AWS的大數據分析 — Part5 數據安全
我在前面的Part 1 — Part 4介紹了AWS大數據的資料擷取,資料處理與分析,最後資料視覺化。然而若沒有好的資料安全防護,我們的核心資料就會有外洩的狀況發生。
這一篇我們會來介紹在Part 1 — Part 4中所介紹的各項AWS所提供的各項資料處理服務(AWS S3, DynamoDB, Redshift, Elasticsearch, EMR, Glue, Kinesis)的資訊安全,。從資訊安全的基本驗證(Authentication),授權(Authorization),加密(encryption),到合規(Compliance)。
Shared Responsibility Model
在談到AWS的各類服務的資料安全之前,我們需要老生常談一下雲端運算的shared responsibility model。知道雲端運算的人對這個概念應該不陌生,簡單來說就是關於雲端運算的資訊安全,AWS會做好它該做的,你(客戶)也應該做好你該做的。也就是出了事先看看自己是不是自己的部分沒有做好就直接甩鍋給雲端運算平台業者。
而關於AWS的資料平台的資訊安全,AWS一供分為六個Layer(請參考下圖)。

根據上面AWS與你要負責的模型來舉例,例如我們在AWS跑一個EC2(VM),AWS負責從Hypervisor到physical layer到機房實體安全。而你就要負責VM(OS)各項安全,包含上patch, firewall的設定,跑在上面的Applciation security等。
AWS的Security Services
AWS提供的Security security符合了絕大多數的資訊安全要求 — C.I.A(Confidentially, Integrity, and Availability)。而關於AWS各種服務的合規要求可參考AWS的Compliance resources。
AWS提供五種方式來保護我們運行在AWS上的workload與Application。
- Data Protection — 包含了加密,密鑰管理(key management),與自動威脅偵測
- Identity and Access Management(IAM) — 進行 identities/resource/ permission的管理。
- Infrastructure Protection — 根據我們所定的規則來過濾流量來保護我們的web application。這些可以過濾的要求可以根據像 — IP 來源, HTTP header,HTTP body或URI string等。排除一些很基本的網路攻擊,如 SQL Injection or cross-site scripting.
- Threat Detection and Continuous Monitoring — AWS 負責infrastructure,因此會持續監控雲端環境中account的網路活動和行為。 我們在 AWS account中可以做什麼和不能做什麼有一定的限制。
- Compliance and Data Privacy — AWS 使用我們的組織遵循的 AWS 最佳實踐和產業標準,以自動化的方式為我們提供合規狀態的完整視圖。
下表是AWS在 security, identity, 與compliance的要求下所提供的各項服務

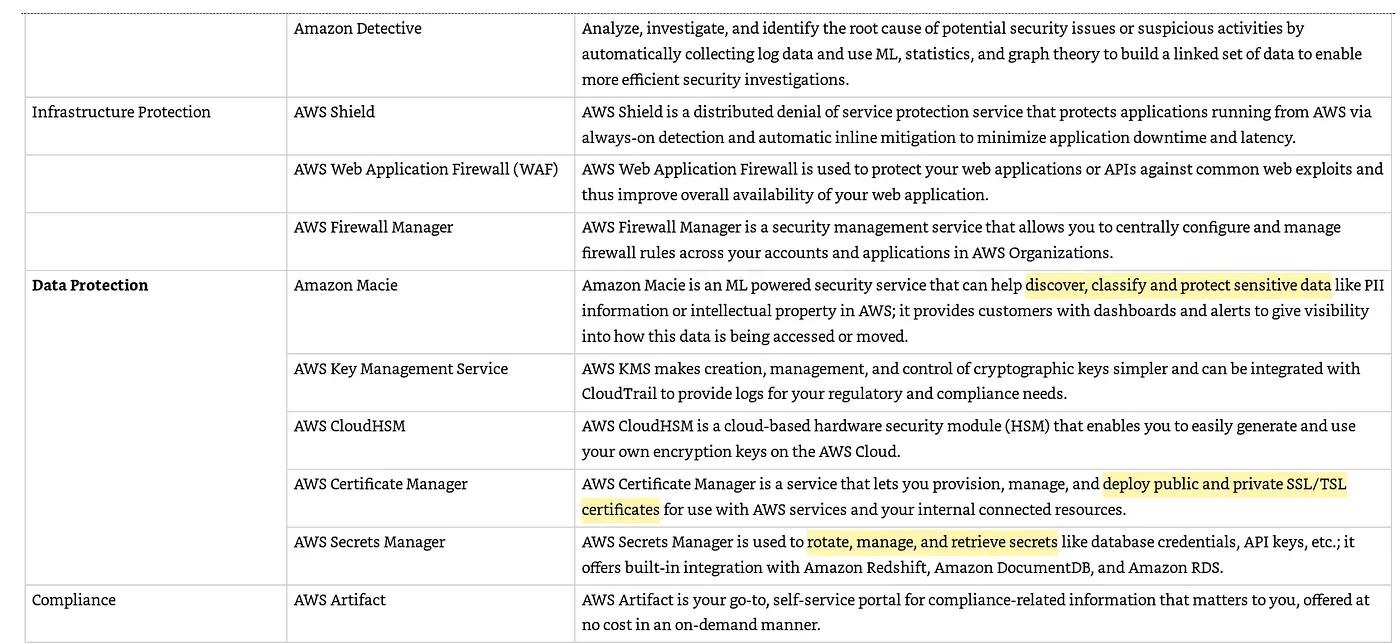
AWS IAM(Identity and Access Management) 概觀
AWS提供了多種的資源,而IAM就是用來對這些資源實施存取控制。IAM被使用在authentication(誰可以登入),與authorization(甚麼樣的服務,使用者可以存取)。
IAM User
這通常代表一個人或程式服務。IAM user會包含帳號與密碼的組合。這是最常被用在AWS accounts中的。而當我們第一次使用aws時,用email 與密碼登入的帳號稱為root account。對於我們的日常作業而言AWS強烈建議不要用root account,我們應該用root account create IAM user來進行我們在AWS的日常作業。
IAM user通常使用如下表所示的的方式來access AWS上的服務

IAM Groups
跟一般的電腦群組管理一樣,方便我們將一群IAM user分類。IAM group裡 IAM user會繼承其權限設定。但IAM Group不可以被當成 permission policy的Principal,比較簡單的方式是將這個存取政策一次attach到多個需要的IAM user中。IAM Groups有以下的特徵:
- 一個group可以有許多IAM user,一個IAM user也可以隸屬多個group
- Group裡不可以含有另一個Group(也就是沒有sub-group的概念)
- 一個AWS account最高可以有300個Group
- 一個AWS account可以有5000個user,而這5000個user可以同在一個Group
IAM Roles
IAM roles是我們可以在具有特定權限的account中建立的 IAM identity。 IAM roles類似於 IAM user,因為它是具有permissions policies的 AWS identity,定義了這個identity在 AWS 平台上可以執行的操作。 roles與users的不同之處在於它不是與一個人(如IAM users)唯一關聯的,並且可以由可能需要它的任何人來關聯起來。 此外,與users不同的是,roles沒有諸如密碼和訪問密鑰之類的long-term credential。 相反,assuming roles將導致為roles sessions提供臨時安全憑證。
當我們使用roles時:
- 我們可以使用roles將權限 delegate給需要存取資源的人(也就是將roles attach 在IAM user)
- roles可以給於一些需要暫時性存取AWS資源的人,例如外部使用者或程式
- Roles可以被使用在非AWS的驗證系統,例如Microsoft的AD
- Roles可以給與第三方的稽核權限來執行稽核工作
以下表格為AWS所提供不同類型的role

AWS EMR Security
我們在Part 3介紹過 EMR cluster。不論是暫時性或長期運作的 cluster,它都運行在VPC中。而VPC可以讓我們用網路的方式進行存取控制,如private IP address ranges, subnets, routing tables, network gateways。因為EMR的底層就是EC2。我們可以將cluster放在 Public or private subnet,如果是public subnet就需要有 Internet gateway才能讓外部的人或服務連到cluster。
當我們在create cluster時,可以指定要放在哪幾個AZ中。而cluster啟動後其相對應的Security Group也開始運作。
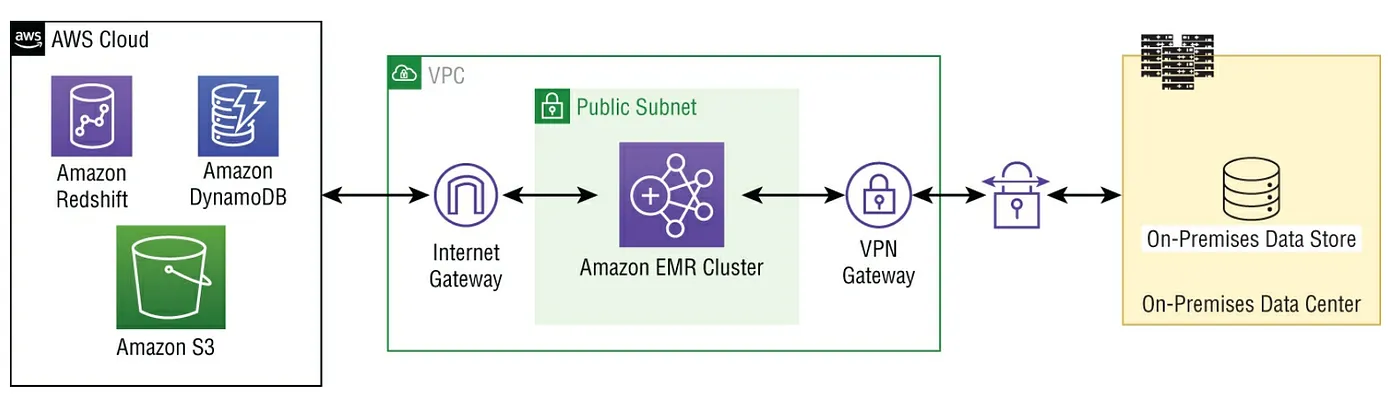
Public Subnet
如剛剛提到的,如果我們是把cluster放在public subnet中必須要把Internet gateway attach到該subnet,這樣才可以連到AWS其他的public endpoint服務中(如S3或DynamoDB)。但如果該AWS有提供 VPC endpoint則可以透過這種方式連結,可增強效能與安全性不用透過Internet Gateway走Internet(參考以下範例架構)。
剛剛提到EMR的底層是由EC2組成的,而知道EC2的人都知道我們是用Security group來控制進/出的網路連線。在這裡EMR提供兩種Security Group,一種是EMR代管的,一種是我們自行定義的。
AWS EMR Managed Security Groups
如它的名字所示,這是由EMR代管的security group。這一種的security groups唯一的目的就是控制cluster內部通訊與其他AWS resource的通訊。如果需要讓cluster外的人或Application存取,我們可以修改該security group或增加新的。AWS在這裡強烈建議不要去修改這個代管的security groups而是去增加新的rules以免不小心更動到重要的rules接著cluster就死給你看。
其中一個代管的security groups名稱是”ClasticMapReduce-master”,這個預設好的rule讓 Ip是 any(0.0.0.0/0)透過SSH來連接。所以最佳實踐應該是我們需要過濾這個source IP。下表為EMR代管的security groups名稱

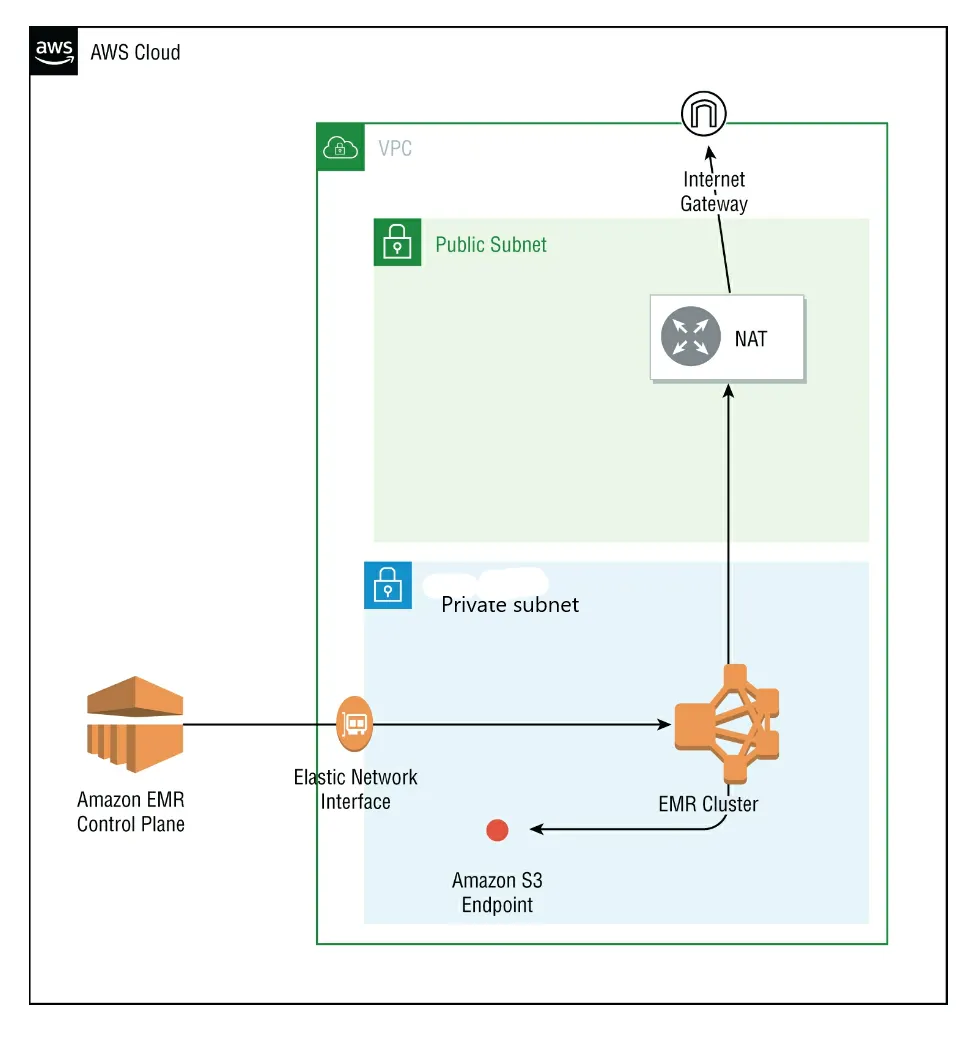
Private Subnet
private subnet與Public的不同點在於如果AWS 其他的services 有提供VPC endpoint的方式,哪它就會使用這種方式。如果該服務沒有VPC endpoint的方式來連就要需要用NAT instance或Internet Gateway來往外連。可參考以下範例架構
在 EMR的Console關於security的設定有三個,分別是 Security Configuration, VPC subnets, 與Block Public Access(如下圖)
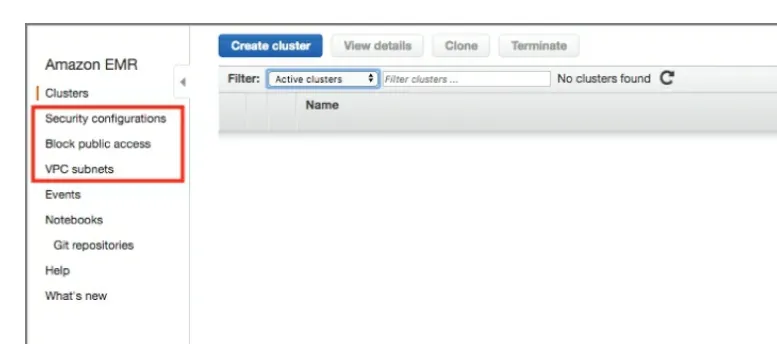
Security Configuration
這一個設定做好後可以套用到多個cluster上。再者這裡的設定可以分為四類,分別是加密,驗證,EMRFS的AIM roles與 AWS Lake Formation整合。
加密(Encryption)
Data at rest的加密會在 EMRFS(S3)與HDFS的data store。EMR同時耶支援Data in transit的加密。在Security configuration中的資料加密選項有: S3 encryption, local disk encryption, 與 data-in-transit encryption。
S3 加密
這是針對資料在S3中的加密,也就是 EMRFS(EMR file system)object在S3中的read/write。EMR支援以下幾種加密選擇
- SSE-3
- SSE-KMS(使用KMS的master keys來加密被加密資料的key,加密發生地在server-side)
- CSE-KMS(使用KMS的master keys來加密被加密資料的key,加密發生地在client-side)
- CSE-Customer(必須提供custom key提供location [S3 bucket和key provider class)
當我們選擇完成對要S3的bukcet做哪種加密,原來在S3上的bucket如果也有其他加密演算法的話其設定就會被EMR給覆蓋過去。而每個S3 bucket的加密方式(encryption modes and encryption materials)是可以個別選擇的。
Local Disk 加密
EMR在這裡提供了三種不同的加密
第一種: HDFS加密
HDFS不只是用來暫存資料的,同時也是會有資料從instance store volumes與EBS volumes來讀取與寫入資料的。當我們啟用 local disk加密時有幾個選項可以選擇:
- Secure Hadoop RPC(Remote Procedure Calls) 這個設定在 core — site .xml設定檔中的 hadoop.rpc.protection 的設定中,啟用這個資料會在hadoop service與client端之間是加密的。
- Data Encryption on HDFS Block Data Transfer 這個選項是讓我們在啟動data node的資料加密的。這個設定在 hdfs-site .xml設定檔中的 dfs.encrypt.data.transfer 把它設定為 true,它就會用 AES-256的方式加密。
- Transparent Data Encryption on Amazon EMR 這個設定預設是沒有開啟的,需要的話要手動開啟它。這個設定是針對 HDFS encryption zone,也就是我們指定一個特定的HDFS路徑進行加密。每一個 encryption zone(也就是路徑)都會他們自己的key。EMR預設是使用 KMS的但我們也可以選擇其他的key management services。
第二種 Instance store 加密
因為EMR的底層是EC2 instance,所有的hadoop 軟體與資料都跑在上面。所以我們也可以對其instance store來加密。加密的type有兩種(如下表)

第三種 EBS volume加密
針對EBS Volume,AWS預設都是加密的。所以不管我們有沒有在EMR的啟用local disk encryption,這個預設都是有效的。不過當我們啟用local disk encryption,EBS volume的預設加密就會被EMR給取代。
下圖為我們在設定EMR上面設定S3加密與local disk encryption會看到的畫面
Data-in-transit encryption
根據EMR不同的版本提供了以下針對特定的Application 看到的加密(在security configurations頁面會看到)
- Hadoop
(a)使用https的方式在shuffle時加密,(b)Secure RPC calls in Hadoop,剛剛有稍微介紹過。(c)Data Encryption on Block data transfer。 - Hbase
從EMR 5.10.0開始我們可以開始使用Kerberose在cluster內的做驗證。詳情可以參閱AWS文件庫 - Presto
任何在 Presto node的內部通訊都會用SSL/TLS的方式加密。 - Tez
Tez是對Hive query的runtime,可以用來取代MapReduce。而當Tez要shuffle data時,它會使用TLS在hadoop node之間加密 - Spark
(a) Spark在components內部RPC通訊會用AES-256加密(從 EMR 5.9.0開始)
驗證(Authentication)
Security configuration允許我們使用Kerberos來做為驗證系統。它使用密鑰加密來提供強身份驗證,以便密碼或其他credentials不會以未加密的方式通過網路發送。當我們啟用使用Kerberos的驗證之後,EMR會設定其運行在Cluster內的Applications, components與subsystems這些要互相做驗證。
EMR還提供使用專用的KDC(Key Distribution Center)或也可以用外部的KDC。我們可以設定其ticket的lifetime,預設是24小時。我們也可以設定 cross-realm trust,意思是我們讓principals(通常是使用者)從不同的Kerneros來源驗證其在Cluster內的Application。這個就稱為 cross-realm trust,詳情可參閱AWS的文件庫。
EMRFS的 IAM Roles
這是我們要永久儲存EMR資料的建議選項。當EMR運作時,EMR會使用我們已經定義好的 service role(裡面已經有定好的permission)被attach到EMR的cluster來access S3。所以無論我們在上層做些甚麼。EMR都會用這個service role來access S3路徑。
不過基於上層的不同的 level的多個user對 EMRFS內的不同資料的管控,我們可以使用 IAM role(fine-grained access)的方式來實現。這個role定義的在S3裡可以做些甚麼操作。
在Security Configuration中,在”IAM roles for EMRF”選項中我們選根據不同的role對應其identifiers(user, groups, S3 prefix),如下圖
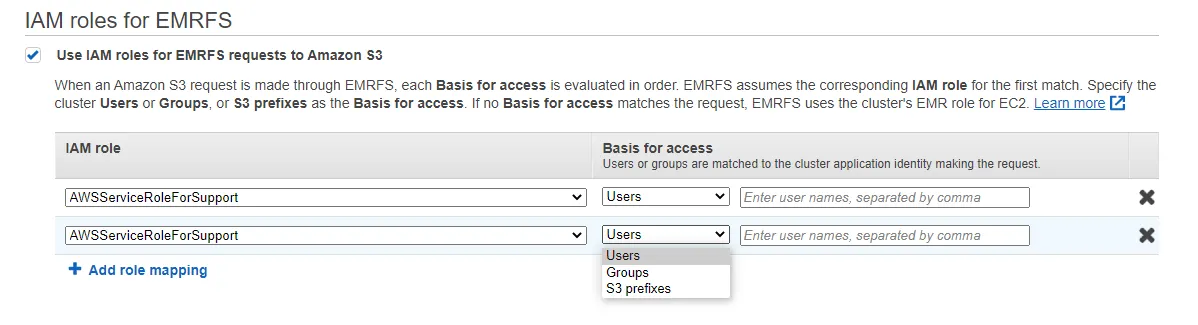
哪麼 IAM roles在 EMRFS是如何作業的呢?
當我們定好roles mapping之後就可以對S3 make request,假如request match basis(user, group, S3 prefix)的存取,cluster中的EC2就會assume成哪一個role來進行其作業。
當接收到request時,EMRFS會由上到下檢查符合哪一個role,意思是不只role mapping的排序很重要,這個role在S3的 policies也相對重要。假如都沒有符合的,EMRFS最後就會用我們在create 這個cluster時所用的role。
AWS Lake Formation整合
我們可以用 AWS Lake Formation 來建立在AWS Glue Data Glue的fine-grained column-level 來控制使用者可以用到那些columns/rows。 AWS Lake Formation也可以讓我們啟用對 EMR與 Apache Zeppelin的 federeated single sign-on(與 SAML相容的驗證系統)。
為了讓EMR與 Lake Formation的整合,以下條件需要被滿足
- 我們的identities需要是以 SAML為基礎的 identity provider,像是 Active Directory Federation Service(ADFS)
- 我們的metadata必須放在 AWS Glue Data Catalog
- 我們會使用 Apache Zeppelin 或EMR notebooks來access在 Glue與Lake formation的資料
- 我們需要有操作 AWS Lake Formation的權限
Block Public Access
設定完Security Configuration之後就需要考量Public access的設定。這一個設定預設是開啟的,並且其設定是讓anywhere(0.0.0.0/0)IP可以透過SSH來連接EMR。
VPC Subnets
此一選項我們剛剛有提到,主要是將EMR cluster放在Private subnets能達到高效的網路與網路的安全性。
在建立 Cluster的安全選項
我們在建立Cluster時會看到 quick與advanced兩種選項。
在快速(Quick)選項中在Permission選擇有default與custom。Default選項是EMR已經幫我們針對EMR roles與EC2 instance profile做好的roles。其中 EC2 instance profile是用來讓底層的EC2用那些role來運作EMR上面的Application與提供access 其他AWS 服務的。而Custom則是自行定義的。
而Advanced 選項則有更多的安全選項(如下圖):
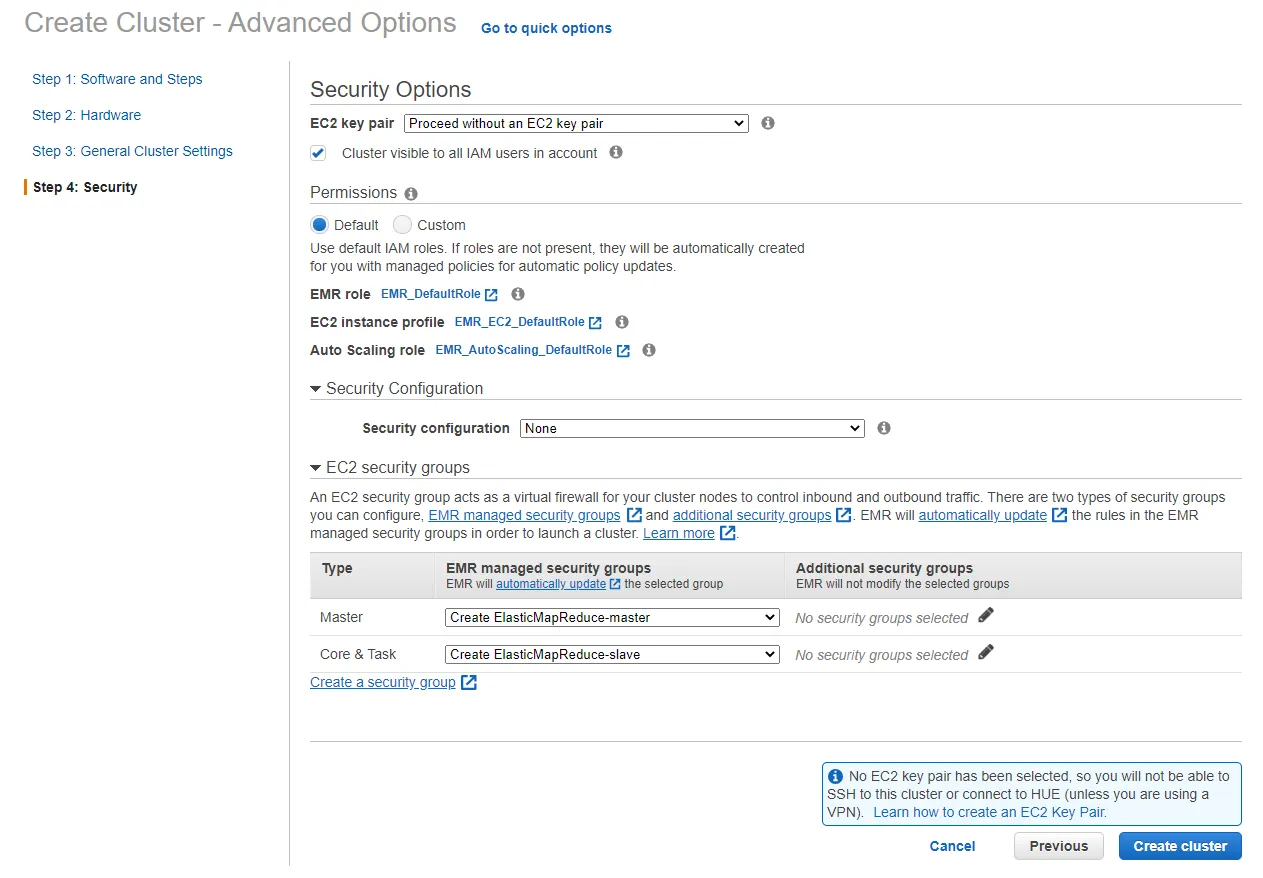
首先我們可以看到EC2 Key Pair的部分,這一個的使用方式與一般我們在連線EC2 instance的key pair是一樣的。再來是 Cluster Visible to All IAM Users in Account這一個選項,預設是勾選的。主要是讓在同一個AWS account中的IAM user可以看到這一個你做的Cluster出現。
Permission的部分有預設與客製的方式,剛剛有提到過了。有一個部分要提到一下,Default mode 與Advanced在這一部分只有Advanced mode會顯示到AutoScaling的roles設定,主要是當loading增加時EMR有權限執行AutoScaling的動作,在Default一樣有只是沒有show出來。Security Configuration在之前我們用很大幅的篇章提到過。EC2 Security Group我們一樣在之前有提到過。
AWS S3 Security
S3的儲存是在AWS的主力,幾乎所有AWS的其他服務都會用到,也是建立AWS Data Lake的底層。這一段我們會就介紹S3的資料加密,對S3中的resource的access control,不同的 kuckets與files的logging與S3的保護S3資料的最佳實踐。
S3的資料存取管理
在S3中我們需要管理的resource中有, buckets, objects與其他 sub-resource,如 lifecycle configuration, website configurations與 version configuration。管理AWS account與 user對其resource的控制會編寫在access policy,而 Owner則有完全的控制權。Owner有權給予其他人access的權限,這都會寫在一個access policy(JSON格式)。
Access policy有兩個種類: 一種是 resource-based policies另一種是 user policies。
Resource-Based Policies
這是將Policy attach在resource(通常是bucket)上的做法。這邊分為 ACL與 bucket policy。
ACL的方式是每一個bucket與Object都有他們相對應的ACL,這基本上是一個授權列表,用於標識授予的權限以及給誰權限。ACL被用來給其他AWS account最基本的read/write權限與使用S3特有的 XML schema.
Bucket Policy(JSON格式)是在bucket level(包含其object)上給予其他AWS account與IAM users權限。Bucket policies會輔助或是在某些情況下取代ACL。在Bucket policy的編寫中我們會看到四個部分並加上一個範例(如下),分別是
- Effect: 能不能做 — Allow 或Deny,在範例中我們看到是Allow允許。
- Principal: 這通常使指User或是某個Application要access,星號代表不指定,都可以access。範例中就是用星號。
- Action: Principal能做些甚麼操作,範例中我們看到的是對Object有read permission
- Resource: 指定哪一個resource會被這個policy影響到,範例中我們看到的是analyticscertbuckts這個bucket與裡面所有的Object

User Policies
這是將policy attach到 IAM users, groups與roles中。以下為一個user policies範例

不管是bucket policies或User Policies都可以單獨或一起使用。當S3收到一個access request它會先查看所有的access policies來看這個request有沒有符合其中一個來給予權限,如果都沒有就會deny這個request。在Runtime時,S3 會將所有相關policies(user policies、bucket policies、ACL)轉換為一組policies進行評估,然後根據發出request的上下文進行評估。
大多數的Request都需要先經過驗證(authentication)但也有不用驗證的狀況,可能是這個bucket是公開給外面的人寫入資料,或Bucket ACL給予全部的 user group或匿名的人 寫入資料或full control狀況。但這種狀況在安全性的最佳實踐是不要有。
Resource-based policies包含了 bucket policies, bucket ACLs, Object ACLs。至於在甚麼情況下該用哪一種,AWS提供了一些範例來供我們參考。詳情可參閱 AWS的文件庫。
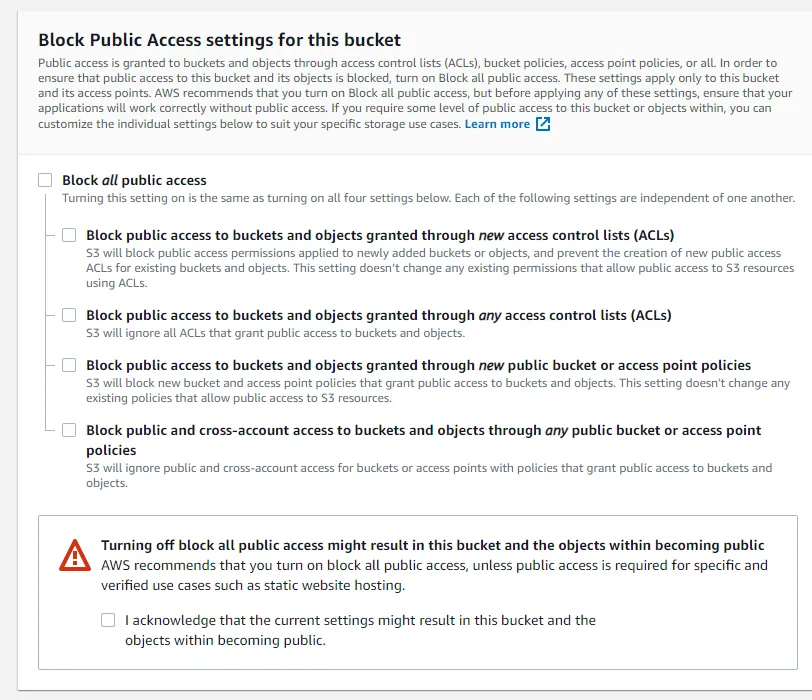
Blocking Public Access
這是一個account level的設定,並且是對控制我們在S3上的access point, buckets與 account來進行 public access。簡單的來說就是進行白名單管理,在create bucket時這個選項是開啟的,也就是說當一個bucket 被create後沒有人(除了owner跟root account或S3的admin)可以去access它。這個選項存在的好處是當我們對我們的bucket 不小心設定到public時,我們的這個設定就無法完成,有防呆的效果在。
但我們可以看到這一個選項底下有其四個子項可以選擇,這是根據可能有的例外狀況我們可以選擇的(如下圖)
S3的Data Protection
在S3針對Object的加密有以下四種方式
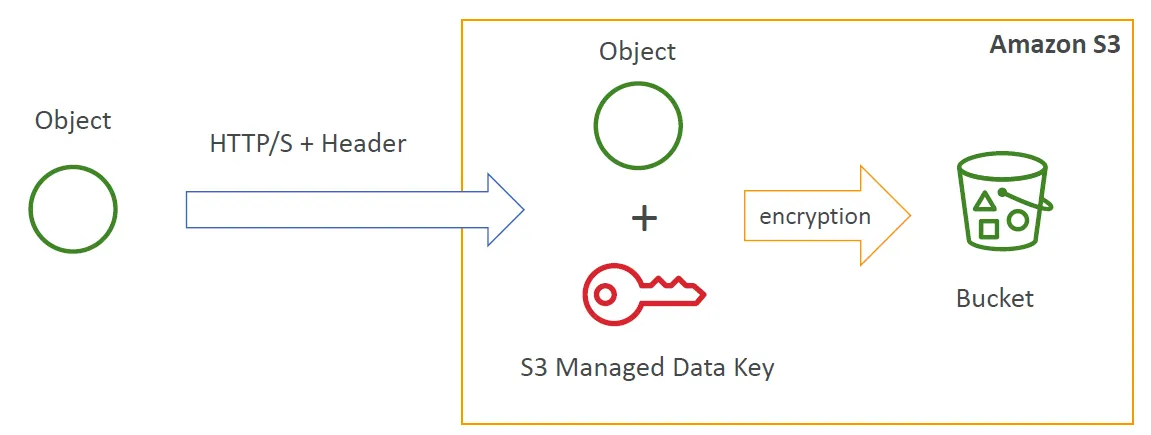
- SSE-S3 : 加密的系統與key完全由S3來管控,使用者完全不用管理。
- SSE-MKS: 使用AWS MKS(Key Management Service)來管控加密的key
- SSE-C : 我們要自行產生並管理加密的Key
- Client side Encryption: 檔案在本地端加密好才送上S3 bucket
SSE-S3加密
加密的系統與key完全由S3來管控,並且是在server side做加密,加密法是AES-256。我們用http request傳送檔案時在 header中要告訴S3我們要加密的方式 — " x-amz-server-side-encryption”: “AES-256”
SSE-KMS加密
使用KMS加密的好處是我們可以自己控制key的管理並且可以有audit紀錄可以查閱。在http的header中要使用這樣的方式是 — “ x-amz-server-side-encryption”: “aws:kms”
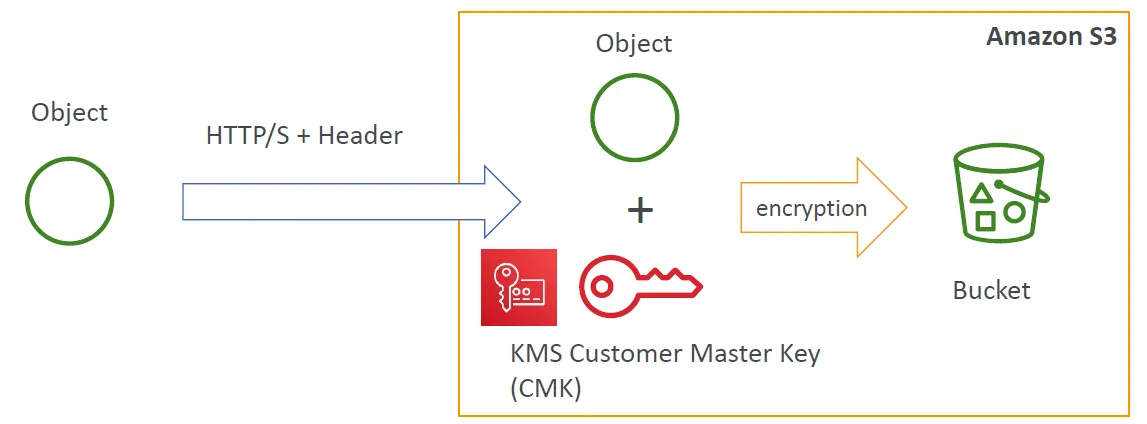
但選擇這種方式有一些限制存在。但我們上傳資料時S3會對KMS 產生 GenerateDataKey的API call.而在下載時會有Decrypt的API call。這些在特定時間內會有呼叫次數的限制,根據不同的區域會有每秒 5500/1000/30000的次數限制。
SSE-C加密
這個方式是由我們自己產生與管理加密的key,而是在每次上傳檔案時把加密資料的key一起送上S3。S3會利用這個Key加密,完成後S3就會丟掉這個key不會保存它。由於每次都會把key 放在header中所以一定是使用HTTPS的方式進行傳送,每次的傳送檔案上S3的http request一定都要附上。
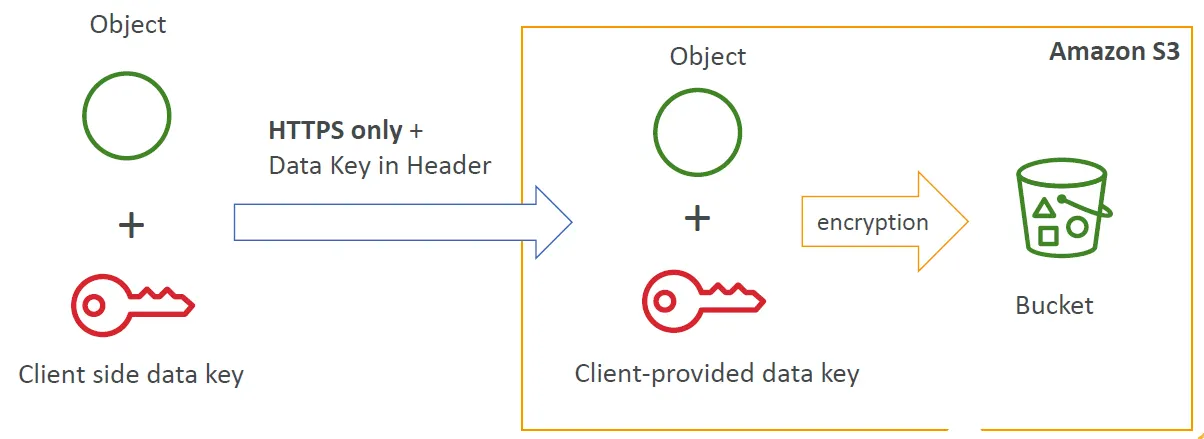
Client Side Encryption
檔案的加解密都需要在本地端進行
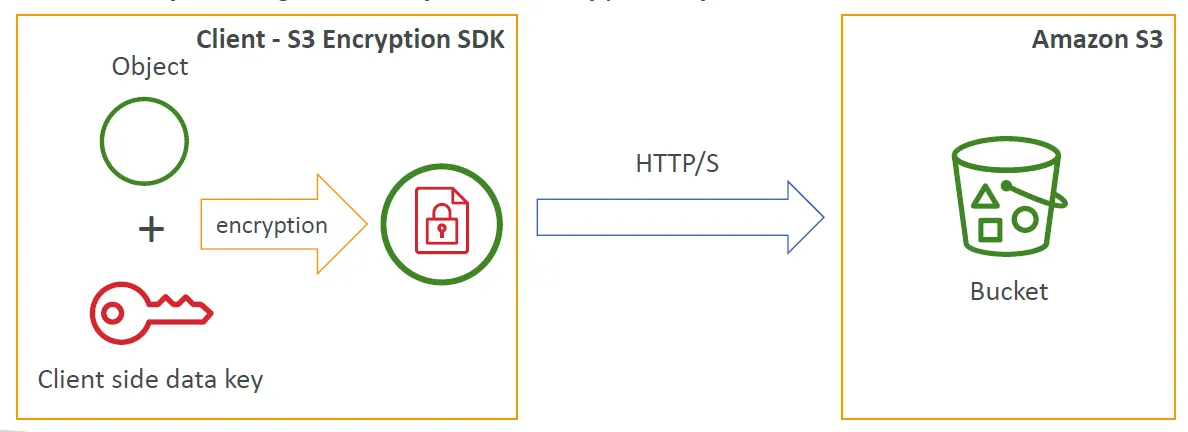
AWS S3同時支援http and https的方式傳送資料,但https是建議的選項。
S3的Logging與 Monitoring
S3使用多種的工具監控與稽核S3的resources。分別有以下一些重要的工具
AWS CloudWatch Alarms 這是對其S3的一些效能監控。在達到一些設定的界線之後該服務會使用AWS SNS發出通知或是使用 autoscaling policy(S3用不到這個)
AWS CloudTrail Logs 這是察看S3的稽核紀錄,例如可以看到這個request從哪個IP來的,誰發出的request,何時發出的與其他一些額外的details。
AWS S3 Access Logs 也是用還追蹤那些request到達S3這裡。這個logs主要用在 security audition與讓我們知道關於S3帳單的使用量等數據。這個服務本身是免費的,但產生的logs資料(放在S3 bucket)存放要收費。
AWS Trusted Advisor 這是AWS針對我們整體在AWS上使用到的各項服務給予最佳實踐的建議,包括的安全還有較省錢的服務等級或規格建議。而針對S3的安全部分會從一些security context來判斷,包含有:
- S3 bucket的Logging configuration
- S3有開放的權限做安全檢查
- 會檢查沒有開啟版本控制或是版本控制功能暫停的bucket來檢查
S3的Security最佳實踐
- 開啟 account-level的 Block Public Access功能
- 使用access point來限制Application對其S3的權限
- 盡量使用 VPC endpoint與 access point
- 在bucket policy強制指定用 TLS
- 所有的Object都加密,特別利用 SSE-KMS與 SSE-S3方式
- 啟用 object lock, 版本控制,與MFA delete來保護重要資料
- 使用AWS的監控工具,如 CloudTrail與 AWS Config
AWS Athena Security
Athena的存取管理
Athena一樣使用IAM來對其控管。User對Athena的操作就是run SQL query,而為了可以Run SQL query需要有以下的權限:
- Acess到Athena API actions,包含 Athena workgroups 的。
- Access到底層的storage,主要是access S3因為資料都在哪裡
- Access Glue Catalog的權限,因為metadata在哪裡
為了達成上三個要求,我們的 IAM principals需要identity-based policies。這個policies會定義那些可以操作那些不可以操作。Athena 無需user嘗試確定 Athena 需要哪些操作才能正常作業,而是提供了兩個託管policies,這些policies易於設置,並且會隨著services的發展和新功能的發布而自動更新所需的操作。 policies如下:
AmazonAthenaFullAccess
這會給予 Athena的最大權限,包含 Glue, S3, SNS, CloudWatch。這個對沒有Athena使用經驗的人是建議選項。
AWSQuickSightAthenaAccess
這是讓QuickSight要連結Athena的人使用的。這個權限通常也包含access Glue, S3。
如果是用ODBC/JDBC來連接Athean的話使用的一樣是AWSQuickSightAthenaAccess這一個policy。剛剛提到Athena的資料存放是在S3中,所以如果不適是用託管的policy需要仔細的在客製policy中設置在S3中適切的權限。
如果我們使用適用於Athena 的 AWS Glue Data Catalog,則可以為 Athena 中使用的DB和table定義resource-level policies。 Athena 僅在DB和table level提供fine-grained controls,而不在單一partition level提供。 此外,如果我們的 AWS Glue Data Catalog位於不同的account中(cross-account access),則 Athena 在撰寫本文時不支持該選項。
Athena Workgroups 的存取
Athena workgroups是一種resource type,能夠在 users, 團隊或Application之間分離 query execution與query history。由於是resource所以要用resource-based policies來控制存取。
Athena的 Federated Data Access
如果我們是使用外部的驗證系統(如微軟的AD),哪Athena也支援此種驗證方式。這需要使用 JDBC or ODBC driver搭配能支援 SAML 2.0 去access ADFS (Active Directory Federation Services)3.0並且啟用 client application去呼叫 Athena API actions。整個流程可參考以下架構圖
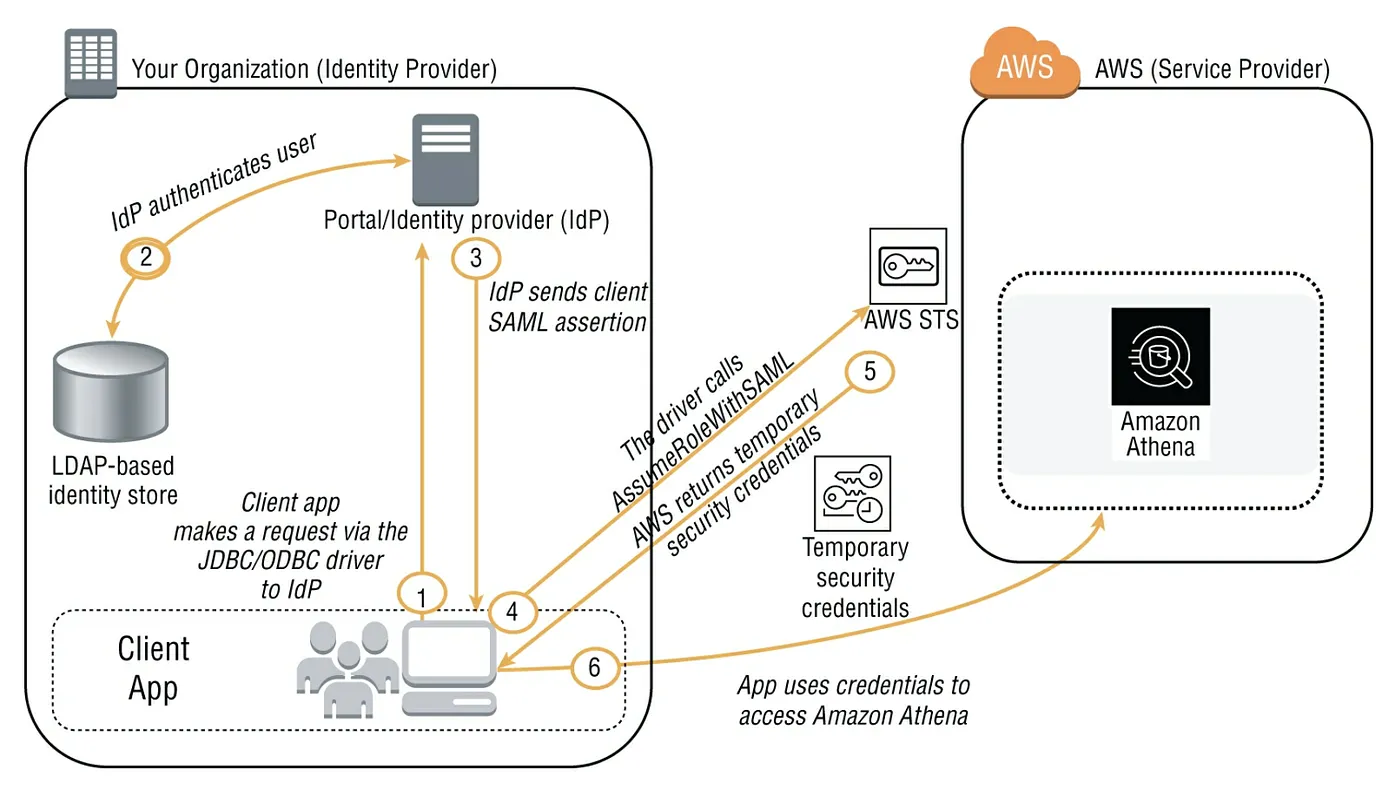
Athena的資料保護
Athena是一個資料處理與分析引擎,能對擷取來源資料(Athena不會修改來源資料)並且在其內部進行資料轉換與創建/更新新版本的資料。
Athena使用的是 schema-on-read的模式,意思是當Athena從來源端讀取資料時該資料的schema也被解析並儲存在我們的source engine中。Athean允許我們用DDL(Data Definition Language)的方式修改data catalog。
運作Atehan主要會產生query出來的資料與query history。Query結果是存放在S3中(由 workgroup預設的位置),並且對其bukcte有full control的權限。Query history與Query的結果會保存45天。
Athena的資料加密
Athena讓我們能已加密的資料與加密query的結果還有也能加密存放在 Glue Data Catalog的metadata。關於在S3的加密,我們在之前S3的部分已經介紹過了,但Athean不支援 SSE-C與client side的master key與 asymmetric keys的加密(意思是加密只能能server side做)。
Athena workgroup剛剛有提到是讓我們強制對query result進行加密。但如果是使用JDBC/ODBC來連接的話,我們必須為加密類型和 S3 stage location配置適當的driver。
Athena使用多種的資料來源,但主要是S3,它會使用TLS來傳輸資料。而TLS也會用在Application要與Athean連結傳輸資料使用。JDBC/ODBC預設也是使用TLS傳輸資料。所以Athean與其他的服務通訊HTTPS就是預設的。
Athean與 Lake Formation
我們在前面討論了 Lake Formation,討論了它如何在 Amazon S3 中的Data Lake之上提供授權和管理。 Lake Formation 提供了一種管理資料權限的簡單方法,以提供fine-grained的access control。 我們可以通過向service註冊我們的datasets來使用 Lake Formation 管理column-level的權限。
我們可以使用 Athena 來查詢已向 Lake Formation 註冊的資料以及尚未向其註冊的資料。 Lake Formation permission model僅在我們查詢向Lake Formation 註冊的metadata時啟動。
以下是這種情況下的一些場景:
- 如果你的Data 在S3,但metadata沒有註冊到Lake Formation, 所以不會有 Lake Formation 的權限不會被使用而是用 在S3中的IAM policies
- Data在S3,而metadata也註冊給了 Lake Formation,這樣就有Lake Formation的 FGAC(fine-grained access control)可以使用
- 若Athena的result在S3中,我們無法註冊這一類的資料到Lake Formation
- Athena的 query history無法由Lake Formation來控制權限,要由Athena workgropu來控制
AWS Redshift Security
Redshift提供了以下的功能來保護我們Redshift的Security:
- End-to-end的資料保護,包含 data at rest/ data in motion的加密
- 整合 IAM與Federation SSO的 SAML identity provider
- 使用VPC來達成網路隔離
- 使用DB security model(users, groups, privileges)
- 針對合規與監控的Audit logging與通知
- 符合SOC1/2/3, PCI-DSS,FedRAMP,HIPAA的合規認證
Redshift的Security Level
Redshift在四個層級上來達到資訊安全: (1)cluster management, (2)cluster connectivity, (3)DB access(, 4) temporary DB credentials跟 SSO
(1)Cluster Management
使用IAM來控制對Redhsift cluster的 create/configure/delete。
(2)Cluster Connectivity
使用Security Group讓AWS instances連結到 Redshift cluster。根據這個網路設定,Redshift的compute nodes是存在於 private/internal VPC之中,而在這裡只能讓leader node來連結。Leader node是同時存在於 compute node的VPC與我們(客戶)的VPC中。而compute nodes ingest資料可以直接從AWS其他的服務,如S3, EMR, DynamoDB或backup等等。Reshift cluster只能存在於一個subnet/AZ中。
Redshift cluster預設是lock down(白名單式管理),沒有user可以連結cluster。如果讓user可以access需要使用Security Group來管理。而EVR(Enhanced VPC)是一個讓 Redshift COPY, UNLOAD與backup可以透過 VPC endpoint的方式(高速,安全)進行作業,而不用走Internet。EVR也可以用在Redshift Lakehosue。
(3)DataBase Access
Redshift是一個Relational DB也因此支援schema, users, groups, tables, view等概念,我們在Part 3有詳細的介紹。而要存取Redshift DB則是用user account來控制。我們在create 一個Redshift user accounts可以給它的權限有CREATE USER, CREATE GROUP, GRANT 或 REVOKE SQL。
當我們create一個Redshift cluster時,我們就是該cluster的superuser對其cluster內有完全的控管權。而Redhsift能提供 row-/column-level security,有以下三種方式:
- Create 一個 materialized view(SAP HANA也有這樣做)
- 從user的角度來指定該user能查詢甚麼column or row,以此來定義出column/rows的資訊安全
- 透過 Redshift 的Lake formation integration讓 Redshift Lakehosue也能支援fine-grained column-level policies
(4)Temporary DB credentials and SSO
要登入Redshift DB中, Redshift支援使用 IAM credentials或使用SSO的方式,透過SSO的方式該identity provider需要能相容SAML 2.0。所以這一個外部IdP給予的授權user我們需要給它們一個IAM roles來明卻它們可以執行那些操作。而當我們generate 一個 tyemporary DB credentials也可以照此方式辦理。
為了讓Redshift可以支援SSO,以下為一些必要條件
- Redshift JDBC/ODBC driver
- 能與SAML 2.0相容的IdP(如微軟的 ADFS或 Azure AD)
順序步驟如下:
- 設定IdP與federation
- 為Redshift 建立一個相對應的roles
- 設定DB access(如 CREATE GROUP, GRANT等)
- 使用 jdbc/odbc連結Redshift
Redshift的資料保護
Redshift提供Data attransit與Data in motion的資料保護。
Redshift clsuter使用透過硬體加速SSL的方式來與其他AWS服務通訊(Data in motion)。而在Data at rest部分,Redshift可以啟用DB level的加密。當我們啟用加密時,Data block, system metadata與snapshots這些資料都會被加密。要不要加密這件事可以在create cluster時決定或是事後再修改。不過當我們事後修改成KMS的加密的話,Redshift其實是將資料migrate到新的有加密的redshift cluster, create new cluster 與migrate 資料都是自動的。
KMS-based是建議的選項,因為KMS可以support key roation或自帶我們的key。
Redshift支援四層的encryption, 也就是一層key包覆下一層的key。(參考下圖)

第一層是Master key — 這個key可以是CMK(customer-managed key)或是由KMS產生的,用來加密 cluster encryption key
第二層的cluster encryption key會來加密 database encryption key
第三層的database encryption key用來加密data encryption key
第四層的data encryption key用來加密實際的data block
Redshift的 Auditing
Redshift提供兩種選項的稽核紀錄,來稽核database-level actitives像是哪個user 登入何時登入,分別是 audit logs與system tables。 audit logs會存放在S3中。
Audit logs會包含以下三種類型的logs
- Connection log — 內容是所有的連線嘗試,連線紀錄,離線紀錄。
- User log — 內容是 database user definitions的異動。
- User activity log — 這個資料是提供對DB 有submmit的Query,通常是用來debugg的。幫助我們了解有那些Query送到DB裡,包含User執行與DB本身自己執行的。
System Tables顧名思義就是稽核資料放在 system tables中,會有以下兩個system tables是與資訊安全相關,至於其他system tables的說明可參考AWS文件庫
- SVL_STATEMENT_TEXT — 這是一個基於system table的system view,這是目前系統運行的狀態。這個view是開放給所有的user可以看得,不過它們只能看到屬於它們自己的資料,superuser可以看到全部。
- STL_CONNECTION_LOG — 這是system table base的,用來記錄連線資料而且只有superusers可以看到。
Redshift Logging
Redshift的日誌紀錄是由CloudTrail來負責的,所以要看日誌紀錄要到CloudTrial中去檢視,不過CloudTrial的lgooing 只有到 service-level activities。CloudTrial的資料是放在S3中,並且有lifecycle,預設是保留最近90的log(不另收費)。當然可以存放超過90天,但要另外收錢就是。
AWS Elasticsearch Security
AWS Elasticsearch(以下簡稱ES)提供種多方式來保護其服務與資訊安全。從控制access我們的domain:使用Kinana來控制驗證(Authentication)到資料的加密,與提供 fine-grained access control,最後是 logging與 monitoring。
AWS ES有三個主要的Security Layer:
- Network — 在還沒碰到ES之前提供的第一層防護
- Domain Access Policy — 當Network通過後到達ES domain或 domain endpoint,我們可以使用 resource-based access policy來allow/deny這個request到特定的URI。如果最後policies都找不到match的rule,ES就會reject這個request。
- FGAC(Fine-grained access control) — 當前兩關都通過後,FGAC會檢查user credentials與驗證或deny這個request。若通過FGAC的驗證,就會開始對應這個user要套用哪一個role。
ES的網路設定
我們可以將ES放在VPC內或是讓它變成Public access。這些可以在create ES時來決定。(設定畫面如下)

若是使用VPC access的方式,ES對其AWS的其他service就不需要透過 Internet Gateway, NAT device或VPN的方式。如上圖所示我們可以將ES設定在多個AZ中來達到HA的目的,而這也意味ES會在每一個AZ都有一個endpoint。
ES會針對VPC中的每一個data node設置ENI(elastic network interface)。而每個ENI的IP都會有一個相對應public DNS hostname(domain endpoint)。所以要access service要透過使用 public DNS service來解析。
使用VPC的限制如下:
- domain name 要用private(只存在VPC中)或 public endpoint在 啟用我們的domain時就要決定。
- 決定了之後就不能更改,如果要改就要打掉重建。基本上就是snapshots的方式重建
- ES domain的VPC建立好就不能再做變更
- 不能對ES domain使用 IP-based policies(因為security group已經有使用了)
ES與Kibana的存取管理
ES提供以下三種 policies type來對 ES domain進行管理
- Resource based policies
- Identity-based policies
- IP-based policies
Resource based policies
AWS ES的主要resource是 ES domain。同時我們也會有這個doamin的sub-resource,像是 Elasticsearch indices與 APIs。所以我們可以使用Resource-based policies,當我們 create一個doamin時也稱 domain access policies。這種policies明定principal(通常是user)可以對resource and sub-resource執行甚麼操作。以下範例為授予 user analytics-user可以在reource(domain是analytics-cert-domain)執行任何操作(action)。

在action這邊,可以執行任何操作的代號是(*)星號,如果要限制特定操作,都可以寫成: 如es:ESHttpGet, es:ESHttpDelete, es:ESHttpPost, es:ESHttpPut, and es:ESHttpHead。
Note:如果Policy有包含 IAM user or roles,我們就需要使用 AWS Signature Version 4(Sigv4)傳送一個 signed request。
Identity-based policies
我們也可以attach identity-based policy給IAM 的users或是roles。Identity-based policy明定誰可以access a service,甚麼操作可以執行,與甚麼resource允許操作。
identity-based policices是attach給principals(users/roles),因此policies中已經不用明定principals是誰了。
IP-Based Policies
這其實是 resource-based policies的一種變形。因為在policies中,principal是匿名的並且會帶有一個特定條件的element(source IP的描述)。會使用這種方式通常是來源是特定的,而且這些使用者不想用登入的方式。它允許我們使用 curl 和 Kibana 等client端或通過proxy server access domain。
以下範例為讓某個特定的IP range可對analytics-cert-doman使用所有的HTTP requests

Making and Signing ES Requests
所有rquests連到ES時是需要sign in的。如果我們的policies有明定IAM users or roles,sign in就是必須的。我們可以自己簽署 request 或使用像 Boto 3 這樣的 AWS SDK 為我們簽署request。 使用 SDK 對請求進行Signing始終是推薦的方法,因為它不僅可以簡化對請求進行Signing的過程,還可以為我們節省大量時間。
FGAC(Fine-Grained Access Control)
這是ES domain的第三層防護,FGAC使用roles的方式來對indices, documents,還有fields來細化其權限。
我們的access policies可能與 FGAC發生衝突,特別是當我們使用 internal user DB與HTTP basic authentication。我們不能使用username/password以及 IAM credential。 因此,如果我們啟用 FGAC,建議使用不需要signed request的doamin access policies。
哪FGAC是如何作業的呢?
下圖說明了當user使用 IAM credentials向 VPC 內的doamin發送request時 FGAC 何時發揮作用的示範流程。

下圖代表第二個最常見的配置,它是一個public ES domain,啟用了FGAC,使用沒有IAM principals和internal user DB中的master user的access policies。

FGAC可以在已經存在的ES domain啟用,但一經啟用後就無法關閉它。
Kibana的驗證(Authentication)
FGAC對Kibana是一種plug-in。我們可以使用它來管理users, roles, mappings, action groups,與 tenants。
如果我們選擇使用 IAM 進行user management,則必須為 Kibana 啟用 AWS Cognito 身份驗證並使用user pool中的credentials登錄以access Kibana。 來自 Aws Cognito identity pool的 assumed roles其中之一必須與我們為master user指定的 IAM roles匹配。
如果我們是使用 internal user DB,我們就要用master username and password來登入。Kibana使用HTTPS。
AWS ES的資料保護
ES針對 data at rest 與data in motion的資料加密如下
Data at rest的加密 — 這個加密分為以下兩部分
- AWS KMS : 用來保存與管理 encryption key
- AWS-256 : 實際進行加密的演算法
當加密被啟用後,下列的domain裡elements會被自動加密的
- Indexes
- Elasticsearch logs
- Swaps files
- application directory裡的資料
- automanted snapshots
而以下是開啟後不會自動加密的
- 手動的snapshots — 要加密的話要用S3 server side的加密,在其含有snapshots的bucket進行
- Slow logs and Errors Logs
AWS ES不支援 非同步的 customer master keys
而在Data in motion方面,ES預設在VPC內的traffic是沒有加密的。如果我們要啟用node-to-node的加密,ES使用的是TLS。
AWS KInesis Security
Kinesis的存取管理
在這裡我們一樣是使用IAM users/roles來控管其存取。為了讓我們在EC2中的producer/consumer application運作順利,我們需要其EC2有相對應的IAM roles。這樣的好處是每次要access kinesis時,EC2 get到的就會是暫時性的credentials,這就加強了安全性。
Kinesis的資料保護
Kinesis API只接受透過SSL加密的方式連線。Kinesis會使用多個AZ來達到HA與 data durability的目的。
在 Kinesis 中,data records包含一個sequence number、一個partition key和一個data blob,這是一個不間斷的、不可變的sequence of bytes。 Kinesis service不會以任何方式檢查、翻譯或更改 blob 中的資料。 data records在添加到 Kinesis stream後的 24 小時內還是可以被存取的,然後會被自動丟棄。
AWS Kinesis 的最佳實踐
Kinesis的 security model通常是 policy-based access並且透過IAM policy對其限制操作。以下是一些建議
- 對admin actions建立一個 IAM entity。例如:CreateStream, DeleteStream, AddTagToStream與ReomveTagsFromStream。
- 對一個stream的re-sharding建立一個IAM entity。例如,MergeShard, SplitShard.
- 對一個具有write的producer建立IAM entity。如,DescribeStream, PutRecord, PutRecords.
- 使用暫時性的security credentials(IAM roles)來取代long-tem的 access keys
- 如果加密是立即性的需求,哪麼在傳送到Kinesis前用client-side的方式加密
- 允許producer/consumers基於他們會用到的user agent和source IP
- 對所有AWS的API呼叫強制使用 aws:SecureTransport condition key
AWS QuickSight Security
QuickSight的存取管理
這裡的security feature會分為 Standard 與Enterprise版本。Enterprise版本可以我們既有的使用SAML的 Active Directory做整合驗證。若我們要將QuickSight dashboard崁入到我們的Application中,我們可以使用AWS IAM來強化其安全性。
下表為QuickSight standard 與enterprise版本的比較

QuickSight的資料保護
QuickSight提供以下的加密保護
- Encryption at rest(Enterprise 版本才有)
- Encryption in transit
- Key management
Encryption at rest(Enterprise 版本才有)
QuickSight會使用AWS-managed keys的方式來對以下表列的 data與metadata進行block-level的加密:
- All user data(usernames, email address, passwords)
- Data source connection data
- uploaded file names, data source names, dataset names
- Statistics that power ML insights
如果是standard版本,資料放在SPICE是沒有加密的。
Encryption in Motion
所有從SPICE進出來資料都會使用SSL來加密。但是對於某些DB,我們可以選擇是否需要加密傳輸。而從Internet來的連線則一定是SSL加密。
Key Management
所有的key都是由AWS來管控的。DB server的憑證(certificates)AWS則沒有管理。
Logging and Monitoring
QuickSight一樣整合 AWS CloudTrial紀錄logs。但目前CloudWatch則還沒有整合。
Security的最佳實踐
以下為QuickSight的資訊安全的最佳實踐
- 使用 HTTPS或WebSockets secure(wss://)來存取
- 如果data source是在AWS之外,我們要用 使用QuickSight的IP來允取存取。
- 永遠都使用SSL來連接DB
- 盡可能的使用enterprise 版本來強化security featire
- (只有Enterprise 版本才有)盡可能使用 VPC connectivity來保護我們與 AWS data souirce的通訊。 使用 DirectConnect 連接到我們的地端機房。
AWS DynamoDB Security
DynamoDB的存取管理
我們使用IAM來授予對DynamoDB resource與 API的操作。我們一樣要先編寫該IAM policy將後將該Policy attach到IAM users, groups或roles。而在DYnamoDB也可以使用FGAC的方式來管理DB level的access control,一樣是可以對其 items(rows)與attributes(columns)來控管。
若是我們的DynamoDB要對外部大量的使用者開放,我們就需要用到 web identity federation方式來驗證與授權。這種方式可以取代create一堆 IAM users,而是用 AWS STS(Security Token Service)來獲取暫時性的security credentials。
FGAC(Fine-Grained Access Control)
在這個機制下我們可以對DB內tables與indexes的某一個Item與 attributes進行能做哪些操作的管控。在這裡我們一樣使用IAM Policy的方式,然後將Policy apply到 IAM users, groups,或roles。
以下為FGAC可能會使用到的狀況
- 一個Application,根據user的位置顯示附近機場的航班資料。 航空公司名稱、到達和離開時間、班機編號都會顯示; 但是,機長姓名或乘客數量等屬性會受到限制。
- 一個用於遊戲的社交網路應用程序,其中所有users保存的遊戲資料都存儲在一個tables中,但沒有user可以acess不屬於他們的data items。
IAM Policy與 FGAC
讓我們舉例一個mobile game app,它讓玩家可以選擇並玩各種不同的遊戲。 該app使用名為 GameScores 的 DynamoDB table來追蹤最高分數和其他用戶資料。 table中的每個item都由user ID 和user玩的遊戲名稱唯一標識。 GameScores table有一個由partition key(UserId) 和sort key(GameTitle) 組成的primary key。 用戶只能access與自己 user ID 相關的遊戲資料。 想要玩遊戲的用戶必須屬於名為 GameRole 的 IAM roles,這個roles attach了security policy。
除了為 GameScores tables(Resource element)上的特定 DynamoDB 操作(Action element)授予權限之外,Condition elements還使用以下特定於 DynamoDB 的condition keys來限制權限,如下所示:
- dynamodb:LeadingKeys: 這個condition key允許user只能夠access partition key/value與其user ID 匹配的item。
- dynamodb:Attributes: 這個condition key限制對特定attributes的access,只有permission policy中list出的操作(actions)才能return這些attributes的value。 此外,StringEqualsIfExists clause確保app必須始終提供要操作的特定attributes list,並且app不能request所有的attrubites。
使用IAM policy時,要全部符合policy中所描述的。如果全都符合就會allow,只要其中一個condition不符就會直接deny。
如果使用 dynamodb:Attributes,則必須為table和policy中列出的任何secondary indexes 指定所有primary key和index key attributes的名稱。 否則,DynamoDB 無法使用這些key attributes來執行request的操作。
Identity Federation
目前DynamoDB支援的 web identity federation有如下三種,
- Login with Amazon
下圖為 web identity federation的流程架構

上圖中app會先呼叫第三方的identity provider做驗證,然後identity provider會return一個 web identity token給app。第二步app會呼叫 AWS STS並將其剛剛拿到的 web identity token給STS. STS會給予app一個暫時性的 access credential 的授權。app就會得到這個暫時性 access credential相對應的IAM roles並能對在roles中已經定義好的AWS resource進行操作,在這案例中是對DynamoDB進行操作。
如何Access DynamoDB
DynamoDB是一個使用http/https的web service傳送的是 JSON(序列化格式)訊息。主要有以下三種方式access
- DynamoDB API
- AWS SDK
- Management console
我們的Application大都使用API或AWS SDK來access。AWS建議使用SDK方式。因為SDK的librarie已經有寫好對request的authentication, serialization ,還有connection的管理。而SDK也提供Java與 .NET APIs.
DynamoDB的資料保護
DynamoDB對data at rest 與 data in transit都有加密保後,我們可以使用 DynamoDB SSL-encrypted endpoints。可以從 Internet 和 EC2 instance內部access 加密的endpoint。
此外,DynamoDB 要求對服務的每個request都包含有效的 HMAC-SHA256 簽章,否則request將被reject。 AWS SDK會自動簽署我們的request;但是,如果你想編寫自己的request,則必須在向 DynamoDB 的request header中提供簽章。要運算出簽章,我們必須從 AWS STS請求臨時安全憑證。使用臨時安全憑證簽署我們對 DynamoDB 的request。
Data at rest的保護,我們可以將資料上傳到 DynamoDB 之前對其進行加密。 這種client端加密還可以在傳輸過程中保護我們的資料。我們可以使用 SDK libraries加密與簽署我們的 DynamoDB data。
DynamoDB point-in-time recovery(PITR) 提供 DynamoDB table data的自動備份。 PITR有助於保護我們的 DynamoDB table 免受意外寫入或刪除操作。 。 PITR操作不會影響效能或 API 延遲。
DynamoDB的Logging與Monitoring
DynamoDB是直接與CloudWatch與CloudTrail整合的,所以我們可以從CloudWatch看到效能監控的資料。CloudTrial則可以看到對DynamoDB的所有API calls.
