Azure的高可用度設計
如果組織已經把機房All IN到Azure了,哪我們必須確定各種重要系統所需的 SLA 和高可用性要求。 而公司的生意已經做到全球市場時,我們就可能會使用多個 Azure region來託管這些程式。 這些程式中的大多數都依賴於基礎架構和資料服務,這些服務也將跑在 Azure 中。 高管人員(C-Level)會要求我們確定系統在 Azure的高可用性要求,並為將在 Azure 中部署的所有新工作負載使用運算, 關聯式資料儲存與非關聯式資料儲存都要有高可用性解決方案。
不過在經濟下行的時代中,到底需要不需要高可用度則可能要視每個企業的狀況。我們必需與企業的業務利害關係人制定有共識的SLA/RTO/RPO等標。
在本文中我們將學習到以下要點
- 確認 Azure 資源的可用性要求
- Azure Front door的設計
- Azure Traffic Manager的設計
- Compute的高可用設計建議
- Relational data storage的高可用設計建議
- Non-relational data storage的高可用設計建議
確認 Azure 資源的可用性要求
我們的組織需要關鍵平台或服務具有高可用性。 任何關鍵平台或服務及其相關資料的設計方式也很重要,即在一個region中斷的情況下,它也可以自動failover並繼續在另一個region運行。
高可用的工作負載定義是:
- 對組件故障具有韌性
- 可以在良好的狀態下運行,沒有明顯的停機時間(這需要定義RTO)
要實現所需的韌性和高可用性,我們必須首先定義我們的"要求標準"是甚麼。
工作負載可用度目標
為解決方案中的每個工作負載定義目標 SLA/RTO/RPO,以便確定架構是否滿足業務需求。
考量費用與複雜性
在其他條件相同的情況下,可用性越高越好。但是,當我們有更多的 9 時,成本和複雜性就會增加。 99.99% 的正常運行時間相當於每月大約五分鐘的總停機時間。達到五個九是否值得額外的複雜性和成本?答案取決於業務需求,跟老闆的錢錢還有他願意付你的加班費。
以下是定義 SLA 時的一些其他注意事項:
- 要實現四個 9 (99.99%),我們無法使用人工處理來從故障中復原。應用程式必須要能自我診斷與自我修復。
- 超過四個 9,要足夠快的監控到有服務掛掉以滿足 SLA 是一個挑戰。
- 考慮衡量我們的 SLA 的時間區間。區間越小,忍受度越小。以每小時或每天的正常運行時間來定義我們的 SLA 是沒有意義的。
- 將 MTBF 和 MTTR 納入考量。我們的 SLA 越高,服務中斷的頻率就越低,服務必須恢復得越快。
- 就系統或平台的每個部分的可用性目標與業務利害關係人的要求達成一致,並大家要簽名畫押。
辨認相依性(dependencies)
執行dependency-mapping練習以識別內部和外部相依關係。 範例包括與安全性或身份驗證相關的相依性,例如 Active Directory,或第三方服務,例如支付提供商或電子郵件服務。
特別注意可能是單點故障(single point of failure)或導致瓶頸(bottlenecks)的外部依賴。 如果工作負載需要 99.99% 的正常運行時間但依賴於具有 99.9% SLA 的服務,則該服務不能成為系統中的單點故障。 一種補救措施是在服務失敗時有一個fallback path。 或者,採取其他措施從該服務的故障中回復。
下表顯示了各種 SLA levels 的可能累積停機時間。

每個組織都有獨特的要求,我們應該設計我們的系統或平台以最好地滿足公司複雜的業務需求。 定義目標 SLA 將讓我們在評估架構是否滿足組織的業務需求成為可能。 需要考慮的一些事項包括:
- 可用性要求是什麼?
- 可以接受多少停機時間(RTO)?
- 可能的停機時間會給我們的企業造成多少損失?
- 我們應該投入多少費用來使系統或平台具有高可用性?
- 資料備份的要求是什麼?
- 資料複製的要求是什麼?
- 監控的要求是什麼?
- 我們的系統或平台是否有特定的latency requirements?
更多的資訊可以參考Azure的 Principles of the reliability pillar這篇文件。
辨認重要系統的流程
了解重要系統的流程來評估整體營運效率至關重要,還要應該用在為系統的良好模型提供資訊。 它還可以判斷系統的路徑是過度使用還是未充分利用,並且應該進行調整以更好地滿足業務需求和成本目標。但大多數的狀況在台灣的企業大都達不到,因為台灣老闆都希望又要馬兒好又要馬兒不吃草。
由於相關業務場景和功能的重要性,通過系統的關鍵子系統或路徑可能對高可用,回復與效能有更高的期望。 這也有助於了解成本是否會因這些更高的需求而受到影響。
同時我們也需要辨認不重要的系統組件或路徑。通過系統的一些不太重要的組件或路徑可能對高可用,回復與效能的期望較低。 這可以通過選擇效能和可用性較低的Azure SKU 來降低成本(但馬兒可能就跑步快了)。
可用度的量測指標
使用這些措施來規劃redundancy並確定我們的 SLA。
- Mean time to recover (MTTR) 是在發生故障後恢復組件所需的平均時間
- Mean time between failures (MTBF) 是組件在兩次掛掉事件之間可以合理預期的持續時間
Azure的SLA(Service-level agreements)
Azure 的SLA 描述了 Microsoft 對正常運行時間和連接性的承諾。 如果特定服務的 SLA 為 99.9%,我們應該預期該服務在 99.9% 的時間內可用。 不同的服務有不同的 SLA。
Azure SLA 還包括在未滿足 SLA 時獲得service credit(就是退錢)的規定,以及每項服務的可用性的具體定義。 不過老實說,退錢可能只有一點點,公司的營業損失各雲端平台都不會賠。
Azure Front door的設計
Azure Front Door 使用 Microsoft global edge network與整合intelligent threat protection,提供快速、可靠且安全的CDN。 Azure Front Door 優化了對內容的存取時間。 Front Door 可用於Client要連接到 Azure resource之前提供另一層可靠性。 它是一個application delivery network,為 Web 應用提供"全球性的負載平衡與站台加速服務"。 它為我們的程式提供Layer 7 功能,如 SSL offload, path-based routing, fast failover, caching,等,以提高程式的效能和高可用性。
Azure Front Door 在可靠性方案中的工作原理
在下圖中,使用者正在連接到我們的domain(例如abc.com) 中運作的程式。 Azure Front Door 運作在edge location。 一開始,程式運作在primary region(在圖中標記為Active region)。 Front Door 將網路流量路由到該region。 但是,如果在該region中運行的程式掛掉了,Front Door 將failover到secondary region(在圖中標記為Standby region)。 Azure Front Door 將此方式稱為"Priority-based traffic-routing"。

上面的架構基於以下三個部分:
- Primary and secondary region。 該架構使用兩個region來實現更高的可用性。 程式部署到每個region(需注意版本是否同步)。 在正常操作期間,網路流量被路由到primary region。 如果primary region掛了,則流量將路由到secondary region。
- Front Door 將網路流量路由到primary region。 如果如果primary region掛了,Front Door 將failover到secondary region。
- Geo-replication。 SQL DB 或是Cosmos DB 的Geo-replication。
與部署到單一region相比,多個region架構可以提供更高的可用性(但需考慮成本)。 如果整個region掛掉而影響primary region,我們可以使用 Front Door failover到secondary region。
高可用場景
以下幾種常用方式可以實現跨region的高可用性。由上到下的方式會逐步提升系統的RTO/RPO。但請注意成本。

Azure Traffic Manager的設計
Azure Traffic Manager是一個DNS-based 流量負載平衡器(這個在AWS的Route 53也有該功能,但GCP目前沒有)。 這個服務允許我們將流量分發到全球 Azure region。 Traffic Manager還為我們的網站提供高可用性和快速回應能力。 由於Traffic Manager是基於 DNS 的負載平衡服務,它只能在domain level進行負載平衡。 出於這個原因,它不能像 Front Door 那樣快速地進行failover,因為 DNS cache和系統不支援 DNS TTL 的常見性問題。
Azure Traffic manager在可靠性方案中的工作原理
Traffic Manager使用 DNS 根據traffic-routing方法將網路流量導向到適當的service endpoint。 我們可以使用Traffic Manager endpoints定義這些服務。 每個endpoint都是service load balancer IP。 我們可以使用此配置將網路流量從一個region的Traffic Manager endpoint導向到不同region的endpoint。 這通常稱為geographic routing。 例如,下圖描述了一個典型場景:
- 使用者詢問 DNS server。
- DNS server 向Traffic Manager查詢所需的Record。
- 查詢結果從Traffic Manager返回給DNS server。
- 使用者直接連接到有在回應答詢的endpoint。

高可用度場景
Traffic Manager為我們的重要的系統提供高可用性。 它通過監控我們的endpoint並在endpoint出現故障時提供自動failover來實現這一點。 與 Azure DNS 一起使用的Traffic Manager啟用了一些failover方法,如下表所述。架構師需要考量成本問題。

根據我們想要實現的目標以及適合我們需求的方法,我們可以實施以下的failover方法:
手動,通過使用 Azure DNS,這個failover 方案使用標準 DNS 機制fail over到我們的備用站台(請注意程式版本與資料同步問題)。此選項與cold standby 或pilot light結合使用時效果最佳。
自動。通過使用Traffic Manager,具有更複雜的體系結構和能夠執行相同功能的多組資源,我們可以自動配置 Azure Traffic Manager(基於 DNS)。Traffic Manager會檢查我們的資源的健康狀況並自動將流量從掛掉的資源轉到正常運作的資源。
在下圖中,primary region (active) 與 secondary region (passive)都有完整部署。這包括我們的程式和資料庫同步。而只有primary region正在處理來自使用者的流量。當primary region遇到服務中斷時,secondary region才會變為active。在這種情況下,所有新的流量都由Traffic Manager路由到secondary region。

運算單元的高可用度設計建議
Azure基礎架構在每一層都經過設計和構建,主要在為我們提供我們的系統的冗餘與韌性。 Azure 基礎架構由geographies, regions, 與Availability Zones(以下簡稱AZ),它們限制了故障所產生的影響範圍。 Azure AZ主要在提供軟體和網路解決方案,以防止資料中心掛掉並為我們提供更高的HA(high availability)。
Azure AZ(Availability Zone)的設計
AZ是 Azure region內的唯一物理位置。每個zone由一個或多個具有獨立電源、冷卻和網路的資料中心組成。Region內AZ的物理分離限制了zone failure對程式和資料的影響,例如天災,以及其他可能破壞站台的存取、安全通道、延長utilities uptime和資源的可用性。AZ及其相關資料中心的設計使得如果一個zone掛掉,該Region中的其他AZ將支援服務、容量和可用性。
AZ可用於將我們的系統分佈在一個Region內的多個Zone中,從而允許讓我們的程式在一個zone出現故障時繼續運行。通過AZ,Azure 提供99.99% 虛擬機 (VM) SLA。而Zone-redundant services複製我們的服務和資料,以防止單點故障。

下圖說明了單一 VM、Availability Sets, 與AZ不同等級的 HA

以 VM 為例,單一VM 的 SLA 為 99.9%。這意味著虛擬機將在 99.9% 的時間內可用。在單一資料中心內,Availability Sets的使用可以通過保護一組 VM 將 SLA 水平提高到 99.95%,確保它們不會都在同一個硬體上。在一個Region內,VM 工作負載可以跨AZ分佈,將 SLA 提高到 99.99%。Availability Sets是Azure獨有的,因為AWS 與GCP並沒有讓我們管到用雲端平台的哪一個資料中心的機櫃。
支援AZ的 Azure 服務分為兩類:zonal services 與zone redundant services。可以對我們工作負載進行分類以利用任一架構方案來滿足程式的效能和存續性要求。
使用zonal architecture,可以將資源部署到特定的、自選的AZ,來實現更低的 網路延遲與更高效能要求。韌性(Resiliency)是通過將程式和資料複製到zone內的一個或多個zone來進行自我修復。我們可以選擇特定的AZ進行同步複製,提供高可用性,或非同步複製,提供備份(省錢的選擇)。我們可以將資源(例如,VM、managed disk或standard IP addresses)固定到特定zone,通過將一個或多個resource instance分佈在zone中來提高系統的韌性。借由zone-redundant architecture,Azure 平台自動跨zone複製資源和資料。
Zone failure對單一zone和zone-redundant services的影響不同。在zone掛掉的情況下,裡面的服務當然沒辦法用,要到zone恢復回來。通過構建我們的解決方案以在zone中使用replicated VMs,我們可以保護我們的程式和資料不會受zone掛掉例如,由於斷電)的影響。如果一個zone掛掉,複製的程式和資料會立即在另一個zone中上現。
Zonal architecture適用於特定資源,通常是IaaS 資源,如 VM 或managed Disk,如下圖所示。例如,zonal load balancer, VM, managed disks, virtual machine scale sets。
在下圖中,每個 VM 和LB都部署到特定zone。

對於zone-redundant services,工作負載的distribution是service的一項功能,由 Azure 處理。 Azure 自動跨zone複製資源,不需要我們處理。 例如,ZRS 跨三個zone複製資料,因此zone 掛掉不會影響資料的 HA。
下圖是zone-redundant load balancer。

有關每個 Azure service支援AZ的 的清單,請參閱Availability Zones documentation。
何時該使用 VM scale sets
Scale sets是從VM構建的。 使用Scale sets,提供管理層和自動化層來運行和擴展我們的程式。 我們可以改為手動建立和管理單台 VM,或整合現有工具以建購類似等級的自動化。 下表概述scale sets與手動管理多台 VM 相比的優勢。

設計高可用的容器方案
Azure Kubernetes Service (AKS) 是managed Kubernetes cluster的 Azure 服務。 AKS 負責部署 Kubernetes cluster和管理 Kubernetes API server。 重要的是,我們部署的任何基於 AKS 的應用都設計為具有高可用性和可靠性。
預設情況下,AKS 會自動提供一定程度的高可用性。 這是通過在 VM Scale Sets中使用多個node來實現的。 但是,這些node無法針對 Azure region failure提供保護。 因此,我們應該計劃在多個region中實施 AKS cluster。
Multiple Region可用性的考量
在計劃跨多個region部署實施 AKS cluster時,請考慮以下事項:
- AKS region availability。 選擇靠近我們的使用的region。
- Azure paired regions。 對於我們的地理區域,選擇兩個配對的區域。 另外還要考慮:
- AKS platform update(計劃維護)在配對region之間至少延遲 24 小時再update下一個 cluster。
- 在需要時優先考慮配對region的回復工作。
- Service availability。 決定我們的配對region是hot/hot, hot/warm, or hot/cold。 換句話說,我們是否想同時運行兩個region,其中一個region準備好開始服務?
Azure Storage replication options
我們的程式很可能使用 Azure storage來存儲資料。 假設我們這樣做,並且這些程式分佈在多個region的多個 AKS cluster中,我們將需要一種同步存儲的方法。 使用 Azure storage,我們有兩種可能的選擇:
- Infrastructure-based asynchronous replication
- Application-based asynchronous replication
Infrastructure-based asynchronous replication
我們的程式可能需要persistent storage。 在 K8S 中,我們可以使用persistent volumes來存放資料。 這些persistent volumes被掛載到node VM,然後expose給 pods。即使 pod 移動到同一cluster內的不同node,Persistent volumes也會跟 pod跑。
通常,我們會提供一個common storage point,程式會在其中寫入資料。 然後,此資料將跨region複製,如下圖所示。
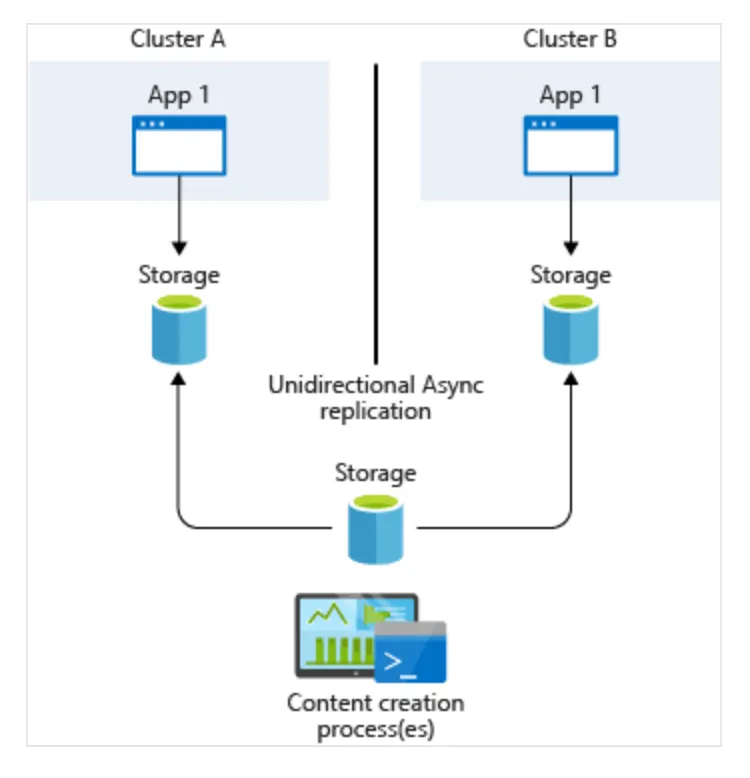
Application-based asynchronous replication
K8S 目前沒有application-based asynchronous replication。因為不需要,只要確定我們的container image有存放在image repo即可。
通常,程式本身可以複製storage requests,然後將這些requests寫入每個cluster的底層資料存儲。 此過程如下圖。
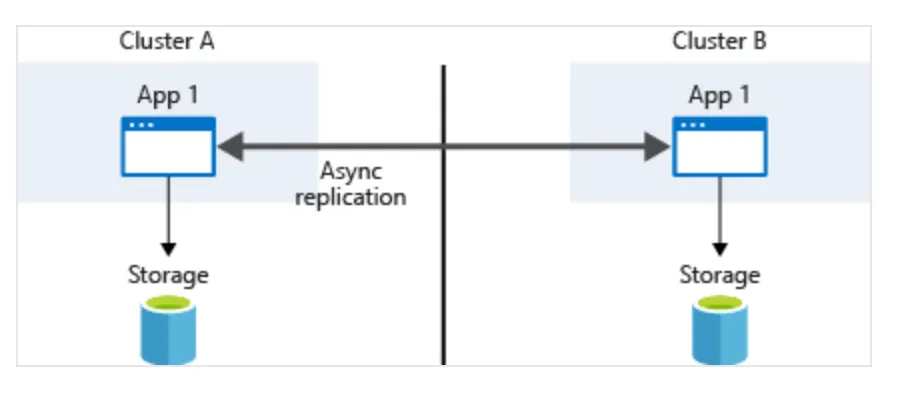
與任何程式一樣,備份跟 AKS cluster及其程式相關的資料非常重要。 當我們的程式不斷存取資料時,我們應該安排頻繁的備份或定期對這些資料進行快照。 我們可以使用多種工具進行這些備份操作,包括:
- Azure Disks:Azure Disks可以使用內建快照技術。 但是,我們的程式可能需要在快照操作之前flush writes-to-disk。
- Velero:Velero 可以備份persistent volumes以及其他cluster resources 與配置。
關聯式資料儲存的高可用設計建議
我們可能有許多程式要存取DB中的資料。 這些程式及其各自的DB具有高可用性並且在必要時可以recover,這一點很重要。
若要了解 Azure SQL 中的可用性選項和功能,我們需要知道甚麼是service tier。 我們選擇的service tier將確定我們部署的DB或managed instance的底層架構。
有兩種選購模式:DTU 和 vCore。 我們先來看甚麼是vCore service tier及其高可用性架構。 而我們可以將 DTU 模型的Basic 與Standard tiers等同於vCore service tier的General Purpose,將其Premium tiers等同於Business Critical。
General purpose
General Purpose service tier中的DB和managed instance具有相同的可用性架構。下圖作為一個說明,首先考慮application 與control ring。application連接到server name,然後連接到Gateway,Gateway將Application指向要連接的server,在 VM 上運行。對於General Purpose,primary replica將實體機器內的 SSD 用於 tempdb。data 與log files存儲在 Azure Premium Storage中,這是locally redundant storage(一個region中的多個副本)。然後將backup file存儲在 Azure Standard Storage中,預設情況下為 RA-GRS。換句話說,它是globally redundant storage(在多個region有副本)。
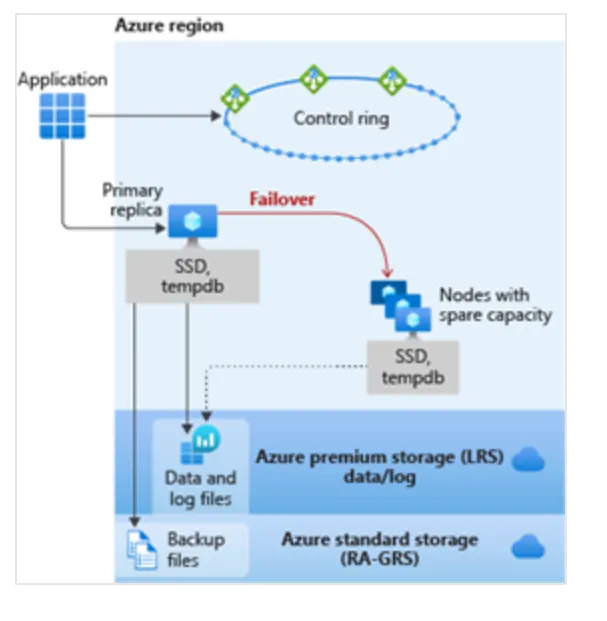
所有 Azure SQL 都構建在 Azure Service Fabric 之上,它作為 Azure backbone。如果 Azure Service Fabric 確定需要進行failover,則failover將類似於故failover cluster instance (FCI)。service fabric將尋找具有備用容量的節點並啟動新的 SQL Server instance。然後就會掛載 DB file,回復運行,並update gateway以將Application指向新節點。不需要virtual network or listener or updates(這個功能是內建的)。
Business critical
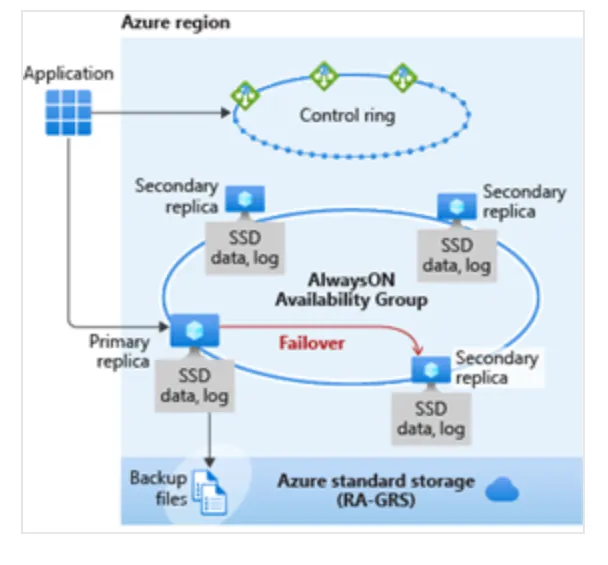
Business critical通常可以實現所有 Azure SQL service tier(General Purpose, Hyperscale, Business Critical)的最高效能和高可用性。Business critical適用於需要低延遲和最短停機時間的重要系統。
使用Business Critical就是使用 Always On availability group (AG)。與General Purpose tier不同,在Business critical中,data與log file都在direct-attached SSD 上運行,這降低了網路延遲。 (General Purpose 使用remote storage)在這個 AG 中,有三個secondary replicas。其中之一可用作read-only endpoint(不另收費)。當至少有一個secondary replicas強化了其transaction log的更改時,transaction可以完成commit。
使用其中一個secondary replicas進行Read scale-out來支援session-level consistency。因此,如果session-level consistency掛掉導致連接錯誤後會重新連線,它可能會被導向到與read-write replica不是 100% 最新的replica。同樣,如果程式使用read-write session寫入資料並立即使用read-write session讀取資料,則最新data update可能不會立即在replica上可以讀到。會有這樣的延遲是因為asynchronous transaction log redo operation的關係。
如果發生任何類型的故障並且service fabric確定需要啟動failover,則fail over到secondary replica會很快,因為該replica已經存在並且attach data。在failover中,我們不需要listener。即使在failover之後,Gateway也會將我們的連接重新導向到主要節點。service fabric負責啟動另一個secondary replica。
Hyperscale
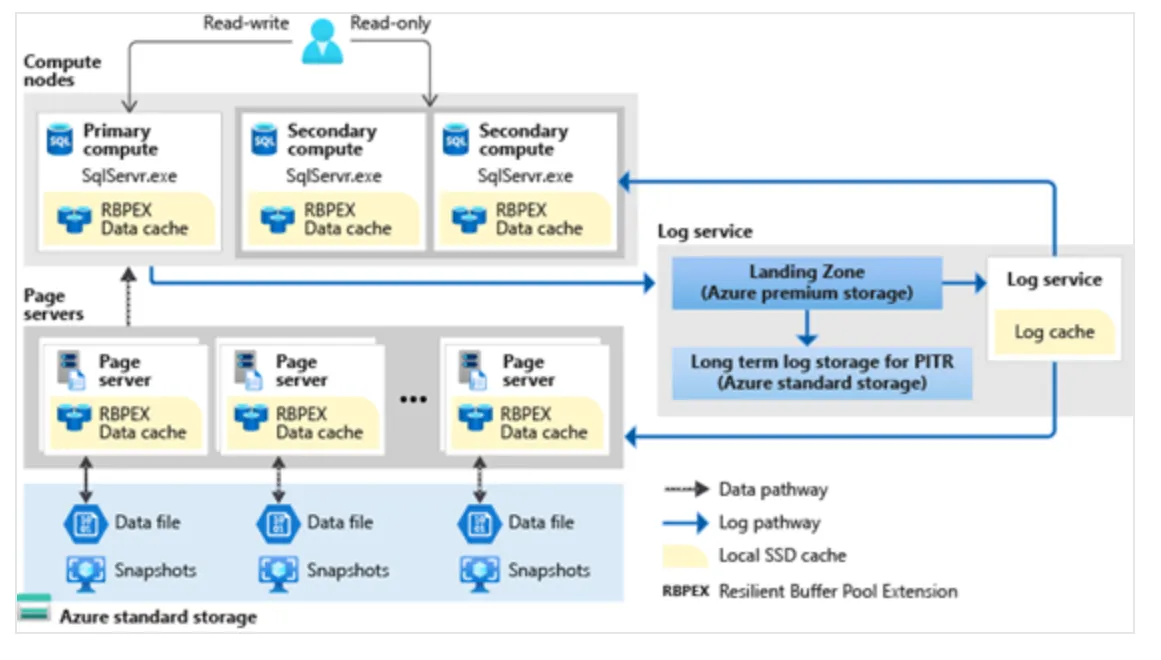
Hyperscale service tier只有在 Azure SQL DB中才有。這個service tier具有獨特的架構,因為它使用caches 與page servers的tiered layer來擴展快速存取 DB pages的能力,而無需直接存取 data file。
由於此架構使用成對的page servers,因此我們可以水平擴充(scale horizontally)以將所有資料放在水平擴充中。這種新架構還允許Hyperscale支援高達 100 TB 的DB。因為它使用快照,所以無論大小為何,都可以進行幾乎即時進行的DB backup。我們還可以在一定時間內scale up或scale down以適應我們的工作負載。
哪log service是如何在這個架構中被拉出來的呢?log service用於提供replicas和page server。當log service被強化在landing zone時,Transactions可以進行commit。因此,commit不需要Secondary compute replica 產生任何change effort。與其他service tier不同,我們可以確定是否需要secondary replicas。我們可以配置零到四個secondary replica,它們都可以用於read-scale。
與其他service tier一樣,如果secondary replica確定有必要,則會自動failover。但recovery time將取決於secondary replicas的存在。例如,如果我們沒有replica並且發生failover,則場景將類似於General Purpose service tier的場景:service fabric首先需要找到備用容量。如果我們有一個或多個replica,則回復速度更快,並且更接近於Business Critical service tier的等級。
Business Critical 為具有需要低延遲的small log write的工作負載保持最高效能和高可用性。但是Hyperscale service tier允許我們有更高的throughput(MB/second),提供最大的DB大小,並提供多達四個throughput以實現更高等級的read-scale。因此,當我們在兩者之間進行選擇時,我門需要考慮是我們的系統需要用到哪一種效能。
Database service tier的可用度
預設情況下,Azure SQL DB和 Azure SQL managed instance在各種service tier中提供了幾種可用性選項。 我們可以做一些額外的事情來增加或修改DB/instance的可用性。 也能夠直接看到對SLA的影響。 在這裡,我們將了解如何進一步使用 Azure SQL 中的各種可用性選項。
Availability Zone(AZ)
在 Azure SQL DB 的Business Critical tier中,如果我們所選的region有支援,我們可以選擇加入(不另收費)zone-redundant configuration。 在較高等級上,在Business Critical DB 和managed instance之後運行的 Always On Availability Group(AG) 部署在一個Region內的三個AZ中。 AZ之間始終存在物理分離。 此功能可防止區域中的資料中心可能發生的災難性故障。

從效能的觀點來看,網路延遲可能會略有增加,因為我們的 AG 現在分佈在彼此之間有一定距離的資料中心。 因此,預設是沒有啟用AZ的。 我們可以選擇使用通常稱為“Multi-Az”或“Single-Az”的部署。
Azure SQL SLA
Azure SQL SLA,為實現和維護服務等級的承諾提供退錢。如果我們選擇的service level未達到和維持到,如 SLA 中所述,我們可能有資格獲得部分月服務費的抵免,但請考慮公司的營業損失。
目前,我門可以從配置了AZ的 Azure SQL DB Business Critical部署實現最高可用性 (99.995%)。Business Critical tier提供分別為 5 秒和 30 秒的 RPO 和 RTO 的選項。
對於 Azure SQL DB或 Azure SQL managed instance的General Purpose 或single-zone Business Critical deployments, SLA 為 99.99%。
Hyperscale tier的 SLA 取決於replica的數量。我們選擇在Hyperscale中擁有多少replicas。"如果我們沒有選擇要replica,則failover行為更像是General Purpose。如果我們有replicas,則failover行為更像是Business Critical。"以下是基於replica數量的 SLA:
- 0 replicas: 99.5%
- 1 replica: 99.9%
- 2 or more replicas: 99.99%
Active geo-replication
Active geo-replication使我們能夠建立單一DB的readable secondary databases。 這些DB可以位於相同或不同Region的server上。這一類的cross-region DB replication在其他兩個公有雲中也有。不過對於不一樣的DB Engine的支援強項各有不同,Azure對自家的SQL server支援相對最高。
在下圖中,程式運作在我們的domain abc.com 中。 這個程式搭配了一個DB來存儲資料。 為了管理到secondary region的failover,管理員配置了secondary region。 Regions之間已啟用Geo-replication。

Active geo-replication能用於以下場景:
Azure SQL Database: 我們可以為任何elastic database pool中的任何DB配置active geo-replication。 我們可以使用active geo-replication來:
- 在不同的region 建立 readable secondary replica
- 假如Primary DB 掛掉或需要下線,哪我們就可以fail over到secondary database
小提示:
我們最多可以擁有四個readable secondary replicas。 Cosmos DB 支援跨region的geo-replication。 但是,我們也可以:
- 將一個Region指定為writable region,將所有其他region指定為read-only replicas。
- 通過在掛掉期間進行failover選擇另一個region作為writable region
以下表格描述了active geo-replication的能力

Auto-failover groups
由於 Azure SQL managed instance不支援active geo-replication,因此對於 SQL managed instance 的geographic failover,我們必須使用auto-failover groups。 Auto-failover groups使我們能夠管理一組DB(在VM上或managed instance中的所有DB上)到另一個Region的replication(和failover)。 與geo-replication一樣,我們可以選擇手動啟動failover,也可以根據我們定義的policy讓 Azure service代管。
我們必須在primary server上配置auto-failover group。 這個配置將primary server連接到不同 Azure region中的secondary server。 這些group可以包括這些server中的所有或部分DB。 下圖描述了使用多個DB和auto-failover group的geo-redundant cloud application的典型配置。

以下表格描述了auto-failover groups的能力

由於 auto-failover groups(For managed Instance)與active geo-replication(For elastic database pool)的功能相似,因此哪種狀況使用哪種服務是需要考慮的。
在以下情況下使用geo-replication:
- 我們正在實施Hyperscale service tier。 Hyperscale service tier當前不支援Auto-failover groups。
- 我們希望在相同或不同region中有多個 Secondaries Azure SQL DB 。
在以下情況下使用auto-failover groups:
- 我們正在實施 Azure SQL DB managed instance。
Geo-replication 與 auto-failover groups
選擇service tier(並在適用時考量到AZ)後,我們可以考慮一些其他選項來獲得read-scale或failover到另一個Region的能力:geo-replication 與 auto-failover groups。 在地端機房的 SQL Server 中,配置這些選項中的任何一個都需要大量的計劃、協調和時間。但Azure SQL使這個過程變得更容易。
以下是一些注意事項,可幫助我們確定geo-replication 與 auto-failover groups是否最適合我們的場景:

Global distribution使我們能夠將資料從一個region複製到多個 Azure region。我們可以隨時加入或刪除複製DB的region,假設我們的資料為 100 TB 或更少,Azure Cosmos DB 可確保在我們增加其他region時讓我們的資料在 30 分鐘可以上線使用。
在兩個或多個regions中replicate 資料有兩種常見場景:
- 為全世界(中國除外,因為哪是位在火星的網路)任何地方的客戶提供低延遲的資料存取
- 為 BCDR(business continuity and disaster recovery) 增加regional resiliency
為了向客戶提供低延遲的資料存取,我們應該將資料replicate到離我們的客戶最近的region。要提供 BCDR 解決方案,建議根據Business continuity and disaster recovery (BCDR): Azure Paired Regions :Azure 配對region一文中描述的region pairs。
非關聯式資料儲存的高可用設計建議
Azure storage redundancy
Azure storage 提供了多個redundancy選項,可幫助確保我們的資料是可用的。為存儲選擇redundancy option時,我們要考慮以下事項:
- 我們的資料如何在primary region中進行replication
- 是否將我們的資料複製到地理上相距較遠的第二個region以防止區域型的災難
- 如果primary region掛掉,我們的系統是否需要對replicated data的有讀取權限
Primary region中的Redundancy可以提供如下:
Locally redundant storage(LRS — Azure獨有的,其他兩家AWS/GCP沒有要管到這麼細)。保護我們的資料免受資料中心中的機櫃故障的影響。但是,如果整個資料中心都掛掉,則使用 LRS 的storage account的所有replicas都可能掛掉。這個選項的特點是:
- 在primary region中的單一個物理位置同步複製三次資料。
- 是最便宜的replication option。
- 不建議用於需要高可用或高存續的程式。
個人覺得Azure會這麼做是因為Azure不是每個Region都有AZ。既然沒有Az可以管,哪就只能管管機櫃了。
Zone-redundant storage (ZRS)。幫助確保即使整個zone掛掉,我們的資料仍可以read/write。這個選項的特點是:
- 跨primary region中的三個 Azure AZ 同步複製資料。
- 用在需要在primary region具有高可用性並複製到secondary region的系統。
LRS 是成本最低的redundancy option,與其他選項相比,其資料存續性最低。 LRS 保護我們的資料免受機櫃掛掉的影響。但是,如果整個資料中心掛掉,則使用 LRS 的storage account的所有replicates都可能遺失或無法恢復。為降低此風險,我們應該使用zone-redundant storage (ZRS)、 geo-redundant storage (GRS), 或geo-zone-redundant storage (GZRS)。
LRS 是以下場景的不錯選擇:
- 如果我們的程式存儲的資料在發生資料遺失時可以容易的重建,我們可以選擇 LRS。
- 如果由於資料治理的要求,我們的程式僅限於在一個國家或地區內複製資料,我們可以選擇 LRS。在某些情況下,資料進行地理複製的paired regions可能位於另一個國家或地區。有關paired regions的詳細資訊,請參閱 Azure regions。
對於需要高存續性的程式,我們可以在secondary region中建立資料副本。secondary region中的Redundancy可以提供的如下:
- Geo-redundant storage (GRS):
- 使用 LRS 在primary region中的單一個物理位置同步複製資料三次。
- 將資料非同步複製到secondary region中的單一個物理位置。
- 使用 LRS 在secondary region內同步複製資料三次。
- Geo-zone-redundant storage (GZRS):
- 使用 ZRS 跨primary region中的三個 Azure AZ同步複製資料。
- 將資料非同步複製到secondary region中的單一個物理位置。
- 在secondary region內使用 LRS 同步複製資料 3 次。
重點:
GRS 和 GZRS 之間的主要區別在於資料在primary region中的複製方式。 在secondary regionz範圍內,使用 LRS 的資料永遠都會被複製 3 次。 secondary region中的 LRS 可保護資料免受硬體故障的影響。
對於 GRS 和 GZRS,我們在secondary region中的資料不能read/write,除非failover到secondary region。 要啟用對secondary region的read access,要將我們的storage account配置為使用以下選項之一:
- Read-access geo-redundant storage (RA-GRS).
- Read-access geo-zone-redundant storage (RA-GZRS)
storage redundancy options的總結
下表總結了所討論的redundancy options,並引導我們的資料在每種情況下是否是具有高可用與存續性。

PS:如果Primary region掛了,則需要Account failover來恢復write availability。
在決定哪種redundancy option最適合我們時,我們要在較低成本和較高可用性之間進行權衡(不過台灣老闆可能永遠都聽不進去)。 有助於確定我們應該選擇哪種redundancy option的因素包括:
- 資料如何在primary region中replicate
- 是否將資料複製到地理上與primary region相距較遠的second region,以防止發生區域性災難
- 如果primary region因任何原因變得無法使用,我們的程式是否需要讀取secondary region中的資料.
