AWS的大數據分析-Part 4資料視覺化
我們從Part 1 — Part 3介紹了資料在AWS平台服務中的的 ingest, store, process與 analyze,最後我們需要將這些資料視覺化來提供人們來判讀。資料視覺化的工具在現在有百百種,在AWS上能夠提供到一般使用使用者用到的資料視覺化工具為 AWS QuickSight。
資料的使用者
在大部分的組織中,會使用到資料的角色不外乎有
Data Experts
這一類專家是對其特定的資料有著domain know how的 SME(subject matter experts)。他們負責建立新的KPI 以使用各種技術衡量業務績效,包括依賴進階資料的可視化來建立 KPI 並將其傳達給其他stakeholders。
Business Users
第一線的業務單位人員。他們通常操作的是經過aggregate 的data與進行 slice-and-dice分析。
資料科學家
他們通常對資料進行探索與特徵工程,最後建立期資料模型。
Downstream Systems
主要把我們的資料平台當作一個information HUB來供給下游系統來使用
Operational Applications
我們的Application將依賴於具有ultra-low latency的細粒度資料。 例如,我們的call center Application試圖了解消費者過去的交易或投訴,以提供更好的體驗。
下圖為這些資料使用者的角色可以使用的AWS服務的patterns

更多的資料使用角色的詳細描述可以參考此篇Snowflake 雲端資料分析
AWS QuickSight
這是AWS所提供的BI tools。 QuickSight有著 low-latency的效能,以下為QuickSight的特點
學習曲線較短:
只要有一點點的IT基本知識就可以連結資料來源並建立Dashboard
支援多種資料來源:
AWS的 S3/Redshift/ RDS/ DynamoDB/ Linesis與其他非AWS的資料來源。
In-memory Data Backend:
QuickSight提供一種稱為 SPICE(super-fast. Parallel, In-memory Calculation) engine,這讓我們將資料放在記憶體中與其互動。這是一種將資料以colummar格式存放在記憶體中,columnar的格式適合分析之用,SPICE engine是跨多個AZ並有備份在S3中。所以具備其高可用度。
簡單的建立與分享其資料分析:
不需要IT專家進行分析,一般非技術人員就可以建立。
資料處理
我們上面提到QuickSight的資料來源有多個管道,包含了關聯式資料庫,檔案類型(如JSON)與其他第三方的SaaS業者。在我們對資料進行視覺化之前,我們必須指定其資料來源與針對其來源建立資料及。
- Data source(資料來源)是最原始的資料,沒有經過任何處裡的。來源如我們上面說的。
- 資料集(Dataset)是我們將原始資料載入到SPICE後對裡面的資料(column)進行相關的filter/aggregation後產生的資料。
QuickSight可以直接解壓縮存放在S3上面的 Zip 與Gzip的資料,但如果不是這兩種我們就必須手動解壓縮。
QuickSight支援的檔案格式有 CSV, TSV, CLF(Common Log Format), ELF(Extend Log Format), CLSX, JSON。而關聯式DB除了剛剛提及的還有MySQL/PostgreSQL/ MS SQL/ MariaDB/ Apache Presto/Apache Spark/ Teradata/Sonwflake。而支援的第三方SaaS業者有 Salesforce/ GitHub/ Twitter/Jira/ServiceNow/Adobe Analytics。
在我們完成資料集之後,我們可以將這個資料集全部或部分複製給其他人(同一個AWS account)並將這個資料集定期從data source refresh。在QuickSight Enterprise的版本可以將資料的存取控制在 row-level。
QuickSight的資料視覺化
QuickSight在每個分析(analysis)最高可以有20個資料集,而在單一的分析最高可以有20個視覺化物件(Object)。在QuickSight中所謂的分析是相關可視化和故事的容器,所有這些都是為了滿足特定業務目標或提供衡量業務的一個或一組KPI指標的能力而構建的。
QuickSight提供三種視覺化的方式:
- AutoGraph — 這是QuickSight的功能。可讓我從QuickSight 尋求幫助以確定最合適的visual type的功能。
- Choosing Visual Type — 自行選擇 visual type與field來推送到視覺化元件。
- AWS QuickSight Suggest Visuals — 如果我們不確定我們的資料可以幫助我們回答哪些query,您可以選擇tool bar上的suggested並選擇 QuickSight suggestion option中的一項。
以下表格是QuickSight各類的 Visual type適用的情況





我們從上面表列挑一些經常會用到visual type
Bar Charts — 主用在資料的比較與分佈(如下圖)

Line Charts — 隨著時間推移的資料變化(如下圖)

Scatter Plots: 資料之間的關連(correlation)(如下圖)

Heat Maps: 資料之間的關連(correlation)(如下圖)

Pig Charts: 資料的聚合( aggregation)(如下圖)

Donut Charts: 每種資料佔總體資料的百分比(如下圖)

Gauge Charts — 比較度量中的值(如下圖)

Tree Maps — 分層次的資料聚合(如下圖)

Pivot Tables — 表格資料(如下圖)

KPIs — 與目標值的比較(如下圖)

Geospatial Charts(如下圖)

Words Counts — 單詞或短句出現的頻率(如下圖)

QuickSight Machine Learning Insight
QuickSight提供ML的功能,基本上分為以下三種
Anomaly detection
使用 Random Cut Forest來辨識異常值。例如營收的異常(如下圖)

Forecasting — 同樣使用Random Cust Forest,通常做為檢測季節性和趨勢
與排除異常值並估算缺失值(如下圖)。

Auto-narratives — 在我們的Dashboard加上文字描述,如下圖

在Enterprise的版本中,我們可以將這些Dasshboard透過email的方式分享給其他人。email可以是on-demand or on a schedule。
將 Quick Objects放置到其他Applications
我們有時可能會需要將QuickSight的Dashboard崁入到其他web Application中,統整資訊時就不個別檢視不同的Application。使用者無需執行身份驗證即可接收個性化dashboard,dashboard查看者可以是任何 QuickSight 用戶,例如可能已通過我們帳號身份驗證的reader、authors或admins:
- Active Directory users or groups member
- 已邀請的非federated users
- IAM users和基於 IAM roles的session使用 SAML、OpenID Connect 或 IAM federation使用federated single sign-on進行身份驗證
將QuickSight崁入到我們的Application 有以下五個步驟
- 在 QuickSight 中create dashboard。 publish dashboard並與應該能夠查看它的group和user共享。 在allow list中添domain,包括我們將在其中嵌入dashboard的 Web aspplication的doamin。
- 在我們的 AWS account中,為嵌入式dashboard的viewer設置權限。 將使用嵌入式dashboard查看的Application的用戶應該能夠使用 IAM、AWS Managed Microsoft AD、SAML 或 Web Identity 進行身份驗證。
- 建立或選擇一個 IAM role,user都會被分配到這個roler具有 QuickSight 中的reader的權限以及檢索需要嵌入的dashboard的能力。
- 在我們的Application的server上,使用 AWS SDKs對user進行身份驗證並獲取嵌入dashboard URL。
- 在我們的Application中嵌入dashboard。 我們可以使用 QuickSight embedding SDK 來簡化嵌入過程。
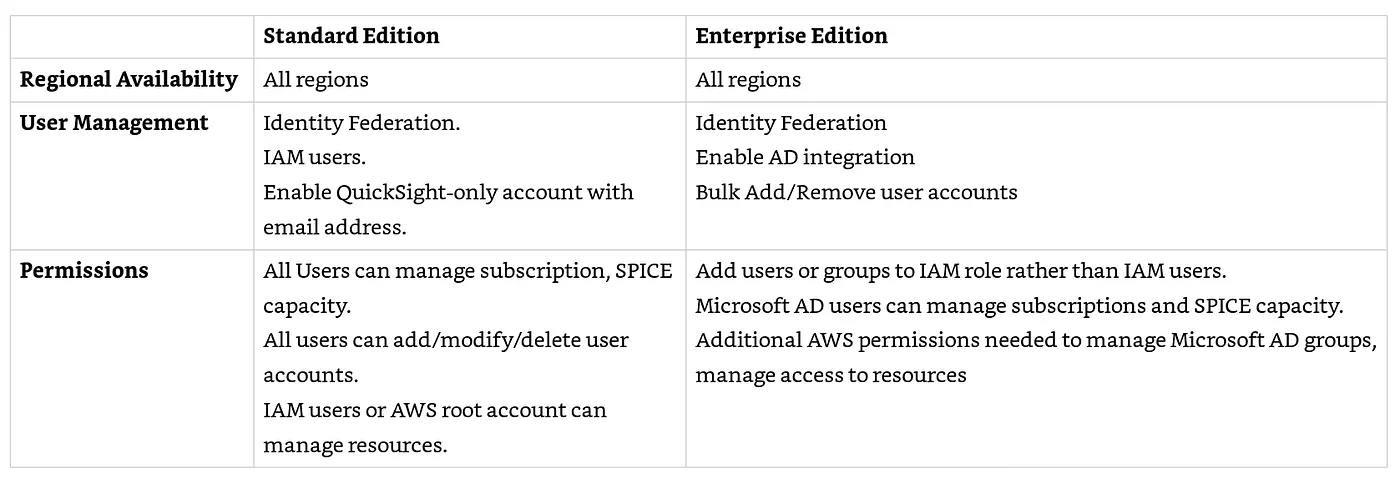
QuickSight的管理
QuickSight分成Standard 與Enterprise版本,功能性的比較表如下
預測分析(predictive analytics)
甚麼是預測(Predictive)分析呢?AWS自己的解釋還蠻囉嗦的。我們用這一本書(精準預測:如何從巨量雜訊中,看出重要的訊息?)白話一點來說明。
英文中的預測有兩個詞彙Forecasting 與Predicitiveing。傳統的組織做的大都是Forecasting,就是組織會照我們所做出來(分析)出來的資料這樣走(比較主觀的預測)。例如預測銷售季/年銷售,但往往這種分析往往失準。而Predictiving則是不做這樣的預測,而是根據所有客觀的資料分析出來之後。根據資料來應對我們下一步應該怎麼進行。
AWS的ML Stack
AWS的ML Stack有三個layers(如下圖)。這些AWS提供的ML平台讓所有與ML相關的人員與專家提供相對應工具來使用。

