persistent Disk還高(High IOPS/Low Latency),因為它是在機器的肚子裡。所以它是個Ephemeral storage。
- 如果因為底層的機器維護事件,VM Live Migration會幫我們將這裡的資了轉移到新的Host
- 裡面的資料是自動加密的,我們無法對其做任何的設定變更
- 其生命週期是跟隨該台VM instance
- 只有某些GCE machine type有支援
- 支援SCSI and NVMe interfaces(選擇有啟用NVMe與 multi-queue SCSI 的images才有最佳的效能)
- 所需要的空間越大,就需要越多的vCPU
Local SSD的優缺點是:
- 優點:
高效能 — IOPS是PD的10–100倍(只適合儲存暫時性的資料,例如拿來當cache用) - 缺點:
既然是暫時性的storage,與PD相比就不會有durability/availability/flexibility。另外無法把這個storage從該台VM上attach/detach
Persistent Disk的特點是:
- Network block storage
- Provisioned capacity
- 有彈性的 — 根據需求來變更大小(不需從VM detach),HDD size越大效能越高
- 與VM的生命週期是分離的
- 可以是在zone裡,也可以是存活在Region(但是zone PD的兩倍價錢)
以下是Local SSD與Persistent Disk的功能比較表

另外Persistent Disk有三種類型的HDD可以選擇,其比較表如下:
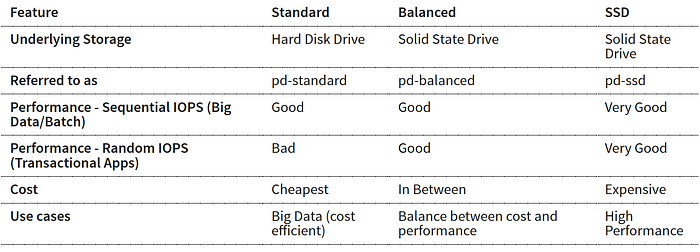
Persistent Disk的快照(Snapshot)
所謂快照就是一個point-in-time的資料。GCP的快照可以使用排程的方式自動進行與刪除(如刪除幾天後的快照),而其快照可以存放在一個Region或同時放在多個Region。並且快照可以share給其他的GCP project。
而我們可以從快照製作出VM instance或其他VM的附屬Disk。GCP的快照是incremental,但刪除其他日期的同一份快照不會影響其資料完整性。PD適合儲存長期的資料,意思是不要把資料存放在OS Disk中。
以下是使用PD的一些建議:
- 快照的頻率不要太頻繁(不要低於一小時一次),因為快照時意味著效能降低。所以快照的時間點應該選擇系統不忙碌時進行。
- snapshot的來源可以是Disk or Image,但是使用Disk做snapshot的速度會快於Image
- 但是若我們要從snapshot變成Disk,建議是snapshot →Image →Disk
以下為一個當我們要給一個正在運行的VM一個新HDD時的步驟範例(以Linux為例):
- 用gcloud command
gcloud compute instances attach-disk INSTANCE_NAME — disk DISK_NAME - 之後在該台VM的OS中
sudo lsblk
sudo mkfs.ext4 -m 0 -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb - Mount Disk
建一個目錄來準備來準播掛載HDD
sudo mkdir -p /mnt/disks/MY_DIR
掛載Disk
sudo mount -o discard,defaults /dev/sdb /mnt/disks/MY_DIR
給予write/read權限
sudo chmod a+w /mnt/disks/MY_DIR
掛載好之後如果要修改HDD大小,步驟大概是:
- gcloud compute disks resize DISK_NAME — size DISK_SIZE
- 保險起見,先對其建立一個快照
- ext4 : sudo resize2fs /dev/sdb
xfs : sudo xfs_growfs /dev/sdb
甚麼是Machine Image?
Machine image跟Image不同之處在於:
- Machine Image包含了該台VM的所有Disk(Boot Disk與其他Data Disk),還有該台VM的Configuration/Metadata/Permissions。
- Image只有Boot Disk。
所以Machine適用用來對Disk做備份,或是複製整台VM。以下是各種GCP的備份型態的使用場景
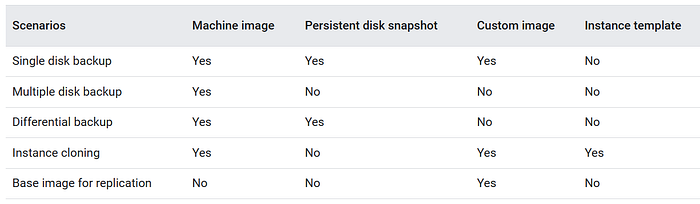
另外一些使用PD的需求場景的解決方案如下:
Cloud Filestore
基本上就是GCP的託管式的NAS。支援NFSv3 protocol,並需要先配置容量。Firestore最高可以達到320T的容量,並且具16 GB/s throughput與480K IOPS。支援HDD (general purpose) and SSD (performance-critical workloads),不過HDD無法達到最高效能與容量。
關於GCP中各項resource的範圍
以下是各項resource在GCP中的範圍:
Global
- Images
- Snapshots
- Instance templates (但如果template有zone resource,就會成zonal了)
Regional
- Regional managed instance groups
- Regional persistent disks
Zonal
- Zonal managed instance groups
- Instances
- Persistent disks(只能掛給同一個Zone的VM)
另外根據不同的storage使用需求與場景也有不同的解決方案(如下表):

Object Storage — Cloud Storage
我們可以把它看成是一個永遠放不滿的file system,並且不用預先配置容量,用多少算多少。而與一般的file system不一樣的是,它是object storage。所謂的object是指除了檔案本身之外還包含了該檔案的metadata,例如該檔案的URL link或檔案大小等等。每一個Object可以有自己的Access control設定。
與其他類型的storage type比起來,Cloud Storage算是最便宜的。所以也是很多企業開始使用雲端第一個會開始用的服務。因為把它拿來當備分服務,很多備份軟體也與這一類的Object storage有高度整合。
Cloud storage使用key-value方法儲存大物件(也就是一個大檔案)。所以整個物件是視為一個Unti(不允許部分更新 — 要嘛整個刪掉要嘛整個覆蓋)。所以適合我們要對一個Object進行整體的修改。
另外針對Cloud storage的操作有API/command line tool — gsutil/ client library。
Cloud Storage架構 — Objects & Buckets
基本上每一個object(檔案)都必須存放在某一個Bucket(我們可以把它看成folder)中,所以要存放檔案需要先create bucket。bucket有以下的功能與限制:
- Bucket names必須是globally unique。也就是說buckst名稱在整個GCP服務中,不可以於其他人(客戶)相同。
- Bucket names 會是object URLs的一部分。 所以名稱的限制只能是英文小寫、數字、連字號、底線和句點。
- 3–63 的字元名稱。不能以 goog 前綴開頭或不應包含 google (甚至拼字錯誤)
- 在bucket裡的object是沒有數量限制的
- 每一個bucket只能掛在一個project裡
- 在每一個bucket中的object必須是unique key(也就是不能有重複的檔名)
- 單一Object的大小最高可以到5TB
Storage Classes
如果我們有對資料做分級分類,哪麼我們就可以將資料存放到不同等級的storage classes。這麼做的最大目的是省錢,另一個目的是根據合規需求做一些資料存放的動作。
Cloud Stroage的durability of 99.999999999%(11 9’s),意味著在正常的情況下(沒有天災人禍之類的),資料每一百萬年才會不見一個檔案。以下是Cloud Storage使用上根據不同的使用情境來使用不同的Storage Classes。

其中關於Minium storage duration,意指資料最少需要存放的天數。例如我們把資料放在nearline storage中最少要放30天,如果沒有放超過而我們把檔案刪掉了,GCP還是要跟你收30天的錢(也就是低消)。另一個是availability,Region/dual region/multi region更有不同的可用性指標數字。
不論是哪一種等級的Cloud Storage,它們都有著以下的特點:
- High durability (99.999999999% 單位: 年度)
- Low latency (first byte typically in tens of milliseconds)。這跟AWS 的S3 classess不一樣。
- 無限的儲存空間(不需要最小的儲存量,沒有資料在裡面就沒收錢)
- 都可以使用API的方式來操作
- 保證的SLA,Standard/Nearline/Coldline在mutli region是99.95%,single region是99.9%
檔案版本(Object Versioning)
主要是防止誤刪檔案,另一個也可以根據稽核/合規要求來檢視檔案變更的歷史紀錄。尤其是重要檔案。如果要啟動此功能,需要在bucket level中啟動,並且隨時可以開啟/關閉。關閉此功能的話,舊版本的檔案不受影響。
如果我們刪除舊版本資料,哪它就是真的被刪除了。如果是刪除的是現有版本,哪麼該檔案就不會出現在bucket的檔案清單裡了。我們必須要檔案版控哪邊去指定一個舊版本成為目前版本的檔案。而舊版本的檔案(也就是key),也是需要一個唯一值(object key + a generation number)。
另外版本號越多儲存的費用就越高,所以需要適合的做house keeping或啟用lifecycle management來進行自動化管理。
Object Lifecycle Management
我們在地端機房的時代,通常都會做data archive。把一些歷史資料(不會用到的檔案),儲存到磁帶中,避免浪費硬碟空間。在雲端時代也是一樣的做法,只是更加的自動化與智慧化。
而GCP針對Cloud Storage的自動化管理則是提供Object Lifecycle Management的服務。可以根據一些條件,例如Age, CreatedBefore, IsLive, MatchesStorageClass, NumberOfNewerVersions等等,採用OR 或AND的方式來決定要進行的動作。進行的動作為以下兩種:
- SetStorageClass (將檔案從一個等級移動到另一個)
- Deletion (刪除檔案)
可以移動的等級方向如下:
- (Standard or Multi-Regional or Regional) to (Nearline or Coldline or Archive)
- Nearline to (Coldline or Archive)
- Coldline to Archive
我們可以觀察到,移動的等級只能往下不能往上。以下為一個Life management的規則範例。

加密(Encryption)
預設中,Cloud storage會把存放(收到)進來的資料進行加密,也是就在server side進行。而在server side的加密,Cloud Storage提供了三種模式:
- Google-managed
預設選項,我們不用做任何動作。key的產生與保管還有加解密,GCP全部都在背景中幫我們執行。 - Customer-managed
使用Cloud KMS來進行key的管理。有一點比較重要的是,當我們這樣做時GCS Service Account必須要能存取KMS服務。這樣才能對資料加解密。 - Customer-supplied
針對每一次的data operation,我們都需要給GCS 一個key來進行資料加解密。並且每次執行完畢後,GCS都不會保留該key。這種作業方式通常是要用API來執行的。每次API call的header長得像這樣
x-goog-encryption-algorithm, x-goog-encryption-key (Base 64 encryption key), x-goog-encryption-key-sha256 (encryption key hash)。如果是使用gsutil command,則需要在 boto configuration的GSUtil section設定encryption key。
上面不管哪一種方式,GCP都會知道加密的key。所以若是不信任Cloud Provider,我們也可以在地端加密完資料後,再把資料丟進GCS。這個稱為client side encryption。
Metadata
每一個Object都會自己的metadata,長得大概如下圖所示。
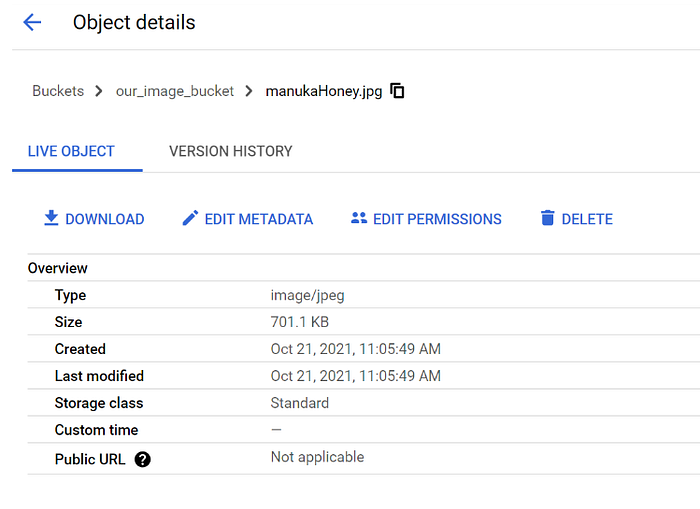
我們可以看到,metadata的組合是key-value pair的組合。例如:
storageClass:STANDARD。而有些是Fixed-key metadata,也就是我們無法更改Key的值。因為哪是GCS已經固定好的。範例如:
- Cache-Control: public, max-age=3600 (要啟用cache功能嗎?如果有要開多久)
- Content-Disposition: attachment; filename=”jasonfile.pdf” (內容應該顯示在瀏覽器中還是應該作為可以下載的附件)
- Content-Type: application/pdf (Object應該是甚麼樣的內容)
當然,為了對資料資產進行各個公司的管理。GCS也可以客製化(新增)key-value pair的meatdata。當然,也有一些metadata是我們根本我法去更動的,如Storage class of the object, customer-managed encryption keys等。
Bucket Lock(合規需求)
通常是不讓任何人(包括GCP的admin)去更改特定bucket內的檔案,以備稽核之用。像是加密過後要歸檔的財務資料之類的。我們必須在buckte的設定中配置"data retention policy",這是指檔案過了多久之後才可以併刪除或覆蓋。一旦retention policy被lock之後,裡面的檔案:
- 無法刪除retention policy或縮短(但可以增加)保留時間
- 除非bucket中所有object的age都大於保留期,否則無法刪除這個bucket
Retention policies與Object Versioning是互斥的功能。所以一個bucket只能同時挑一個功能來開啟。
將資料傳送到GCS中
通常我們都是將資料由地端傳送到GCS中。GCS提供了一下幾種方式讓我們使用。
- Online Transfer:
使用gsutil cmooand或API。通常是一次性的傳送。 - Storage Transfer Service:
大量的資料傳送(可能是PB等級)。來源可以是地端機房/AWS/Azure或其他的GCS。這個服務可以設定重複性的排程作業,並且是incremental transfer (只傳送有異動的檔案),並且支援"續傳"功能。 - Transfer Appliance
使用AES 256 加密— Customer managed encryption key
一種實體裝置。跟AWS snowball一樣。
gsutil適合傳送小於1T以下的資料,大於1T可以用Storage Transfer Service。但大於20T的話則建議用Transfer Appliance。
Cloud Storage的最佳實踐
- object name與bucket name不要含敏感的資訊
- 盡量將資料存放於靠近user的region。如果不行的話,則建議啟用CDN功能
- Request Rate是逐漸增加的。對Object有1000 write requests per second或5000 read requests per second是沒甚麼問題的。但如果要在翻倍往上家的話,就需要停20分鐘後再進行。
- 不然的話我們會看到5xx (server error) 或429 (too many requests)的錯誤。這時就要運用Exponential backoff 的機制了,例如在1,2,4,8,16…秒後再試。
- 另外Object key(也就是檔名),不要用有順序的數字(可以用has value)或timestamp(可以用完全亂數的)當檔名。
- 如果我們想把GCS的bucket當作一個share folder給GCE使用,可以使用在該VM安裝Cloud Storage FUSE。
常用的使用場景

資料庫(Database)的基本概念
在了解GCP裡的各式資料庫的種類與型態之前,我們需要先了解一下資料庫的一些基本知識以及根據維運需求選擇正確的資料庫類型/大小/要求等等。我們在設計資料庫時,關於一些Infrastructure的要求大概有以下幾種:
- Availability
- Durability
- RTO
- RPO
- Consistency
- Transactions 等其他

通常在傳統的地端機房的維運中會遇到許多挑戰,像是機器掛了怎麼辦?機房燒掉了怎麼辦?又或者資料庫本身掛了怎麼辦?等等的這一些都會讓資料永久的消失。
通常我們可能固定時間(例如每小時),做一個snapshot然後把它傳送到另一個Data center(如下圖)。這一種方式也許可以解決我們資料可能完全遺失的問題,但這麼做可能也會造成效能問題(因為執行快照時)。
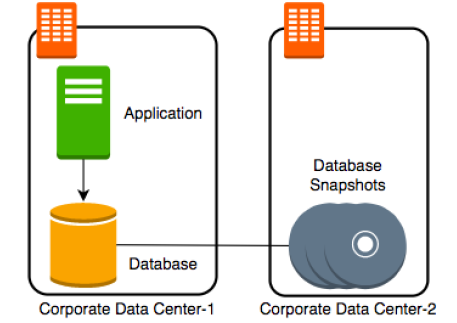
如果要減少效能問題,但又不想遺失太多資料。哪我們可能就會較長一段時間作snapshot(如一天一次),其他時間就傳送交易紀錄(transaction logs)到另一個資料中心,在哪邊replay整個交易。如下圖所示。
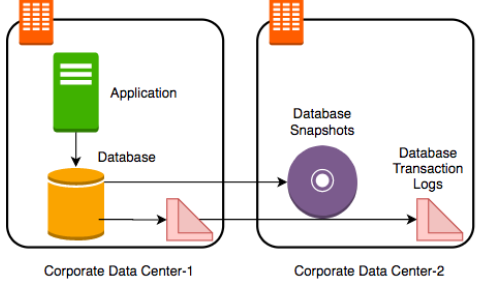
以上都是解決資料可能遺失的方法。但是資料庫本身的服務在哪當下是無法運作的。所以大多數的公司針對重要的資料庫都會有備援(stand by) DB(即時的同步資料)的做法(如下圖),這樣可以一次解決資料遺失/效能/服務掛掉的問題。因為這一台備援DB的的存在,資料的備份都可以在這一台備援機上執行而不會影響主要DB的效能。
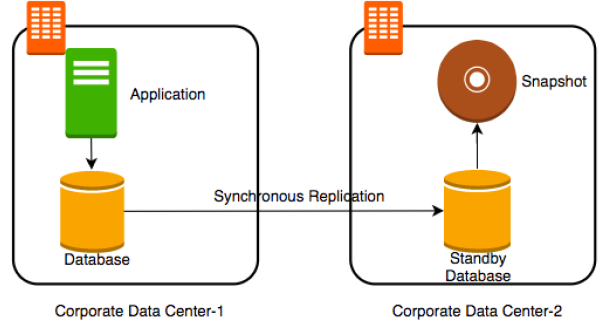
根據上述的這一些狀況,我們會帶出兩種概念。資料庫的
- Availability: 想使用時可使用時間(一個期間)的百分比(4個九為最佳)
- Durability: 資料可以存在多久? 10年?50年?(11個九為最佳)
以下為Availability的對照表

為了達到資料庫的Availability與Durability。DB instance本身與其資料就會同時在不同的GCP Region/Zone裡存在(Replicating data),藉以達到這兩個目的。
RTO與RPO
哪麼我們應該如何評估這一類的業務要求呢?通常就會出現以下兩種指標:
- RPO (Recovery Point Objective): 可容受的最大資料損失(例如一天)
- RTO (Recovery Time Objective): 可容受的最大停機時間(例如一周)
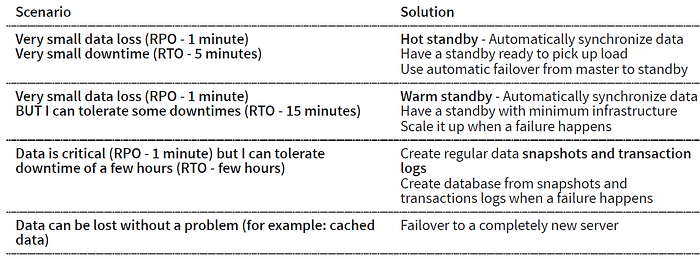
這兩種指標的期間要越短,企業所要花的代價就越大。所以在設計資料庫時,通常是根據不同系統的業務需求做出一種權衡(trade-off)的設計。下表為一些RTO/RPO的要求範例以及相對應的可能解決方法。
當企業有一堆資料之後,自然而然的就會開始想做資料分析了。傳統的方式就是在同一個資料庫同時資料交易(write/read)與資料分析(read-only)的行為發生(如下圖)。
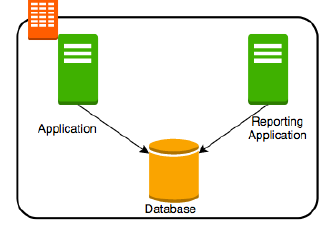
這麼做通常會發生很嚴重的效能問題。通常的解方有:
- 垂直式擴充(Vertically scale) — 同一台機器不斷往上加CPU/Memory(但有其極限)
- 弄一個DB cluster(資料進行分散) — 但通常很貴且設定與維運都可能很複雜,一般中小企養不起也沒這樣的人才
- 搞一個read replicas — 也就是弄一個DB的分身,讓資料分析的系統去讀取(如下圖)
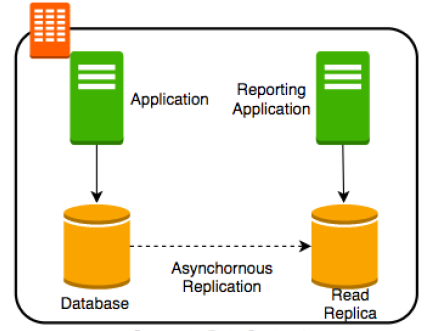
這個read replica DB可以在不同的Data Center並進行備份任務甚至承擔備援的角色。但我們可以看到,這種資料是非同步的方式在進行的。也就是主要與次要資料庫的資料存在一定的時間差。如果read replica有很多個,哪時間差會更嚴重。這會產生一個議題: Data Consistency。
以下是三種Consistency的模式:
- Strong consistency — 將資料同步到所有的次要資料庫。但這樣會很慢,因為主要DB要確定資料都寫到Read replica。
- Eventual consistency — 資料是非同步式的。也就是主要與次要資料的的時間差可能是幾秒。在傳輸階段,不同的次要資料庫可能會傳回不同的值
。會用到這一種模式通常是可擴展性比資料完整性更重要時。 - Read-after-Write — 資料的insert後可以馬上讀取到。但是,資料的update將具有Eventual consistency特性
資料庫的類型
由於資料型態與使用方式的不同,DB的類型有很多。像是Relational (OLTP and OLAP)、Document、Key Value、Graph、In Memory等等。
通常我們會根據以下的需求來選擇要用哪一種類型的資料庫。
- DB 是 Fixed schema還是schemaless?
- transaction properties level是甚麼?(atomicity與consistency)
- 延遲程度(seconds, milliseconds or microseconds)?
- transactions的數量。每秒一百次還是一百萬次?
- 存放的資料有多少(MB? GB? TB? PB?)
可能還有其他可能的因素我們也需要一併考量。
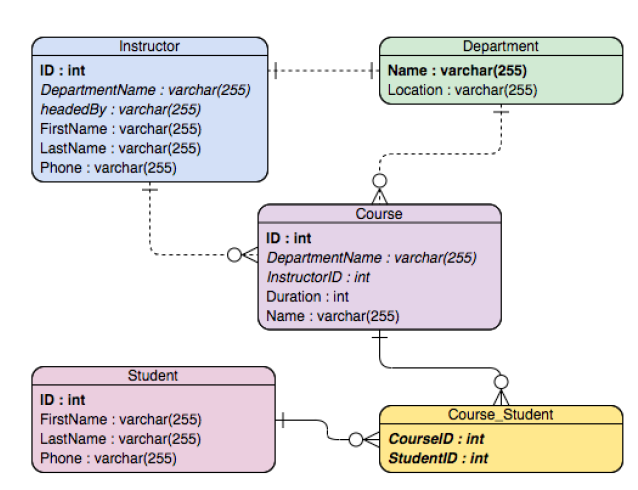
如果是Predefined schema並且每個table的主從關係清楚還要strong transactional能力的。通常就會是關聯式資料庫(Relational Databases),如上圖所示。而關聯式資料庫還會分為OLTP (Online Transaction Processing)與OLAP (Online Analytics Processing)。
Relational Database — OLTP (Online Transaction Processing)
這是用在有很多的User,他們的data transaction是小量而多筆的。像是電商、ERP、CRM、銀行交易系統等。這一類的資料庫比較常聽的像是MS SQL server,MySQL或Oracle等。在GCP中,這一類的託管服務為Cloud SQL與Cloud Spanner。
- Cloud SQL :
目前有PostgreSQL, MySQL與SQL Server 這是Regional DB(可儲存好幾個TB資料) - Cloud Spanner:
水平擴充式的DB (PB等級) 。因為它的DB cluster可以跨Region,所以 availability可以到99.999%
Relational Database — OLAP (Online Analytics Processing)
這是專門用來分析資料的DB,通常分析的都是PB等級的資料。GCP提供的這一類託管服務為BigQuery。
雖然OLTP與OLAP的資料結構相同,但差異點在哪呢?下圖應該可以讓我們一目了然。

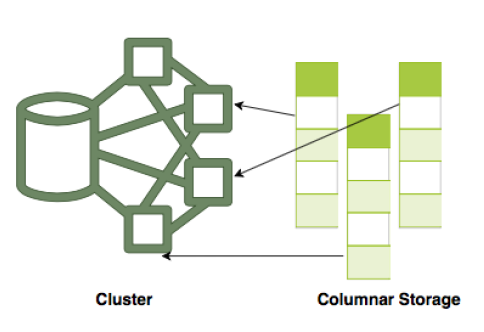
OLTP是Row based storage,而OLAP則Columnar。Row based適合小量且多筆的資料交易。而Colummar則適合分析的原因在於:
- 每一table的column是存放在一起的
- 並且每一個column是存放在不同的機器中
- 因為同一個column的資料的型態與性質很高,所以可以進行高度壓縮
- 也因為資料是用cloumn的方式打散到不同的機器中,所以單一次的Data Query是同時使用多台機器的資源(如下圖所示)
NoSQL Databases
如果我們的DB的schema需要有很高的修改彈性(schema可以視需求進行修改),哪就需要用到NoSQL DB。NoSQL 意思是not only SQL。NoSQL是以數百萬 TPS(Transactions per second) 水平擴展至 PB 等級資料。
NoSQL是犧牲了關聯式資料庫的Strong consistency特性,來達成scalability 與high-performance。GCP的NoSQL託管式服務有 Cloud Firestore與Cloud Bigtable。
Cloud Firestore與Cloud BigTable
兩者的特點與分別如下:
Cloud FireStore — Managed serverless NoSQL document database
- 具有ACID transactions、SQL-like queries、indexes
- 適用用來當行動通訊或web application平台的資料庫(有提供Client libraries)
- 具strong consistency的能力
Cloud BigTable — Managed, scalable NoSQL wide column database
- 需要管理DB Cluster
- 適用於10TB到幾個PB等級的資料量
In-memory Databases
GCP提供這一類的全託管服務稱為Memory Store(99.9% availability SLA),並且直接與Cloud Monitoring直接。這一類的快取可以讓我們降低直接對DB存取資料的延遲。因為從記憶體中檢索資料比從磁碟檢索資料快得多。
Memory Store提供了兩種 In-Memory DB:
- Memcached — 資料的快取,通常容許資料消失(因為可以再從DB複製)
通常是Reference data, database query caching, session store 等等 - Redis — 低延遲存取、持久性和高可用性。基本上可以直接拿來當DB使用。
只要是GCP的computing服務都可以存取memory store服務。以下是一個App engine使用memcached的範例。

Memcached有兩種service lelve:
- Shared memcache (不用錢): 但是它是best-effort caching。效能無法保證
- Dedicated memcache (要錢的): 跟GCP圈一個固定的resource來用
資料庫總結
根據以上的各種的資料庫介紹介紹我們可以整理出以下的資料表。
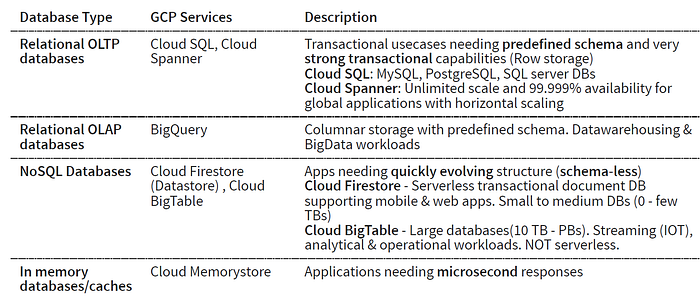
根據不同的使用場景,我們也可以選擇不同的GCP服務(如下表)。
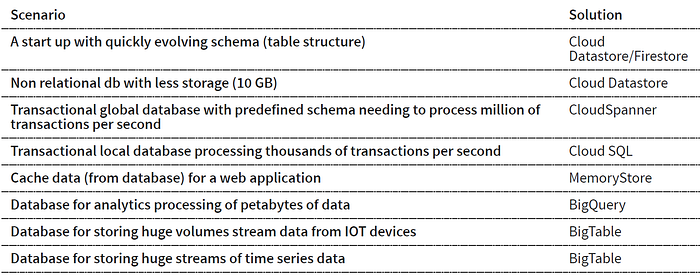
Cloud SQL功能介紹
Cloud SQL是一個Fully Managed Relational Database service。目前有MySQL、PostgreSQL、SQL Server等三種DB。它是一個Regional service,所以可以達到'99.95%的高可用度。我們可以選擇HDD or SSD來當層底的資料儲存,其規格最多可以有416G memory / 30TB資料量。
重要功能
- encryption (tables/backups)/maintenance/updates都是自動化的
- High availability與failover功能
設立stand by與auto failover
需要先啟用Automated backup與Binary logging - 支援Read replicas
Replica可以Cross-zone, Cross-region跟External。一樣要啟用Automated backup與Binary logging。 - Automatic storage increase without downtime
- Point-in-time recovery: 啟用 binary logging
- Backups (Automated 與on-demand)
- 使用Database Migration Service (DMS)來遷移到其他地方
- 可以將資料匯出web console / command line等方式
高可用度(High Availability)
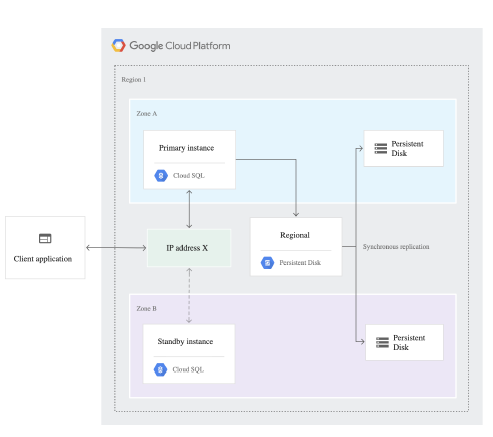
HA的能力是跨Zone的(如上圖所示)。資料是同步(synchronously)到次要節點。如果primary zone掛掉,GCP會自動failover到standby。另外standby 不等同於read replica。意思是standby 與 replica是兩種不同目的的節點,需要個別建立。
最佳實踐
為了安全性,使用Cloud SQL proxy來介於Application與Cloud SQL之間。而Cloud SQL的可擴充性:
- HA(standby node)功能是Regional的
- Read replica可以減輕資料讀取的負擔,但無法增加可用性
- Cloud SQL instance盡量不要搞太大。用多個、小的instance來取代一個超大的instance
Cloud SQL的的backup是一個lightweight並且是point in time recovery(所以花的時間很少)。而且無法backup整個Database或某個table(而是某一個Instance)。當我們刪除某個DB instance,該備份也會同時一併被刪除。
而Export則與backup相反。它花的時間很長,但是可以export 整個Database或某一個table。不過如果export的資料庫很大,哪在這過程之中會衝擊到DB的效能。所以建議使用serverless export (flag — offload),Cloud SQL會建立另一個暫時性的instance來做這件事。避免衝擊主要的DB。
Cloud Spanner功能介紹
該服務的DB cluster可以跨Region(也可以在同一region)。所以通常會用在很重要的系統上,因為它提供99.999%的高可用度。
- 在Globl scale上提供Strong transactional consistency能力
- 透過自動分片(sharding)將資料擴展到 PB 等級
- 資料的write/read也是水平擴展的。Clud SQL只能對一個node寫入資料,但Spanner可以對多個node同時寫入資料
- 它很貴(跟Cloud SQL比),用nodes & storage來計價
Cloud Datastore and Firestore功能簡介
Datastore — Highly scalable NoSQL Document Database
- 根據資料的成長自動的scales跟partitions data
- 只試用於資料量只有幾個TB的(大於這個建議使用Bigtable)
- 支援Transactions/Indexes/SQL like queries (GQL),但不支援Joins與Aggregate (sum or count)
- 交易(transaction)是需要有彈性的schema(像是產品目錄)
- 架構: Kind > Entity (使用 namespaces 把entiy群組起來)
- 只能用gcloud將資料匯出。資料會含metadata
Firestore(強化版的datastore)
- offline mode和跨多個裝置的資料同步 — 行動裝置、物聯網等
- 提供client library — Web、iOS、Android 等
- 有Datastroe mode和Native mode
Cloud Datastore是一個document store(flexible schema功能)。在設計keys 與indexes需要注意:
- key不能是有序的。像是1,2,3,4,5…或A,B,C,D,E…。所以要用使用 allocateIds() 取得well-distributed numeric IDs
- 只針對需要來create index。對於沒有預先定義index的大型資料集的即時查詢,建議使用 BigQuery
- 用batch operations(single read, write or delete operations)。這是有效的查詢方式。
Cloud BigTable功能簡介
是一個Petabyte scale, wide column NoSQL DB (HBase API compatible)。這是針對有大量資料的分析操作,例如IOT Streams, Analytics, Time Series 這類的資料。針對數百萬的read/write TPS提供非常小的延遲。另外只支援Single row transactions而沒有multi row。
另外它不是serverless的,所以需要設定Cluster。另外在修改cluster大小時不會有downtime時間。如果要匯出資料,web console/gcloud都不支援。只能用Java application (java -jar JAR export\import) 或HBase commands。command line只能用cbt。
Wide Column Database
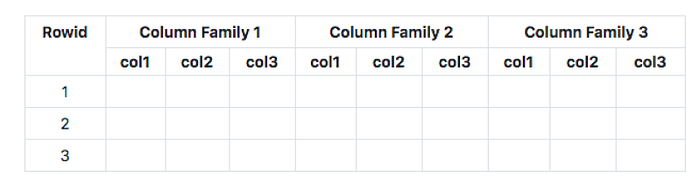
在最基本的層面上,每個table都是一個排序的key/value map
- row中的每個value都使用key — row key進行index
- 相關column被分組為column family
每個column透過使用column-family:column-qualifer(或name)來標識
這種結構支援低延遲的high read and write throughput。優點是可擴展到 PB 級資料,毫秒回應高達數百萬 TPS。適用在IOT streams, graph data與 即時分析(time-series data, financial data — transaction histories, stock prices)。另外我們可使用Cloud Dataflow來將資料匯出(檔案格式支援Avro與Parquet)到Cloud storage。
Tables的設計
在設計資料表時我們需要注意兩點:
- 要儲存什麼資料? (format、row等)
- 經常使用的Query是什麼樣的(按使用情況排名)?
另外Bigtable的table是key/value store。每個table只有一個index,即row key。基於經常使用的Query來設計rwo key:
- 可以有多個row key segment— 用分隔符號分隔(例如:ranga#123456#abcd)
- 避免連續性的row key(timestamp或連續數字)
- 如果我們打算根據timestamp檢索資料,請將timestanp記包含在row key中
- 如果要經常性查詢最近的資料,請使用reversed timestamp(例如:Long.MAX_VALUE — timestamp)。資料會從最新的開始排序
在我們設計完成table之後:
- 測試(幾分鐘的heavy load + 一小時模擬)至少30GB測試數據
- 使用 Cloud Bigtable 的 Key Visualizer 工具分析使用模式
最佳實踐
建議用在streaming IOT與time series類型的資料。
Bigtable會自動將資料分片(shard)到叢集中節點上的多個tablet,這是為了:
- 每個節點上擁有相同數量的資料
- 在所有節點上均勻分配read/write
在執行測試之前,先用heavy load進行幾分鐘的預測試。讓 Bigtable 有機會與時間平衡節點之間的資料。通常我們在設定bigtable cluster時,大都會選用SSD硬碟。但是如果不在乎效能的話,我們也可以選用HDD。
當我們建立了一個Cluster後,可以建立另一個cluster來進行Replication(可以Cross Region或Cross Zone)。資料的獨立副本儲存在每個cluster中(zone level)。Bigtable會自動複製異動。Replication可提高資料的durability和availability:
- 在多個zone或region中儲存單獨的副本
- 如果需要,可以在cluster之間自動進行failover
Replication可幫助我們拉近資料與客戶的距離
- 設定application profile具有multi-cluster routing的routing policy
- 自動路由到instance中最近的cluster
Cloud Pub/Sub(Asynchronous message service)
如果用過AWS SQS或Azure Event。哪Pub/Sub就是與這些其他雲端平台一樣提供相同的功能。這一類的非同步式訊息傳遞最大的功用就是去除程式之間的去耦合,並且不會因為某一個Application不可用而影響到另外一個。Cloud Pub/Sub是一個高可靠度與高擴充性的全託管式asynchronous messaging service。
例如,在一般傳統的架構之中,Application server通常直接連接Database server。如果遇到DB暫時性的掛掉,前端的Application service也會跟著一起掛掉。另外如果流量突然性的增高,哪麼即使前端有LB與VM的Auto scaling,哪麼流量壓力就會通通落到DB身上。
這時,我們就可以在AP與DB之間加上這一個服務來解決上述的兩個問題。在一個服務中,我們首先需要針對Application 來createu一個Topic,來讓資料寫入。然後針對DB這邊再create “subscriber”來將Topic的資料取出。這會有以下四種優點:
- Decoupling: Publisher (也就是App) 不用管資料要送給誰
- Availability: 即使DB暫時性的掛掉,Publisher (App)還是可以正常運作
- Scalability: Pub/Sub可以自動水平式的擴展其服務量能
- Durability: 資料在DB掛掉的期間也不會消失
Pub/Sub適用於streaming analytics pipelines的event igestion和交付。其資料交付方式有Push與Pull兩種。以下為一個Pub/Sub的作業流程說明。
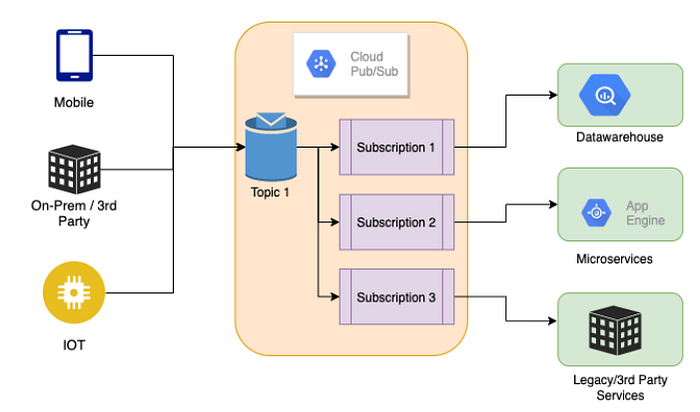
架構、角色與功能:
- Publisher — 資料傳送者
Publisher用Https request的方式將資料送到pubsub.googleapis.com - Subscriber — 資料接收者,這裡又分Push/Pull兩種方式
A.)Pull — Subscriber用https request的方式主動將資料從pubsub.googleapis.com將資料拉過來
B.)Push — Subscriber在註冊時提供一個 webhook endpoint。 當收到有關該Topic的資料時,http POST request將發送到 webhook endpoint
Publisher與Subscriber的關係對應可以是One-to-One/One-to-Many/Many-to-One/Many-to-Many。
通常我們會先Create Topic然後再Create subscription並註冊一個Topic。每個subscription代表從Topic中離散地拉取資料:
- 多個client拉取相同的subscription => 訊息在cleint之間拆分
- 多個client各自建立一個Topic => 每個client都會收到每個訊息
傳送與接收資料
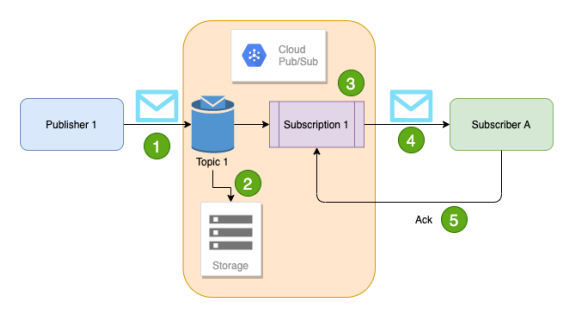
上圖可以看到整個資料傳送的步驟,要注意的是資料是個別單獨發送到每個Subscription(也就是其subscriber會從Topic copy 一份資料到自己的Queue中)。Subscriber透過Push/Pull的方式接收資料,在接收到資料後Subscriber就會在Subsceiption Queue中對這一筆資料標記為acknowledgement,代表已經接收到資料了。然後subscriptions 就會把這一筆資料給移除。
最佳實踐
將需要傳送的資料從同步改成非同步,但需要修改Application(如果是既有的)。或者當Data Consumer無法跟上Producer(緩衝數據)時也很有用。但如果不想用Pub/Sub這一類的託管服務,用RabbitMQ、Apache Kafka來自建這一類的服務也行。這也適用於"IOT data stream"的需求。
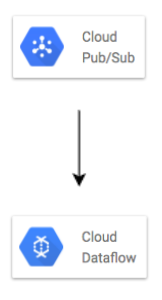
另外資料的運作方式是"依序、一次處理(Depulication)"也適合用Pub/Sub。我們需要在Subscription中的設定中啟用 — enable-message-ordering。另外加上DataFlow的服務來解決deduplication (exactly-once processing)。這可以維護一段時間內的message ID list,如果message ID 重複,則將其丟棄(假定為重複)。通常位於資料擷取服務(Cloud Pub/Sub、Cloud IOT core ..)和儲存/分析服務(Bigtable、BigQuery ..)之間。
Eventarc介紹
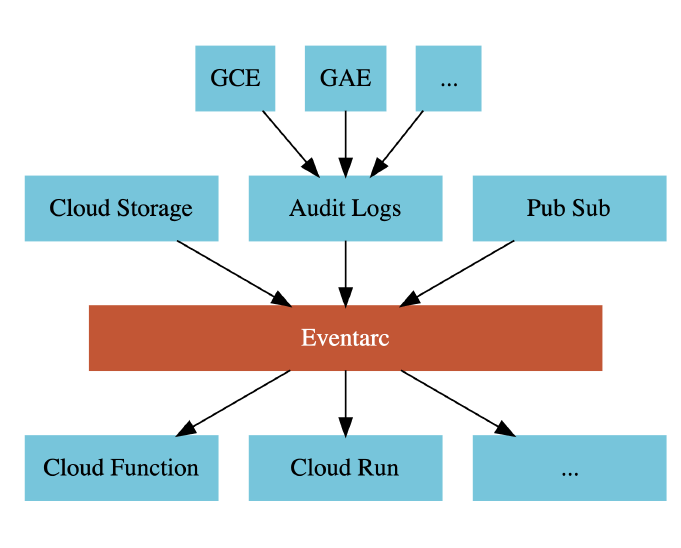
如果用過AWS EventBridge或Azure Service Bus的朋友們,可以跳過這一部分的介紹。因為它與另外兩間Cloud Provider提供的功能是一樣的。我們可以從上圖從看到Eventarc負責路由(根據規則)從不同的來源到不同的目的地。它的底層用的是Pub/Sub,只是GCP幫我們再多加一層管理層。
Eventarc嚴格遵守CloudEvents (cloudevents.io)的規範(就是長得差不多)。上圖中我們可以看到Event的來源分為Direct(直接性)與間接性(還要透過其他服務)。
Eventarc Event providers
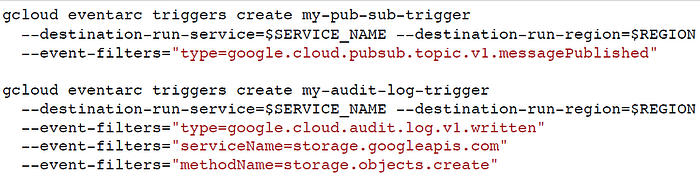
如同之前說的,Event的來源有分:
- 直接從GCP服務來的 —
如:Pub/Sub, Cloud Storage, Cloud Functions, Cloud IoT, Cloud Memorystore 等
type: google.cloud.storage.object.v1.archived/deleted/finalized
type: google.cloud.pubsub.topic.v1.messagePublished - 間接 — 如Cloud Audit Logs Entries
type : google.cloud.audit.log.v1.written
serviceName:appengine.googleapis.com,methodName:google.appengine.v1.Applications.CreateApplication
serviceName:artifactregistry.googleapis.com,methodName:google.devtools.artifactregistry.v1.ArtifactRegistry.CreateRepository
serviceName:compute.googleapis.com,methodName:compute.instances.delete
這種Event Driven Architecture的優點有:
- Loose Coupling: 如果我們使用Microservices,每一個service不用知道要把資料丟給誰。Event service會負責處理。
- Flexible Orchestration: 同一則訊息可以被不同的服務處理。
- Resiliency: 如果有其他服務掛掉,回復回來後還可以重新取的資料
- Asynchronous: 服務之間不用互相等待
CloudEvents
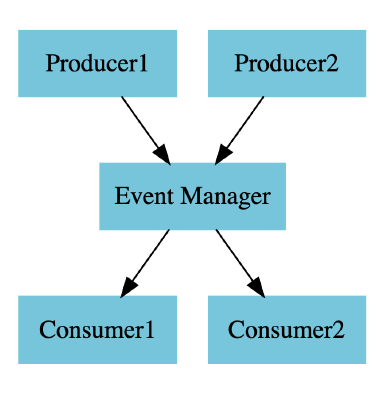
我們剛剛提到的CloudEvent這是CNCF的Project,是一種對Event的標準規範描述。既然是標準,哪麼它的優勢就會是:
- Consistency: 所有的Event都有一樣的架構
- Standard Libraries and Tooling: 允許跨不同類型的基礎設施(AWS/Azure/Google Cloud/On premise/..)和語言(Python、Go、NodeJS、Java、..)建立通用函式庫和工具
- Portability: 不再受特定基礎設施或語言的束縛
DataFlow簡介(ETL)
這是GCP提供基於Apache Beam的全託管式ETL服務,它用的是pre-built templates。通常有以下幾種資料流(Data Pipeline):
- Pub/Sub > Dataflow > BigQuery (Streaming)
- Pub/Sub > Dataflow > Cloud Storage (Streaming — files)
- Cloud Storage > Dataflow > Bigtable/Cloud Spanner/Datastore/BigQuery (Batch — Load data into databases)
- Bulk compress files in Cloud Storage (Batch)
- Convert file formats between Avro, Parquet & csv (Batch)
一般的使用場景如下:
- Realtime Fraud Detection
- Sensor Data Processing
- Log Data Processing
- Batch Processing (Load data, convert formats 等)
BigQuery(Data warehouse)
這是GCP提供的全託管式ExaByte等級的Data warehouse服務。它也是一種關聯式資料庫並提供SQL like的語法來查詢資料。這是一種傳統模式 (Storage + Compute) + 現代模式(Realtime + Serverless)資料倉儲。
BigQuery可以從多個來源來 import/export其資料,支援的檔案格式有:
- 資料匯入: CSV/JSON/Avro/Parquet/ORC/Datastore backup
- 資料匯出: Cloud Storage (長期存儲) & Data Studio (資料視覺化)。支援格式有: — CSV/JSON (用Gzip壓縮), Avro (用deflate或snappy壓縮)
另外我們也可以設定資料自動到期,BQ會把到期的資料自動刪除。要查詢的資料本身也可以不用儲存在BQ裡,我們可以放在Cloud Storage, Cloud SQL, BigTable, Google Drive裡(Permanent或Temporary external tables)。但是這些如果資料量太大都會有效能上的問題。
資料的存取與查詢
BQ提供以下四種方式存取資料:
- Web Console
- bq command-line tool (不適 gcloud)
- BigQuery Rest API
- HBase API based libraries (Java, .NET & Python)
由於BQ的費用是以儲存的資料與資料查詢量來收費,其中以資料查詢費用收費最高。所以BQ提供了一種方式來讓我們模擬我們再下這一個Query command時,會查詢的總資料量有多少。
- 技術面: 用UI(console)/bq — (加上dry-run這一個參數)
- 使用Pricing Calculator: 用價格計算機的方式,但是這比較少人用
哪麼為了不要在資料查詢的費用上走冤枉路,BQ提供了以下兩種方法來讓我們的資料查詢能夠更精確。我們可以在BQ的table上進行Partitioning與Clustering。
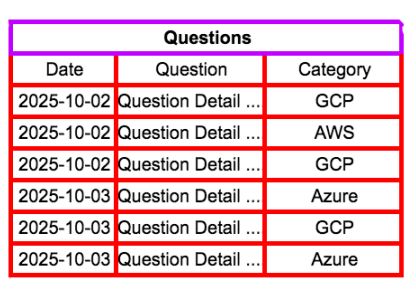
假設我們要查詢的資料是在某個特定時期的特定類別。以上圖,我們有一個Question table需要對其裡面的資料做查詢。裡面可能幾億筆資料,我們不太可能每次都搞select *這一種查詢(除非公司真的很有錢)。
所謂的Partitioning—就是把整個依某個條件(例如日期區間)把table分成好幾個區段(Segment)。這個我們只要每次查詢特定區間的資料就會又快又變一。而Clustering就是把相關的資料群組起來,例如上面Question table的Category。
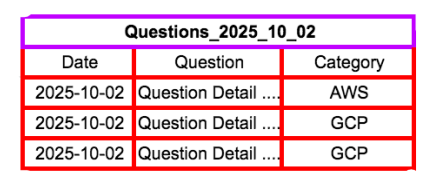
使用Partitioning的優點如下:
- 提高效能並降低成本
- 基於Ingestion time(到達時間)或Column( TIMESTAMP、DATE、DATETIME 或 INTEGER)進行segment
- (預設)所有segment的schema都跟原來的table是一樣的
- 允許使用table的過期部分資料自動刪除(partition_expiration_days)
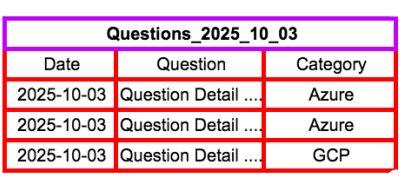
這是根據一個或多個cloumn的內容來組織table裡的資料。目標是co-locate相關資料並消除不必要資料的掃描查詢。這是避免我們建立太多小的segment(小於 1 GB)。 在這些情況下,運用Clustering會好得多。以下是一個在create table時同時啟用Partitioning與Clustering功能的table。

BQ的層級從Dataset →Table →Partitions三個。我們可以在任一個level來設置資料到期。
- 為Dataset配置default table過期時間 (default_table_expiration_days)
- 配置table的過期時間(expiration_timestamp)
- 為partitioned table配置partition過期時間(partition_expiration_days)
資料匯入
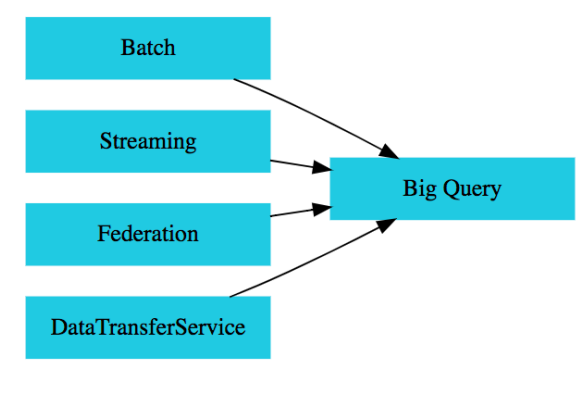
資料匯入BQ的方式有上圖所示的這幾種。大都是不要錢的,Batch都不用錢。但如果有用到GCP的其他Service都常就要錢了,尤其以Streaming的放式來匯入資料都要錢。像是用Cloud Pub/Sub、Dataflow或DaraProc等streaming方式。另外Federation的方式剛剛也提到過。最後是BQ自己的Data Transfer Service,BQ可以從以下來源將資料匯入:
- Google SaaS App(Google AD, Cloud Storage等)
- 其他的雲端平台— 如AWS的S3, Redshift
- 第三方的 Data warehouse— 如Teradata
資料串流
以串流的方式將資料匯入BQ有一些限制,這些限制都是資料流量還有大小方面的限制。另外一個問題則是資料的重複性(duplicates)。
解決資料重複性都常是為每個stream插入新增 insertId:
- insertId只能提供best effort de-duplication(最多一分鐘),還是有可能重複
- 如需嚴格的重複資料刪除和transactions,請用Datastore
在streaming quotas方面,如果我們沒有使用insertId,每秒鐘最大的資料量就是1 GB。而且是在算在Project Level的限制之內。但如果有使用的話:
- 每秒最大Row(project level)在US and EU
multi-regions: 500,000。其他地區: 100,000
per table limitation: 100,000 - 每秒最大資料量: 100 MB
如果每秒有幾百萬筆,哪還是用Bigtable吧。BQ其實不適合拿來用streaming方式塞資料。
最佳實踐
在執行查詢之前評估您的查詢
- 用bq — dry_run 或 dryRun API 參數
對table使用clustering與partitioning
盡可能避免streaming inserts
- bulk加載資料是免費的,但streaming不是免費的
- 提供Best effort de-duplication(當使用 insertId 時)
- 有Quota限制
資料自動過期:
- 為Dataset配置預設table過期時間 (default_table_expiration_days)
- 配置table的過期時間
- 為partitioned tables配置partition expiration
考慮長期儲存選項
- 長期儲存:連續90天不編輯資料的table
- 更低的儲存成本 — 類似於 Cloud Storage Nearline
BigQuery 對於複雜查詢來說速度很快:
- 但它沒有針對narrow-range queries進行最佳化(這要用 Cloud Bigtable)
- 設定查詢太複雜
使用審核日誌優化 BigQuery 使用情況:
- 在執行查詢作業之前分析Query/Job
- 將稽核日誌 (BigQuery Audit Metadata) 串流傳輸到 BigQuery
這是要了解使用模式(按使用者查詢成本)以及最佳化(使用 Google Data Studio 進行視覺化)
Cloud Dataproc
這是GCP 託管式的Spark 和 Hadoop 服務,它支援多種作業:
Spark、PySpark、SparkR、Hive、SparkSQL、Pig、Hadoop並能執行複雜的批次作業。
我們需要對Cluster進行管理:
- 用Single Node / Standard/ High Availability (3 masters)
- 可以用regular或Spot兩種 VMs
如果我們地端視運行Hadoop與Spark clusters,我們可以無縫的轉移。DataProc也是一個資料分析平台,它可以export confoguration但無法export資料。
更多的GCP 的資料儲存與分析服務請參閱本部落格以下文章:
