AWS的大數據分析-part 3資料處理與分析
本篇文章我們將介紹如何處理與分析儲存在AWS 裡的資料。資料處理最重要的階段是資料流水線(data pipeline)與分析流水線( analytics pipeline)。AWS提供各種的技術工具讓我們來處理資料,後面我們會介紹 Glue, EMR,Redshift,Athena。這些技術工具會應因不同的場景或資料處裡型態而有不同的使用方式。
整個資料處理與分析要解決的大都圍繞在一些因素上,像是資料的大小,結構,處理速度的需求,SLA要求與skill level。資料處理與分析是一連串的流程 — 資料的”辨識、清理、轉換”,資料架構,從而辨別出有用的資訊,下定論,並支持我們的決策。下面我們來介紹不同的分析需求型態。
分析需求的型態
以下為五種的分析需求的作業型態
Batch Workload
這通常是查詢大量的”cold” data,並且可能花幾分鐘到幾個小時來分析。像是我們都跑日報,周報,月報等報表作業都屬此類。batch worload通過處理相同的資料會有一些效益存在,主要是能夠對部分的資料或半結構化或非結構化資料集進行處理。batch job作業範例包含了像Hadoop MapReduce jobs,這就非常適合處理大量的結構化/半結構化/非結構化的資料。而Redshift能夠使用SQL語法進行大量資料的轉換。
Interactive Analysis
這是一種具週期的分析作業,意思是我們會對資料進行實驗,而實驗是靠假設,確認其假設,與調整實驗過程來達到我們需要的業務目標。這一類的interactive analysis包含了 特設式查詢(ad hoc querying)。這一類的使用技術工具像是AWS Athena 與Apache Presto。
Messaging
這是Application-to-Application之間的溝通,主要是高速低延遲的資料傳輸處理。資料的低延遲是這一類最重要的處理因素像是 IoT message的資料處裡。
Streaming Workloads
這是擷取資料序列和回應每個data record增量更新功能的作業。這一類不斷輸入的資料像是量測資料(例如天氣),監控資料,稽核logs,GPS位置追蹤等等。這一類的資料會因為持續不斷匯入資料的速度而變得很大,但最重要的是如何能夠及時不斷的接收這些資料(沒有遺失任何一筆資料)並盡可能的快速做出回應。這一類的處理需求場景,像是詐欺偵測或即時推薦系統。使用的AWS技術工具有 Kinesis Data Streams 與 Kinesis Data Analytics。
streaming workload通常需要支援以下需求或條件
- 需要對半結構化data streams中的內容進行近乎即時的回應
- 通常需要相對簡單的計算
- 能夠使用workflow的方式來移動資料
- 適合用在大規模並且較難預測資料量大小
- 需要streams(ingest)工具將單獨產生的records轉換為較少的sequential streams sets
- 支援sequential streams與容易處理
- 有簡單的大規模擴展機制
AWS Athena
Athena是一個interactive querying services,其分析的資料是放在S3上。所以Athenta是一個分析的服務,本身並不儲存要分析的資料。它是serverless的。Athena支援 schema-on-read的概念,這個效用是在於現在我們的資料有越來越多是半結構化與多結構化的資料。它同時也支援ANSI SQL的功能語法,意思是這一個查詢語法可以被其他的分析工具所使用。Athena由於是serverless的所以如果query的資料量越大它的底層運算資源就會自行增長到所需要的處理量能。Athean也可以讓我們實行 cross-region queries。
Athena有著以下功能
- 可以用SQL語法直接Query在S3與其他資料來源(關聯式,非關聯式)的data。
- Serverless
- 高效能 — 採用平行處理的方式
- pay-as-you-go的付費模式,計費方式是每一次查詢的資料量(每種檔案格式都有不同的資料大小,athena有建議的檔案類型),有無壓縮與 partition data。
Athena背後所採用的技術: SQL query 是Apache Presto,DDL功能則是 Apache Hive。
Apache Presto
這是一種開源的分散式 SQL query engine,專門用於低延遲與特設(ad hoc)的資料分析。Presto的資料處理量能從幾TB到PB等級的資料量。Presto具有跨平台的資料查詢能力。
Apache Presto是一種主從式架構(類似Hadoop或一些 MPP的DB),下圖為Presto的架構圖
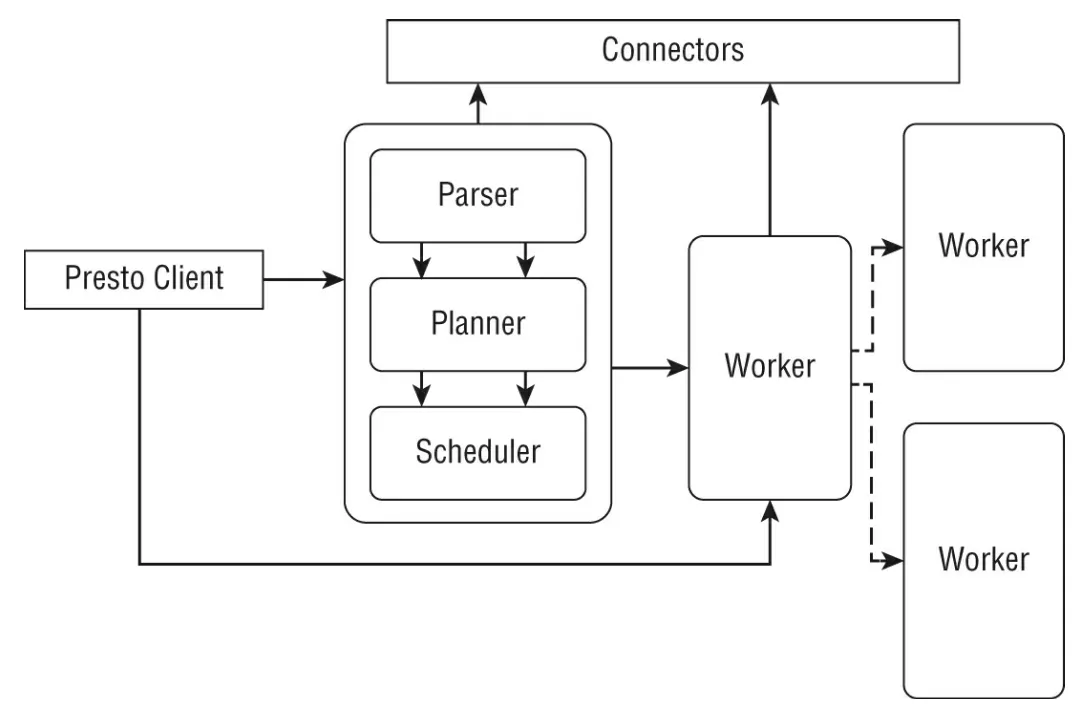
在上圖中的Presto架構中的主要元件有:
Coordinator:這使整個cluster的大腦部分。它會接收來自presto client的查詢要求。coordinator有三個資源子元件,分別是 Parser,Planner, Scheduler。
- Parser — 負責pasre從client來的query並且檢查有沒有語法上的錯誤
- Planner — 負責優化執行作業的計畫。Planner使用rule-based與cost-based的優化技術
- Scheduler — 追蹤worker node的活動與實際執行query
Worker:
負責在worker node上調度作業的組件。 worker node是 Presto 實際工作的主力。 它們能夠使用connector連接到data source。 coordinator負責從worker node獲取結果並將它們返回給client。
Connector:
Presto提供多種的連結器可以讓我們連接到不同的data source,內建的連結器有 Hive, Kafka, MySQL, MongoDB, Redsshift, Elasticsearch, SQL server, Redis與 cassandra。當然我們也可以客製化自己未被內建的其他data source連結器。
Presto能夠執行如此大量與快速資料查詢的原因在於它除了MPP DB有的功能外,還使用了 flat-memory結構來最小化 garbage collection。另外若我們使用 檔案格式為Parquest/ORC(Columnar format)則能得到更快速資料查詢(比起其他資料格式)。
當然我們可以自建Apache presto,不過若是我們沒有人也想用計次付費的方式來使用Apache presto,選擇serverless的Athena則是一種好的選擇。
Apache Hive
這一是要用在運行在Apache Hadoop的Data warehousing的功能。會產生這個功能是因為Hadoop主要是使用MapReduce來處理資料的,但這需要很好的Java技能與把資料處理問題轉成是 key/value pairs的想法。這對習慣使用SQL語法來處理資料的人產生的一些挑戰。於是Hive 應運而生,它將SQL語法轉化為MapReduce的框架來處理資料。
Hive支援的資料型態從簡單的integers, floating-point numbers, string, date, time, binary到 structs, maps(key/value tuples)與 arrays(indexable list)。支援的檔案格式有Apache的 Parquet 與 Apache ORC。
Athena 的使用場景
Athena適合用來分析logs,從web servers到Application logs都可以,它能夠對資料進行探索以此來了解資料與發掘資料的模式,之後可以用AWS QuickSight或其他BI tools對其進行ad hoc analysis。又或者在資料進入Redshift(data warehousing)之前query stage data。
在這裡要提一下Athena與AWS EMR的使用(後面會詳細講解EMR)對資料處理與分析的分別。AWS EMR提供不只SQL語法的處理(Anthena只有SQL語法),它還提供的其他的framework,像是Jive, Pig, Presto, Spark, Hbase與Hadoop。EMR適合用在我們要自行開發 Java/Python/Scala code在上面運行,意思是我們會比Athena (serverless)得到更多的控制權。
Athena的主要使用場景如下:
- 直接query在S3裡的資料(S3當作我們的data lake)
- 能夠分析infrastructure/operation/applications的logs
- 使用BI tools做interactive analytics
- 資料科學家可以拿來做 data exploration
直到 2019 年 11 月,AWS Athena 僅限於使用managed data catalog來存儲有關 S3 中可用資料的DB和schema的資訊,並且在提供 AWS Glue 的region,我們實際上可以使用 AWS Glue catalog,這通常是使用 AWS Glue crawlers程序製作的。在非 AWS Glue regions, Athena 使用internal data catalog,這是一個符合 hive-metastore 的存儲。 Athena 的internal data catalog存儲tables和columns的所有metadata,具有HA功能,並且不需要我們來管理。這個catalog符合 hive-metastore,因此我們可以對 DDL 使用 hive 查詢。
2019 年 11 月,在 AWS re:Invent 之前,AWS推出了對自定義metadata存儲的支援,這意味著我們可以使用data source connector 將Athena 連接到任何選擇的metastore。Athena 現在可以跨 Hive Metastore、Glue catalog或任何其他federated data source掃描資料的查詢。
Athena的DDL, DML與DCL
Athena針對DDL(data definitional language)使用了Apache Hive。 我們要在Anthena中create table有以下幾種方式
- 在Athena console執行 DDL statement
- 從JDBC/ODBC driver執行DDL statement
- 使用Athena的table wizard
我們之前提到Athena採用的是 schema-on-read的概念來產生schema,這樣就消除了load data或data transformation的需求。Athena不會修改我們在S3任何的資料。當我們create table時,我們同時也指向了資料實際的所在地。
以下為一個create table的範例

Athena透過SerDes(Serializer/Deserializer 是 Apache Hive 用於input和out以及轉換不同資料格式的interface)支援 JSON, TXT, CSV, Parquet與 ROC的資料格式。這種方式一樣用於來自S3的資料。
剛剛有提到Athena處理columnar 格式的資料(Apache Parquet與ORC)能取得極好的處理效能。這是因為資料的處理從row變成column,這種方式會減少需要處理資料的大小並且加強整體IO與CPU的需求。下表為同樣的資料內容以不同的資料格式儲存在S3所要花費的代價

對資料Partition
partition主要是對我們的資料做分區,這樣可以減少我們在實行查詢時scan到我們所不需要的資料量。partition用的是tables中的column,而且基於時間定義多級partition是很常見的。下表為一個比較表,比較有partition跟沒有的效能與代價。一樣的資料量大小一樣的SQL語法。

Athena Workgroup
我們有提到Anthena是以scan在S3的資料量來計費的,所以我們可以用Anthena來分隔不同群組或團隊的使用量。並且可以設定query資料量的上限。每一個workgroup可以有它自己的query history/ Data limits/ IAM policies/encryption setting。
Athena worgroups可提供以下的量測指標紀錄,像是
- 每一個workgroup的資料scan總量(total bytes)
- 每一個workgroup的query的總成功/失敗次數
- 每一個workgroup的query執行的總時間
我們也可以訂義每個query的threshold,超過的話就會被取消該次Query。
Athena Federated Query
我們可以使用federated query這個功能去query資料在其他關聯式/非關聯式/object或其他自訂義的資料所在位置。這個可以讓我們的query engine與實際資料 是分開的。下圖為Athena的各種data source。
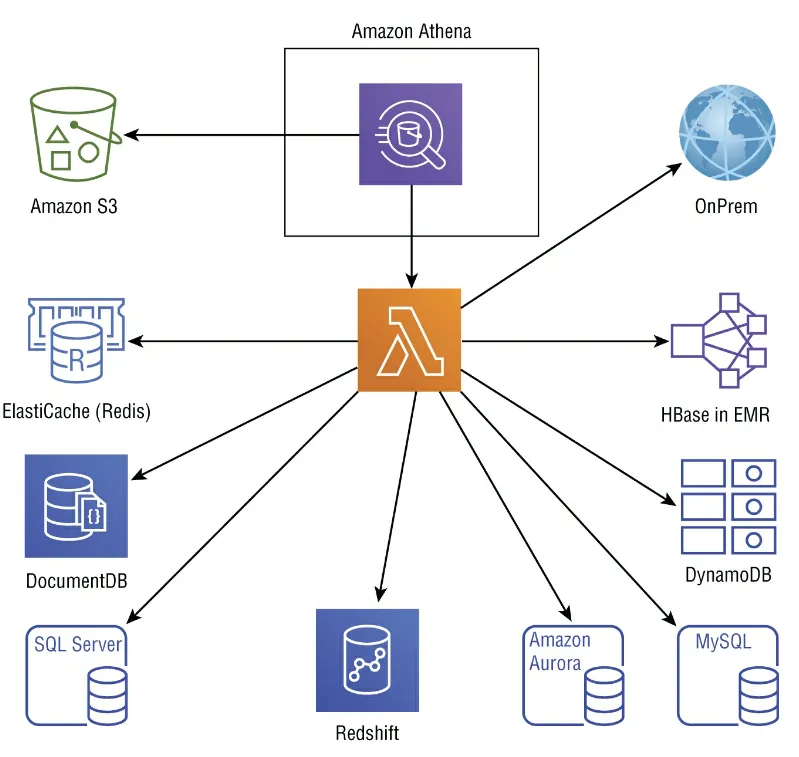
使用方式很簡單,我們只要deploy data source connector,註冊 connector,輸入 catalog名稱就可以寫SQL query去access data。
Athena 客製化 UDFs
我們可以建立客製化 user-defined functions(UDF)功能(就是一段處理資料的scripts)。這個功能主要是在資料的預處理或事後處理的功能,還有access control與在data access時訂出一些邏輯規則。我們在Athean query的select or filter 階段時可以加上我們訂出的UDF。UDF的主要功能有:
- 使用Lambda來執行UDF功能
- 支援 network calls
- UDF invocation可用於query的select and(or) filter階段
- Athean會優化效能,所以我們只要專心我們的scripts的業務邏輯
AWS EMR(Elastic MapReduce)
AWS在雲端上提供的一個大規模分佈式工作負載。使用的是開源專案像是Apache Hadoop、Apache Spark、Apache Hive、Apache Presto、Apache Pig等。
Apache Hadoop概觀
Apache Hadoop 是 Apache上的一個開源專案,它允許使用簡單的編程模型跨電腦集群分佈式地處理大型資料集。 它的設計考慮了線性可擴展性、高可用性和容錯性。 Apache Hadoop 是最受歡迎的開源項目之一,也是 AWS EMR 的關鍵部分。
Apache Hadoop包含了以下一些重要模組
Hadoop Common 這些是 Apache Hadoop 專案中支持其他 Hadoop 模組的common utilities。
Hadoop Distributed File system(HDFS) 這是Haddop的檔案系統,提供high throughput的資料存取並且會自動複製三份資料在cluster 的電腦群中。
Hadoop MapReduce Hadoop 最根本的預設資料處理框架,之後再發展出兩部分 YARN(resource handling)與MapReduce(processing)
YARN(Yet Another Resource Negotiator) 這是一個在 Hadoop cluster中調度(schedule)作業和管理資源的框架
Apache Hadoop 現今成為一種流行的資料處理框架,有望取代傳統的大規模資料處理系統,這些系統不僅效率低下,而且成本高昂。雖然該技術在規模和效能方面承諾了很多,但它的可用性還有很多不足之處。希望替換其傳統內部資料處理系統的一般企業正在運行許多不同的workload,並且通過 MapReduce 在 Hadoop 上對其進行改造似乎非常具有挑戰性。
例如,傳統資料處理系統最常見的使用者是更熟悉 SQL語法 的資料分析人員,用 Java 編程語言編寫 MapReduce 不是他們的專長或強項。這就產生了 Apache Hive 和 Apache Pig 等專案。除此之外,資料科學家希望使用這個可擴展的平台進行機器學習,但在這個平台上開發、訓練和部署模型變得有困難性,這又產生 Apache Mahout 和 Spark ML 等專案。
由於有如此多的開源專案,整個Hadoop環境變得很雜,並且由於每個專案團隊都在各自的發布週期內獨立工作,因此部署 Hadoop 平台變得有困難性。這為 Hortonworks、Cloudera、MapR 等公司以及 Teradata、IBM 等data warehosuing廠商提供了推出 Hadoop 商業版的機會,這些商業版將打包最常見的專案並添加額外的管理平台以進行部署、保護和管理各種專案的生態系統。
Hadoop 的初衷是以可擴展的方式處理大型資料集。 但是,在地端環境中部署平台,在這種環境中,可擴展性是一個挑戰,添加和刪除硬體可能會出現問題; 而公有雲是部署 Hadoop 平台的最佳場所。 在像 AWS 這樣的公有雲中,我們可以擴展到任意數量的資源,在幾分鐘內啟動/關閉cluster,並根據資源的實際使用情況付費。
雖然我們可以在地端環境來 運作任何Hadoop的商業版,但AWS提供了 EMR(Elastic MapReduce)作為雲端的託管 Hadoop ,主要是讓我們在更輕鬆地在 AWS平台上部署、管理和擴展 Hadoop。 EMR 的首要目標是將Hadoop 商業版的集成和測試嚴格性與雲端的規模、簡單性和成本效益相結合。
AWS EMR概觀
這是由AWS提供的託管式 Hadoop與 Spark環境,能夠讓我們在幾分鐘內把整個Hadoop的環境架起來。
使用EMR可以讓我們用到最新版的Hadoop並且經過AWS測試過的企業等級的hadoop架構。EMR可以根據我們要分析資料的大小自動的擴展Hadoop and Spark cluster並且在工作完成後縮回到我們想要的機器數量來幫我們節省不必要的花費。
若我們將S3當作我們的資料湖(Data lake)我們就可以將原始資料與分析完的資料存在這裡,不會因為cluster的node的動態增減而損失資料。CloudWatch可以幫我們收集追蹤量化指標,設定告警。EMR也提供多種安全保護,包含用VPC提供網路層保護,使用KMS將分析完的資料在S3中加密。甚至可以使用AWS Macie機器學習模型來偵測,分類,保護EMR裡的資料。存取控制可以用IAM而驗證則能使用Kerberos。
如果我們要長期使用EMR,哪我們可以購買EC2的RI節省我們的費用。如果是中度使用者則可以用RI + Spot instance來處理我們的資料分析工作。
Apache Hadoop on AWS EMR
接下來介紹Hadoop的架構,與使用場景,還有在Hadoop專案裡的整個生態系,像是Hive, Tez, Pig,與 Mahout 以及對Apache SPark的需求。
Hadoop是一種主從式(master-slave)架構, master node稱為name nodes而slave nodes稱為data node。這種架構源自於MPP(massively parallel processing)-一種大規模的資料處理。MPP架構的主要目標就是將 storage與compute在一群的電腦(data node)中把它分開,而由單一的master node(name node)來管控這些作業。
name node(master node)負責管理namespace,例如整個filesystem metadata,以及node的位置和特定file的block位置。 該資訊是在系統啟動時從data node重建的。 由於name node的重要性,考慮到它具有file和block的location map,使其對故障具有韌性是很重要的。 這通常通過備份filesystem metadata或運行secondary name node process(通常在單獨的機器上)來實現。 但是,secondary name node在發生故障時不提供高可用性。 我們需要通過啟動一個新的name node來recovery 掛掉的name node,並使用metadata 副本來重建name node,這個過程可能需要 30 分鐘到 1 小時。
Data node是cluster中的實際worker,它們存取實際資料並與name node通訊以在name node level下保持namespace是最新的。
主要的元件如下
Hadoop MapReduce Hadoop(HDFS) 稍早有提到過了。不過 HDFS本身不是設計來進行低延遲的資料存取,如果需要的話應該是用Hbase。HDFS的設計是用使用一般商用硬碟來提供資料的High throughput。下圖顯示了client端讀取和client端寫入的 HDFS 架構和剖析。
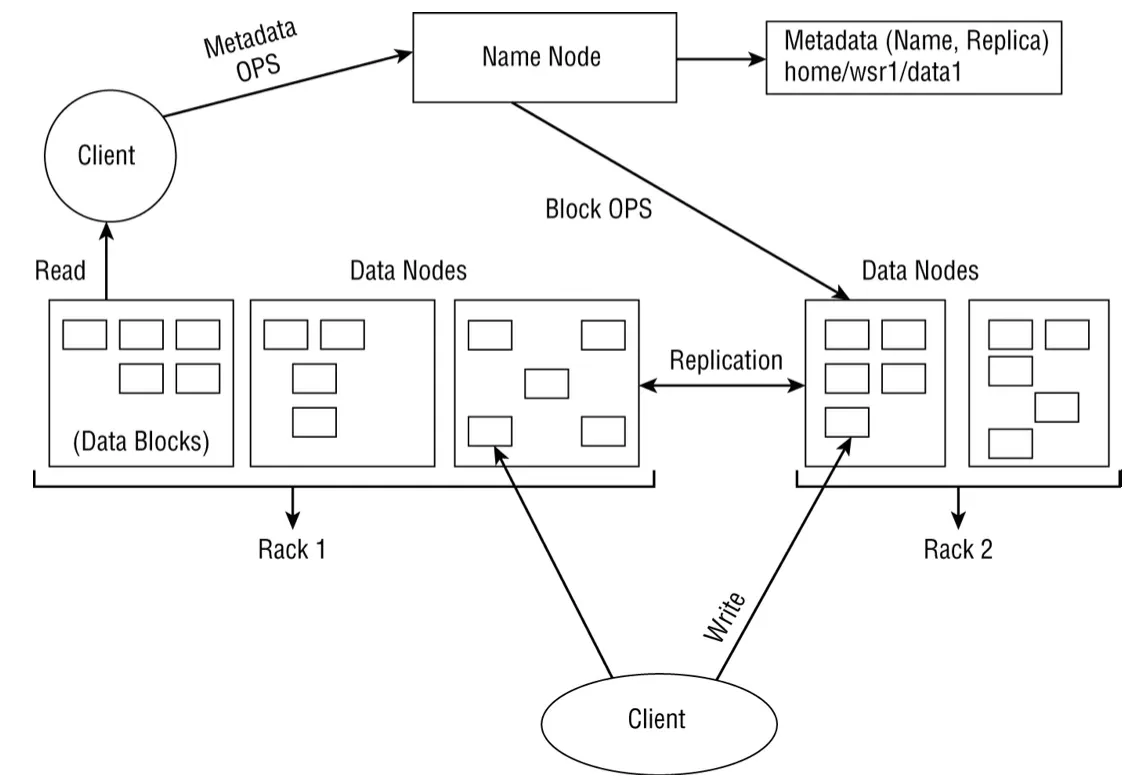
上圖中 filesystem 的metadata是運行在name node的memory中,意思是如果我們的資料都是些小檔案的話對Hadoop就會是一個問題。因為這樣會讓name node用完它的memory,其結果就是整個cluster掛掉,因為filesystem的metadata都不見了(存了太多小檔案的metadata)。HDFS對其要放上filesystem的檔案大小有其建議。
由於 IO 是導致latency的最重要因素之一,典型的filesystem處理data block以優化disk reads/write。 block大小是可以讀取或寫入的最小資料量,雖然disk的block大小為 512 bytes,但大多數filesystem將處理幾個KB的block大小。 HDFS 也使用block size,但default block大小為 128 MB。 HDFS使用大的block的原因是它旨在處理大量資料,因此我們需要最小化搜巡成本並通過每一次的 IO 獲取更多資料。而且每個Block都會被複製成三份(這可以手動更改)散落在不同的data node中。
MapReduce MapReduce 是 Hadoop 2.0 之前在 Hadoop 上進行資料處理實際上的編程模型,當時它衍生出 Apache YARN。 MapReduce job基本上是一個問題的解決方案,例如,資料轉換作業或應用程序想要在cluster上執行的一些基本分析(通常對存儲在 HDFS 或任何其他shared storage)在 MapReduce 編程模型中。 Map Reduce job分為兩個主要任務:Map 和 Reduce。這些任務由 YARN 橫跨cluster上的node調度,YARN 不僅調度任務,而且與 Application Master 一起作業以重新調度跨cluster的失敗作業.
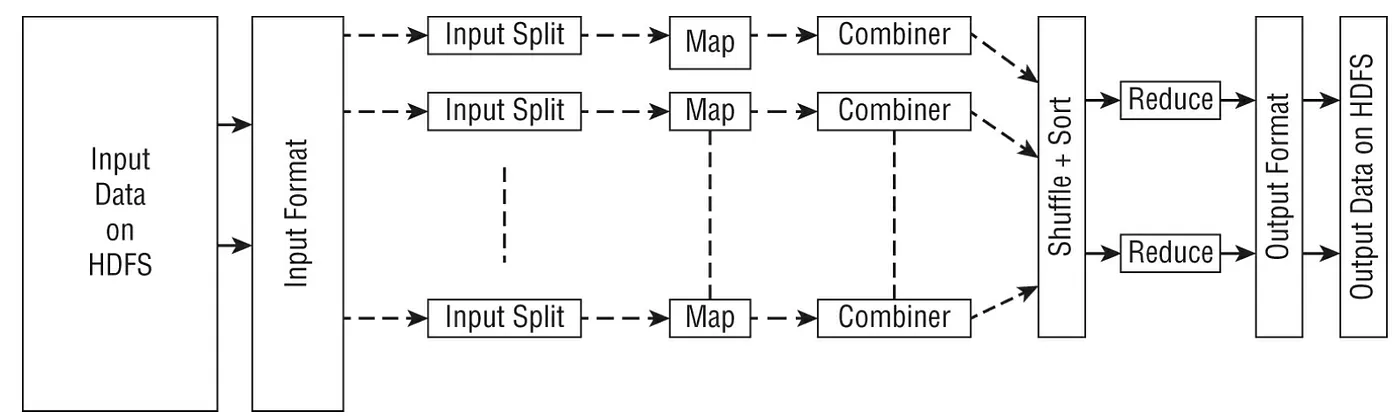
Mapper將output寫入local disk而不是 HDFS,因為output是中繼的,然後由 reducer 階段收取以進行最終output。 作業完成後,mapper的output將被丟棄。 一般而言,reduce 作業從多個mapper 任務接收資料,並將output存儲到HDFS 進行持久化。 mapper作業的數量取決於拆分的數量(輸入拆分由 Hadoop 定義),而 reduce作業的數量是獨立定義的,不直接取決於輸入的大小。 選擇reducer的數量被認為是一門藝術而不是一門科學,因為reducer太少會影響整體並行度,從而減慢工作速度,而reducer太多可能會創建很多較小的file和大量的inter mapper-reducer traffic(the shuffle/sort)。
下圖描述了 MapReduce job的解析結構以及所涉及的主要步驟,例如將輸入資料轉換為拆分、運行mapper階段、使用combiner、shuffle和sort,然後再進行reduce階段以建立要存儲在 HDFS 上的output data。
YARN(Yet Another Resource Negotiator) 如同它的名字一樣,這是在Hadoop 平台與Cluster resource內進行的一種資源管理。在 MapReduce 1.0時它是在computing framework內的,後來2.0後獨立出來。主要目標是把資源管理與compute engines(像是Apache Tez, Apache Spark)兩種作業分開來。
下圖為將兩種作業分隔開後這些上層的Application 可以直接使用下層的Frameworks而不需要與YARN整合在一起。

YARN有兩種常駐的daemons:
- Resource manager daemon — 這是運行在每個cluster中,負責整個cluster內的資源管理。
- node manager daemon — 這是運行在所有cluster內的node,主要是在node中啟用/監控 containers. 所謂containers就是從cluster中挖一塊resource(cpu/memory等等)。
YARN服務運作有著以下步驟
- client會連接 resource management daemon要求run一個 Application Master
- resource manager會檢視整個cluster內的可用資源並通知node manager在container發起Application master
- Application master會根據啟用的目的會有兩種不同步驟
- 在Container內運行Application,計算結果,並將其發送client 端。
- Request(如 MapReduce YARN application)額外的containers並以分佈式的方式運行Application
YARN啟用的Application可以運行的時間可以是短暫或是長期的運行在Cluster中。
Hadoop on EMR
EMR底層的機器就是EC2(一群EC2)。並依安裝的不同的軟體元件而有著不同的角色。Apache Hadoop中只有name node 與 data node,但EMR有著以下三種不同的role type:
- Master nodes: 這跟name node的功能其實差不多,也是將資料與作業分佈到整個cluster的其他角色的node中。這裡面還會運行 YARN來管理整個資源,就像 HDFS NameNode service。
- Core nodes: 這與 data node的功能差不多,實際的作業執行者並將運算資料儲存到 HDFS中。假如我們是 multi-node cluster, core nodes的角色就是必要的。core nodes還運行 Task Tracker daemons與執行平行運算的作業。
- Task nodes: 這個與core nodes最大的不同點是,它們不儲存資料在HDFS中。只是純粹的運算單元(這類似 Hadoop MapReduce 與Spark executors)。task nodes不會運行DataNode daemon。AWS建議運行task node要用EC2的spot instance。除了一些特別的原因(如Application Masters porcess要run在core node),不然所有的分散式運算都會在Task nodes中執行。
EMR cluster的型態
EMR是將 storage與compute去耦合,意思是我們可以根據不同的工作負載運行在適合的cluster中,達到好的成本效益與要求的SLA。
- Persistent clusters: 這就像我們在地端機房建立的hadoop cluster一樣,建起來了就不會拆掉。
- Transient clusters: 這種是適合跑batch job,像跑週報/月報一樣。跑完了就不再需要cluster存在了。因為我們只需要定期跑出結果,並且能儲存。這就是將compute and storage分離的好處。
- Workload-specific clusters: 由於有各種版本的 Hadoop,我們可以針對特定工作負載優化cluster。 運行特定於工作負載的 EMR cluster可為我們提供最佳性能,同時提供最佳成本。
哪我們怎麼根據我們的需求來選擇運行EMR時所需要的EC2 type呢?通常我們有五種使用場景的分類,如下表

建立EMR Cluster
我們有三種方式可以建立EMR cluster,分別是 AWS的management console/ AWS CLI/ AWS Java SDK。
Management console可以參閱這一個Vidoe。而CLI的方式可以參考以下的範例

而以AWS SDK的方式可以參考AWS的文件庫。以程式化的方式有助於我們在建立data pipeline中要create EMR cluster運行batch job。
當我們使用management console來建立cluster時我們會看到很多選項,像是 EMR MultiMaster 與 Glue Data Catalog。以下我們來看一下有哪些選項
- EMR MultiMaster — 我們在Hadoop 的章節提到過master nodes會有單點故障的問題。在這裡EMR提供了我們master node具有自動化的HA(3個master nodes)功能。
- Glue Data Catalog setting — 這個服務其實可以當作是一個central catalog。我們可以使用這個服務來作為EMT的external metastore,它可以將這一類的資料分享給Hive,Spark與Presto。
- Adding steps — 是可以提交到cluster的工作單元,它可以是 streamming program/Hive program / Pig program/ Spark application / Custom JAR
- Instance group configuration:在建立cluster時關於選擇 EC2 instance type我們可以從AWS的EC2 清單中挑選或是從sport market中來選。如果是預設選項” Uniform instance groups”我們是針對每一種node type一個一個來選(選擇標準如同我們上面所提的5種使用場景分類)。但如果不想這麼麻煩只想要根據我們的目標(資料處理量能),就可以選 “Instance fleets”,EMR就會根據我們的需求針對每種node type自行選擇符合我們的要求。
- Logging — 這會將EMR的log存放在 /mnt/var/log之中,會記錄的log類型有 Step logs/ Hadoop and YARN component logs/ Bootstrap action logs/ Instance state logs。如果我們啟用這個選項,logs會每五分鐘寫到S3中。
EMRFS
這其實跟Hadoop HDFS是一樣的,但EMRFS還可以直接從S3中read/write資料。主要是我們的EMR cluster是暫時性的跑完需要跑的作業後要有一個資料存放以免cluster被拆掉後資料會消失。
我們在介紹S3時有提到,S3的資料特性是eventually consistent。EMRFS提供的consistent view是lists與 read-after-write的object,而且EMRFS需要知道目前資料在S3的資料一致性的狀態是甚麼。所以ERMFS使用的DynamoDB來記錄目前資料的一致性狀態,而我們可以選擇紀錄的選項有 — (1)在找到不一致狀態後EMRFS呼叫S3的次數,(2)在第一次的retry後之後再retry的次數。Subsequent retry將會使用 exponential back-off的方式。
Bootstrap Actions 與 可製化的AMI
Bootstrap Actions這是在create cluster的過程中我們需要cluster的 hadoop daemons在所有的node ready之前跑的一些scripts。通常都是一些額外的軟體安裝或設定。EMR允許最多16個Bootstrap actions。我們還可以根據一些條件來觸發這些bootstrap actions,例如
- RunIf — 這是一個預定義的bootstrap actions, 當有任何的 instance-specific value在 instabce.json / job-flow.json 檔案中被發現時。例如條件是 Master=true,意思是當這個node是master node時會觸發scripts。
- Custom — 自訂義的scripts,例如從S3 copy檔案
但如果嫌麻煩的話我們也可以預先都放在AMI中,等AMI開始跑時就會自行跑這些scripts or command。但有一些限制
- 必須是 AWS Linux AMI
- 最好是 HVM- or EBS-backed AMI
- 必須是 64-bit AMI
- 不得具有與 Hadoop Application使用的名稱相同的user name(如 hadoop,hdfs.yarn等)
EMR的資訊安全
我們可以使用 EC2 key pairs來 access到master node中。這我們在create cluster可以選擇要不要勾選(預設是有勾選)。如果沒有勾,哪麼只有這個cluster的創造者可以在console or CLI可以看到它。
EMR的權限
EMR需要三種不同的roles來運行整個platform:
- EMR role : 讓EMR可以存取資源(如EC2)
- EC2 instance profile: 讓cluster裡的EC2可以存取資源(如S3)
- Auto Scaling role : 允許可以執行EC2的 auto scaling out/in
這些role在creat cluster時如果是不存在的話EMR會create他們。
Security configurations
使用security configuration我們還可以設定資料加密,Kerberos驗證,與 S3對EMRFS的授權。同一個 security configuration可以套用在不同的cluster。security configuration可以透過management console / AWS CLI/ AWD SDK/ cloud formation來create。
Apache Hive/Pig on EMR
Apache Hive是一個運行在Hadoop的開源的SQL-like data warehousing。雖然我們之前講到使用Hive解決方案有助於資料分析人員應用Hadoop這種平台。不過它與MadReduce相比還是有一些優缺點,請參考下表

而Pig則是處理更複雜的資料處理場景,Pig具有multivalued 與 nested data structure的額外效益,像是一些data transformation(如join兩個datasets)。如果單純用MapReduce來處理就會變得很複雜,所以它是作為MapReduce的Higher level abstraction。
Apache Pig有兩個主要的元件:
- Pig Latin Language — 這是用來呈現一個資料流(data flow), 所謂資料流基本上就是針對資料進行一連串的convert/input/transformation的操作。
- Pig execution environment — 這是Pig scripts運作的環境。run scripts有兩個選擇,一個是run在 本地的JVM,另一個則是運作在分佈式的hadoop cluster中。
Apache Pig支援以下的Data type

還有較複雜的data type

以下為一個Pig scripts ,載入 student 資料並print他們的名字與年齡。

Apache Presto on EMR
我們之前提到過Athena是基於Presto所開發的。而Presto也能與Hadoop一起運作。主要是資料科學家用在需要快速的互動式分析。不過它也有一些優缺點,如下表

Apache Spark on EMR
前面提到的Hive與Pig都是為了提供High level language(如SQL)來進行資料分析處理,但其底層仍使用MapReduce框架。MapReduce本身的設計就是不是針對互動式分析(interactive analysis)而設計的,而為了在Hadoop/MapReduce這一框架實現此一目的才會有後來的Apache Tez/Impala/Spark等開源專案的出現。
Apache Spark正是為了互動式分析而設計的。與MapReduce最大的不同點在於Spark針對於一個分析作業,Spark將其放在memory上來運作而非像MapReduce是將同一個job分成不同task(也就是data block)到node的disk中。Spark會在實際運作job之前使用lazy evaluation來優化其作業,並且提供80個 High-level operators來讓Application(如Java/Scala/Python/R/SQL)更容易建立平行處理。
除了多個 API 之外,Apache Spark 還允許我們將框架組合到一個環境中。 例如,我們可以在一個program中完成 SQL processing、stream processing、機器學習和graph processing,這使得 Apache Spark 不僅功能強大,而且被業界廣泛採用。 下圖顯示了 Apache Spark 框架的不同元件。

Spark的架構
Saprk的主要元件有 — Driver program / Cluster manager / Worker nodes / Executors /Tasks。架構圖如下

Driver Program
這是Spark的大腦,主要是運作我們Application的主要功能,通常運行在一個node中。Driver會驅動spark application並維護program相關與重要的資訊。它三項主要責任
- 維護所有關於Program的資訊
- 回應user 的inputs
- 分析,分佈與調度所有cluster executors的作業
Cluster Manager
代表Application向cluster要求resource。Apache Spark支援以下幾種不同的cluster manager
- Standalone — Apache Spark 發行版支援一個簡單的cluster manager,它包含在 Spark 中,這使得設置cluster變得容易。
- Apache Mesos —一種 General Purpose cluster manager,允許在computer的cluster上運行的Application之間進行有效的資源共享。Apache Mesos也可以運行 Hadoop MapReduce applications。
- Hadoop YARN — 這是針對Hadoops cluster預設的cluster manager並支援Saprk的運作。
- Kubernetes
Worker Nodes
在一個cluster裡通常會有多個work nodes來run一個或多個executors,通常是執行由driver program分配下來的作業。
Executors
實際執行由Driver program的作業。每一個executors會執行由driver program分配下來的code並且回報執行狀態到driver node。executors 將會運作Spark code。
Tasks
tasks是code的實際單獨運作。 了解tasks是如何在cluster中建立和調度的,這一點很重要。 Spark 將首先創建我們的執行圖(例如 RDD 圖),然後創建execution plan。 如果我們查看driver program的basic word count,我們會看到多個stage,針對這些stage創建多個task並橫跨worker nodes調度。 通常,tasks是根據資料的分佈方式創建的。
Spark Programming Model
Spark是一種master-slave架構。但Spark有一個重要的概念稱作Resilient Distributed Datasets (RDDs),它基本上是跨 Spark cluster nodes分佈和暫存在記憶體中的資料的pointer/abstraction。RDDs有兩個主要特徵:
- Resilient — RDD 是分佈在cluster中的資料的abstraction,本質上是具有彈性的,意味著它提供了一個容錯分佈,並且可以在發生故障時重建。
- Distributed — 代表資料分佈在整個cluster中。
RDD有兩種建立方式
- 在我們的driver program來平行化(parallelize)既有的collection
- 參考外部的sotrage system(如S3,HDFS,Hbase)的dataset
RDD支援兩種主要運作
- Transformations —
從既有的dataset來建立一個新的dataset,如map, flatmap(), filter(), sample(), union(), disinct(), or groupByKey()。所有的transformation基本上都是layze的,意思當我們呼叫一個transformation作業Spark是不會立即執行作業的,而是等到一個action被呼叫到。 - Actions —
actions會觸發transformations並將datasets返回給driver program。transformation的範例如 reduce(), collect(), count(), take(), saveASTextFile(),saveAsObjectFile().
Shuffle in Spark
某些操作會觸發一種稱為shuffle的事件。shuffle是一種複雜且代價高昂的操作,因為它的動作包含了機器與executor之間的複製,通常是透過網路。這樣就會耗用 disk I/O, data serialization, netwotk I/O等資源。因此對於shuffle的操作我們需要特別注意。以下的一些操作會讓我們觸發shuffle:
- Repartition
- Coalesce()
- 所有 ByKey的操作,如 GroupByKey(), ReduceByKey()
- Cogroup()
- Join()
DataFrames 與 Datasets API in Spark
資料集(datasets)是分佈式資料集合,它提供 RDD 的效益以及 Spark SQL 優化execution engine的附加優勢。 Spark 2.0 將 DataFrame 和 Dataset API 合二為一。 Spark SQL 的entry point是 Spark 2.0 中的 SparkSession。 每個item都是 ROW type。例如 有一個DataFrame可以包含兩個 columns,分別是A與B,使用DataFrame看起來就會是 (ROW(A=26,B=40),ROW(A=43,B=13))。
DataFrame的做法是來自於Python與 R的DataFrame概念。但從效能的角度來看Spark的執行效能會比Python與R都要好。
Spark 使用 RDD API 作為基本資料結構。 所有運算都在作為 Spark 基本構建block的 RDD 中完成。 從 Spark 2.0 開始,資料集具有兩個不同的 API 特徵:
- A strongly typed API
- An untyped API
而由於Python與R沒有 compile-time type safety,所以我們在 R與Python中只能使用untyped APIs(DataFrame)。
RDD 提供強大的compile-time type safety(type safety是編譯語言防止跟type errors的程度)並提供object-iriented的操作。 RDD 可以使用high-level expressions,如 lambda functions(與 AWS Lambda 無關的匿名函數)和 map function。 由於garbage collection(object的creation和destructio)和序列化(serializing)單個object的大量overhead,RDD 的缺點在於其性能。
DataFrame API 提供了資料的關係和結構化視圖,讓Spark 管理架構並行在nodes之間傳遞資料,而無需使用 Java 序列化程序。 Spark DataFrame 使用 Catalyst optimizer來優化query execution plan和執行查詢。 Spark DataFrame 還使用 Tungsten execution backend,通過優化 Spark 作業的 CPU 和memory效率來改進 Spark execution。 Spark DataFrame 也可以對資料使用 SQL 表達式,例如 group、filter 和 join。 DataFrame API 的缺點是它不提供強大的compile-time type safety。 Dataset API 提供了 RDDs 和 DataFrames API 的優點。 它使用來自 RDD 的強大compile-time type safety、object-iriented的操作以及 Catalyst optimizer。
Spark SQL
這是一個針對結構化資料的處理。我們可以指定資料在memort或disk中處理並且使用metastroe(如Hive metastore)。在EMR中我們可以選擇使用像 Lake Formation catalog這樣的catalog。 Spark SQL 相容於Hive、Avro、Parquet、ORC、JSON、JDBC 等data source。 我們可以通過 JDBC 和 ODBC connector進行連接。
Spark Streaming
我們已經討論了ingesting streaminf data的重要性,Spark 提供了使用 Spark stream對live data stream進行可擴展、high-throughput和fault-tolerant stream processing的選項。 Spark 為包括 Kafka、Flume、Kinesis、Twitter 和 S3/HDFS 在內的許多data source提供內建support,然後允許我們使用 map、reduce、join 和windows operations等功能構建複雜的處理演算法。 處理完資料後,可以將其推送到各種filesystems、DB、儀表板或其他streaming applications。
Discretized Streams
Spark 流提供了一種稱為discretiozed stream(DStream) 的high-level abstraction,其中來自source的live data被分成小批量(mini-batches)。 一個 DStream 由一系列連續的 RDD 來呈現,這些 RDD 基本上包含來自某個間隔的資料。 下圖顯示了discretized streams和 RDD 之間的關係。

Sparking streaming讓我們在DStreams(如 map(), flatmap(), filter())運行不同的transformation。Sparking streaming提供兩種內建的streaming source:
- Basic sources : 可直接在 StreamingContext API 中使用。 例如包括file system和socket connections。
- Advanced sources : source可以有 Kafka, Flume, Kinesis
Sparking Streaming同時也提供 windowed compuation,這是一種在data的 sliding windows實行 transformation。基本的windows operations包含:
- windows(windowsLength, slideInterval)
- countByWindows(windowsLength, slideInterva)
- reduceByWindow(func, windowLength, slideInterval)
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
- reduceByKeyAndWindow
- countByValueAndWindow
Spark 機器學習(Spark MLLib)
這是Spark平台所提供的機器學習功能。Spark ML是一個 datafram-based API,並且也提供一些新功能如 Tungsten與 catalyst optimizer。
SparkML 是 Spark 的plug-in。 它提供了一個可擴展的分佈式機器學習演算法library — — 可通過 Spark 的 API access— — 用於在 Spark 和 Spark 的所有其他models(Spark SQL、Spark Streaming 和 GraphX)之上使用。 它以 Spark cluster的速度提供機器學習,與在 MapReduce 上運行的類似作業相比,可以節省時間。
MLLib提供的演算法有
- Classification: Logistic regression, decision tree classifier, random forest classifier, gradient boosting trees, linear support vector machine, Naïve
- Bayes Regression: Generalized linear regression (GLM), decision tree regression, random forest regression, gradient-boosted regression, survival regression, isotonic regression
- Collaborative filtering: Alternating least squares (ALS)
- Clustering: K-means, latent Dirichlet allocation (LDA), Gaussain mixture model (GMM)
- Decomposition: Singular value decomposition (SVD), principal component analysis
Hive on Spark
雖然 Spark SQL 是在 Spark 上運行 SQL 的標準,但許多組織一直在使用 Apache Hive 並在 HiveQL 中擁有他們的code base,但希望將scripts從 Hadoop migrate到 Spark 平台以獲得更好的效能。 Hive on Spark 為這些組織提供了在 Apache Spark 上運行 Hive programs的選項和清晰的migration path,而無需進行大量的維護和migration overhead。
哪我們在甚麼時機來使用Apache Spark呢?以下為使用Apache Spark的效益

而在EMR上運行Spark的效益又是甚麼呢?以下表格為其效益

Apache HBase on EMR
Hbase是一個分佈式的column-oriented的儲存方式,這是以HFDS為基礎的服務。會使用到HBase是因為我們需要對大量的資料能夠即時的 read/write random access,而這是 MapReduce 與Spark做不到的。
HBase是現今最受歡迎的NoSQL DB。但它不是可以立即使用SQL的方式來操作的,需要搭配 Apache Phoenix的開源專案才能運作SQL。HBase最有名的案例是Facebook拿來用在 messaging infrastructure。
HBase架構
Hbase也是一個master-slave架構,有著以下四個主要的元件
- Master
- Region server
- ZooKeeper cluster
- Storage(/HDFS/S3)
建立Hbase的選擇有 Quick options與 Advanced mode(如下圖)

在advanced mode中,除了可以選擇軟體的安裝我們還可以選擇storage layer來儲存我們的資料。我們可以選擇HDFS或S3(如下圖)

Apache Flink/ Mahout / MXNet
Apache MXNet是一種深度學習框架。它的一些關鍵功能如下
- Native distributed training supported: MXNet 支援在多個CPU/GPU上實行分佈式訓練。
- Flexible programming model: 支援 imperative 與 symbolice programming
- Multilingual: 支援多種開發語言,如 Python, R, Scala, Julia, C++, JavaScript
Apache Mahout是一個開源式的 ML library,library有一些我們經常用到的演算法,如 classification, dimensionality reduction, recommendation engines與clustering。
Apache Flink 是一種分佈式stream processing engine,主要是用在有邊界(definite start and end)與無邊界(definitive start but no end)的 “有狀態的運算” data stream。Flink是被設計運行 low latency 與 大量資料的運算。
Apache Flink有著以下特點:
- Event time and processing time semantics: 多數的 stream processing engines使用的是 processing time來處理streaming data。但是event time卻可以讓我們處理有序的資料,意思是當資料到達的順序並不是依來源端發送出來的順序,event time可以把它調整成是依發送出來的順序。但這麼做卻會延遲資料處理的速度。而Processing time卻沒有,因為它是先來先處理。
- Exactly-once semantic
- Low-latency/high-volime
- Wide connector ecosystem: 可以連結多種的 storage and processing system,如 Apache Kafka, Cassandra, Elasticsearch, Kinesis, HDFS, S3
- Varity of deployment options: 可以使用 YARN, Apache Mesos, Kubetnetes來部署
下圖為Apache Flink overview

到現在我們可以看到AWS EMR提供多種的選項來讓我們進行資料分析,但是這些工具要怎麼套用在適合它的場景呢?以下為一個參考表格

AWS Elasticsearch Service
維運分析屬於分析作業的一種,主要聚焦在組織維運的即時性。通常是經由組織的核心系統來產生log來進行立即的分析。而Elasticsearch就是用來處來這一類維運面的資料。AWS Elasticsearch 是一種託管式的服務。
何時會用到呢?
維運分析會包括資料(logs)的收集,辨識,分析來解決組織在Infrastructure 與Application的運作問題。
維運分析通常會是以下的運作場景:
- Applications monitoring: 包括儲存,分析,關聯Application與Infrastructure log之間的關係。能立即找出這些logs的相關性進而及時的解決問題。
- Root-cause analysis: 讓我們能綜觀IT infrastructure所有的功能元件(server/router/switches/VMs等)的問題,減少Infra面的 MTTD(mean time to detect)與MTTR(ema time to resolve)。
- SIEM : 及時的威脅偵測與事故管理
- Search: 提供強大的搜尋功能
組織通常都會依靠機器產生出來的資料(而非業務面產生的)來回答營運上的問題,像是 — 購買或未購買哪些產品? 哪些是最常用和最不常用的功能? 誰是我們系統上最活躍的用戶? 是否有用戶破壞系統? 登錄失敗的次數是否異常多?,而這些資料產生的量與速度遠超過我們業務面產生的,所以需要能更快速的分析這些資料並得到我們想要的答案。要分析這一類的資料有以下的挑戰:
- 資料的多樣性與異常大量的資料
- 需要的是即時的分析而非批量分析
- 要的是減少 operational overhead並聚焦在得到答案
- 還能搭配其他類型的資料(voice/image recognition/IoT)來強化這些Applications資料
而batch-based DW solution則無法符合以下的分析要求
- 已具成本效益的方式real-time ingest由機器產生的資料
- 能立即為這些抵達的資料做index並能夠立即被搜尋
- 能夠搜尋,關聯,分析,並視覺化資料並得到見解
在以上這些挑戰與要求下Elasticsearch應運而生,它是基於Apache Lucene而建立的,並基於以下原因讓它成為受歡迎的分析方案
- 是開源專案
- 提供簡單的資料 ingestion機制
- 與Kibana搭配提供動態的視覺化儀錶板
Elasticsearch 核心概念(ELK Stack)
ELK是由三種開源專案的名稱縮寫,分別是Elasticsearch, Logstash, Kibana。它們經常被統稱 Elasticsearch。
Elasticsearch是一種開源RESTful,分佈式的搜尋與分析引擎,並建立於Lucene之上。但它提供的又比Lucene的還要多:
- Elasticsearch 是一種分佈式 document store
- 支援多種語言並且是高效能的
- 每一個field在Elasticsearch都是有index並可以被搜尋的(Elasticsearch預設的)
- real-time data analytics options
- index的資料量可以從 TB到PB等級
Elasticsearch核心元件有:
- Node: single instace
- Cluster: 一群 nodes,且具又 indexing and search的能力
- Index: 是一個具有不同種類的document(還有屬性)的集合(collection)。使用shard可以增強index的效能。
- Document: JSON檔案中的field集合(collection)。每一個document都有屬於它們的型態並存放在index中,並且每一個document都會有它們的UID(unique identifier)。
- Shard: Index可以被切分到shard中來增加效能也能達到平行處理的目的。每一個shard其實就是一個 Lucene index的instace。
我們可以把上面介紹的術語與RDBMS來相比較,如下表

Logstash 是一個開源的 data ingest tool,可以讓我們從多樣的data source收集資料,transform,並到我們指定的地方。做Data pipeline tool,logstash有著以下特徵:
- 這是一個成熟且健全的解決方案,能處理大量的資料
- 可以從非常多種的data source ingest data,並且強化資料與關聯其他來源的資料
- 豐富的生態系,意思是有很多的plug-in可以用。當然也可以客製自己的
- highly available
Kibana是一種開源的資料視覺化工具,讓我們review logs與events。也提供互動式圖表,預先立好的 aggregation/ filter與 geospatial 支援。在整個ELK stack中,Kibana扮演以下的功能
- 用視覺化的方式進行探索性的資料分析
- 有多種類的圖表
- 可以使用機器學習來找出離群直與趨勢偵測
AWS Elastic Service從AWS的角度來說就是簡單使用用,便宜又大碗,高CP值又安全。下圖為AWS Elasticsearch 的作業模式

AWS Redshift
AWS的託管式,PB等級的data warehousing解決方案。Data warehousing(以下稱DW)的重點與RDBMS不一樣的地方是,RDBMS需要作資料正規化,而 DW則是非正規化。因為這樣資料就會有副本的狀況發生,但也加速資料分析的效能。
Redshift是AWS提供的DW服務有著一下的功能與效益:
- 快速:
因為它是 columnar storage, 資料壓縮,與zone maps等功能來減少因為query data產生的大量 disk I/O。Redshift也採用 MPP(massively parallel processing)架構來處理SQL的操作。 - 可擴充性:
Redshift底層的EC2 數量/類型可以容易的變更。 - 具成本效益:
(筆者意見,你用了才知道) - 簡單使用
- 容錯性:
因為是cluster所以資料會被複製在其他機器(node)上。而且我們也可以持續將上面的資料備到S3中 - 自動備份:
用快照(snapshot)自動持續將新資料備份到S3上(incremental backup)。我們可以根據我們的需求回復到任一天資料(1- 35天)。 - 快速的資料回復:
當資料的metadata恢復完成後服務就上線了,而實際資料則會在背景做恢復。 - 安全:
Redshift提供多種安全方式保護,如加密,網路隔離,與符合多種的合規與稽核需求。 加密的部分,data in transit是用 SSL, data at rest則採用硬體加速的AES-256加密。Redshift預設使用會自行管理key的部分,但我們也可以使用自己的HSM來做密鑰管理。網路隔離則可以啟用防火牆來控制存取也可以把Redshift擺在VPC裡。而合規與稽核,Redshift則會記錄所有的SQL操作,這些紀錄都可以在system table中看到並且可以下載到S3中。Redshift符合SOC 1/2/3與PCI-DSS level 1的合規需求。更詳細的合規清單可以參考AWS的網站 - 相容於SQL:
Redshift是一個 SQL DW並採用業界標準的 ODBC/JDBC來連接。
Redshift 的架構
Redshift的架構類似於Hadoop,是一個Master-Slave MPP, shared-nothing架構。Redshift有兩種主要的node類型,leader與 compute:
- Leader node:
在我們啟用Redshift的過程中我們不需要特別指定哪一個node是leader,因為在整個cluster中,leader node 與compoute node的規格是類似的。Leader node的主要功用是在提供一個SQL endpoint,儲存metadata,協調在compute node群中SQL的平行處理。SQL 或BI工具可以使用ODBC/JDBC來連接到 SQL endpoint。leader node 將使用機器學習來產生高效能的query plan,根據需要將short queries路由到avaiable queue,快取其結果與編譯代碼等。 - Compute node:
實際的運算節點,並由leader node來指揮。一個compute node是被partition 成多個切片(slices), 切片的數量取決我們底層EC2型號可以從切成2到16個。所謂切片是在Redshift最基本的運算單位能力,我們可以把它看成就是在一台實體機中運行的VM,也就是它是一些資源(cpu/memory/disk space)的邏輯組合。執行由leader node配發的運算作業。每一個切片會像SMP(symmetric multiprocessing)單元般與其他切片協同作業。
哪關於Redshift底層的EC2的instance type是要依我們所需要的作業負載來選擇的。下表為Redshift可供選擇的instace type,其中除了一些基本的電腦規格外還寫明了可以支援多少的slices.

由上表中我們可以看到node size可以到64TB(RA3),Redshift單一cluster可以有128 node。所以Redshift單一cluster可以支援到8.2PB。
Redshift Spectrum / Lakehouse Nodes
Data Lake(資料湖)是現在很多組織在導入大數據分析時會用到的服務。Redshfit提供 lake house的功能,也稱 Redshift Spectrum。這個功能主要跟Athena一樣可以讓我們Query位於 S3中的各類資料(Acro, CSV, JSON, ORC, Parquet等等)而不用把資料搬到Redshift。要使用Redshift spectrum就必須要有一個Redshift cluster搭配使用。下圖為Redshift 與Redshift spectrum的架構圖

Redshift AQUA(Advanced Query Accelerator)
Redshift AQUA是一種利用分佈式硬體加速的cache layer功能。這個功能擅長將需要 scan 與 aggregation-heavy的作業加速的能力,特別是我們在與資料互動(分析資料)與資料轉換時特別會用到。AQUA使用是AWS客製化的硬體(AWS Nitro晶片),這種客製化硬體強化其cache layer。Redshif AQUA的架構圖如下

AWS利用其自行研發的晶片 Nitro將硬體針對資料的壓縮,加密,解壓縮,解密的效能做了大幅改進。
有了AQUA,Reshift就能將其運作邏輯整合到Cluster中。根據AWS的說法,這樣的架構會是一般傳統雲端DW 的10倍效能。Redshift也提供Materialized View(整合AQUA功能)能夠處理多個tables的joins,特別是聚合(aggregation)。
Redshift 的可擴充性
Redshift的可擴充性主要分為兩個部分,Storage 與compute。大部分的DW都是擴充(scale up) storage或compute,而Redshift允許我們個別的擴充它們。Redshift提供的擴充的功能有:
- cluster 的resize
- concurrency scaling
- Managed storage for RA3 nodes
Redshift cluster的resize
我們會視工作量對cluster做scale up / down的作業。以下為redshift有的兩種使用狀況:
- Elastic resize — cluster內的所有node都是相同規格
- Classic resize — cluster內所有的node規格不一樣
Elastic Resize
不論是對cluster加入還是減少node,有以下兩個階段。在加入node時一定是要跟既有cluster note一樣的EC2 type。
Stage 1 :
當resize作業開始時cluster暫時無法服務,這時會先開始遷移cluster的metadata,這個過程相對比較短。而這段期間原有的session會被凍結住,而新的query則會被放在queue裡。
Stage 2:
這個階段session會回復。然後會將資料在背景重新分配(資料的重分配是根據configuration變動而有著不同數量的切片來分配)。這時的cluster已經可以開始read/write了。
Classic Resize
這種的resize轉換作業比較麻煩與複雜。基本上就是AWS幫你換成另一個cluster。
- 依據整個data size整個作業時間從一小時到數個小時都有可能
- 在轉換過程中所有的資料是以streaming的方式轉到新的cluster,這段期間內原來的cluster只能read
Classic Resize這種方式適合想要換instance type。
Concurrency Scaling
resizs的方式適合需要長期運行的模式。但我們若只是要跑一個臨時性的大量且是原來的cluster size不適合資料運算呢?這時可以用 concurrency scaling,這個方式redshift會幫我們加上一個過渡性的cluster以在幾秒鐘內以一致性和快速性能處理concurrent requests。
Redshift能在數秒內加上這種臨時性的額外運算能力。當作業完成後就會縮回原來的cluster capacity。Redshift允許我們每24小時中可以有一小時的 burst,所以是可以累積這種credit的。每個月底會重新計算一次這個credit。這種credit 的做法跟EC2的T系列instance很像。
Redshift Managed Storage
我們之前有提到Redshift spectrum可以幫我們Query在S3中的資料。Redshift managed storage實際上將storage和compute分開,因為它可以針對這兩個資源個別付費。當我們啟用 Redshift managed storage時 data block的功能就會從instance的內部硬碟轉換到S3中,而在instace 中的硬碟則會被當作cache layer。所以這將再度延伸Redshift可以處理的資料量。
Redshift cluster的 Policies與workload 管理
Rerdshift可以讓我們設定參數(parameter group),主要是維護某些Query的行為,如 time-out, logging等等。我們可以把參數看成是profile。關於各項參數的名稱與預設值可以參考下表

關於這個profile我們可以設定多個在不同的時機用在不同的cluster上。例如晚間時段是執行ETL作業的,白天是分析作業就可以套用不同的parameter group(profile)。
Redshift同時也支援WLM(workload management)功能,這是讓我們對Redshift的資源做優化的管理分配。若我們知道在Redshift各項作業的優先順序以及需要使用的資源就可透過WLM來管理。但若甚麼都不知道就用Auto WLM的功能,顧名思義就是redshift自動幫你管理。Auto WLM會 確認query所需的資源量,然後調整concurrency level(平行運算的query數量)。 我們可以通過priority定義workload的重要性級別,然後優先處理workload。
以下為一個手動設定的WLM範例,Quer1 我們希望有45% memory,Query 2則是35%

Redshift Lakehouse
前面稍微提過這個功能,就是讓Redshift有能力query 在S3中的資料而不用搬動資料進Redshift。能達成這個功能是其底層有一群Redshift Lakehouse nodes,幫我們平行處裡(query)S3裡的資料。在Redshift 裡的每一個切片可以驅動10個Redshift Lakehouse nodes,所以如果我們有32個切片哪我們同時就可以驅動320 Lakehouse nodes。
當我們Query S3中的資料(該資料的metadata是位在Redshift裡,而非 Redshift Lakehouse)時,Redshift會使用機器學習的方式在leader node優化與編譯該query,並且確認在plan中的元件那些是可以跑在本地端的,那些是需要從Lakehouse擷取資料的。這個plan被發送到所有compute node,這些node使用data catalog來獲取用於partition pruing的partition資訊。 如前所提,每個切片有 10 個 Redshift Lakehouse node的能力,每個compute node使用此能力向 Redshift Lakehouse layer發出parallel request。Redshift Lakehouse node 將scan S3 data和project,根據需要進行filter、join和aggregate,然後將結果發送回 Redshift,在那裡進行final aggregation在 Redshift cluster中完成與 Redshift table的連接 . 然後將查詢結果發送回client 端,client可以是 BI tool或query editor。
下圖描述了整個Redshift cluster與Redshift lakehouse的運作過程

根據上面的運作過程我們可以得知Redshift Lakehouse能夠
- 支援ANSI SQL
- 在Data lake中支援多種檔案格式,如 Parquet,ORC,JSON等
- 能夠讀取壓縮與加密的檔案
- 支援複雜的joins, nested queries與window functions
- 支援位於S3中的partitioned data,包含動態的partition pruing
- 能夠使用 Glue/ EMR Hive metastore當作Data Catalog
啟用 Redshift Lakehouse有以下三個步驟:
Step 1:
設定external schema。這可以使用 Glue Data catalog或 Apache Hive metastore。
語法: CREATE EXTERNAL SCHEMA <schema_name>
Step 2:
將以下的的data resource 註冊成external table
* AWS Athena
* Hive Metastore
*Redshift CREATE EXTERNAL TABLE語法

Step 3:
指定資料的位置 <schema_name>.<table_name>,開始query data
Redshift資料建模
Redshift是一個 Full ACID(atomicity, consistency, isolation, durability)跟 ANSI相容的DW。 它並沒有類似index的這種概念,不過卻用 distribution key與sort key來替代跟index一樣的效果。MPP DB的重點始終在如何有效分配資料分佈在整個cluster內,Redsift也不例外,它選擇使用distribution key/sort key跟壓縮來達到效能方面的要求。
Redshift是一個Relational DB,意思是我們在塞資料進去前就必須知道其資料結構。一個Redshift cluster建議只要一個DB就好。而一個DB可以有很多個schema(namespaces),每個namespace包含tables與其他DB objects(如 stored procedures)。
Reshift支援純量(scalar)資料型態,意思是我們不能使用List或Map。雖然Redshift是Relational DB,但它也支援半結構化資料(如JSON, AVRO)。
在我們設計Redshfit時通常有以下五種考量的因素。AWS已經將大部分的因素自動化了不過我們也可以使用Redshift Advisor(這是AWS建議的)。
- Sort key:
sort key是我們在下SQL語法中WHERE中會用到的。Sort keys如此重要是因為Redshift在disk中是用排序的方式儲存資料的。所以Redshift query optimizer也是使用排序放式來決定優化query plan。例如:我們都會經常query最近的資料,或者是query基於時間區間的資料,這時我們就可以用time stamp column當作我們的sort key。以time stamp當作我們的sort key時,Redshift就會根據這個將整個落在這個區間之外的data block給先排除掉,這樣我們要scan的資料就會減少進而增加效能。使用Redshift Advisor,它會給我們建議選哪個column當sort key。 - Compression(壓縮):
使用壓縮是因為壓縮過的資料可以減少 對於I/O讀取的次數。Redshift對於不同的columns有著不同的壓縮型態,因為Redshift 是 columnar架構。關於壓縮可以是手動與自動的(使用COPY command),AWS建議使用自動壓縮方式,因為Redshift會分析資料集後決定最好的壓縮法。 - Distribution Style:
我們會使用distribution key來將資料均勻的分佈在cluster中並能促進一般的join type,這樣就可以減少在query 時的資料移動。當我們將資料載入到Redshift中時,它將根據我們在create table時選擇的distribution style將table的row分配到compute nodes和slices。 - Table維護(Vacuum, Analyze):
當我們從Redshift刪除一筆特定資料時,Redshift並不是實際真的去刪除它,Redshift只是去標記這筆資料是刪除的。意思是被我們指定刪除的資料還是占著cluster內的儲存空間,這時就需要使用Vacuum來幫我們清空間出來。
此外,存在Redshift裡的資料都是經過排序的,意思是當有新的資料(new row)進入時在哪個狀態中它們還是未經排序的除非它們以sort key的incremental order到達,這對於不是transactional data的資料通常是不可能的。需要使用Vaccum sort對disk上的資料進行重新排序,以提供更好的資料排序性。 Redshift 現在自動運行 VACUUM SORT 和 VACUUM DELETE 以提高整體query 效能。此外對VACUUM來說,分析能協助我們更新table的統計數據,這一類的資料能增加sort key的效能。 - Workload Management: 這個我們在之前有提到過了。我們可以用手動與自動(ML)的方式,AWS建議使用自動化的方式。
Redshift上常用的資料建模
以下是幾種在Redshift的資料建模方式
STAR Schema(最常用的)
在這個模式下資料會被分為兩種形式, fact table(通常資料量較大,數量少)與 dimension tables(資料量小,但數量多)。這兩種table通常會是fact table 參閱 dimension table。所謂fact table會參閱一個特定的event,而這種event一旦在DB中是幾乎不會修改到的。舉例: 一筆信用卡交易就是一個fact,但交易裡的細節,像是買甚麼商品跟種類,商店的店號等這些都是Dimension。 構成fact的dimension通常具有更有效地存儲在單獨table中的屬性。(PS: SAP HANA DB採用的就是這種方式,有興趣的讀者可以參考本部落格HANA的文章)
Snowflake / Denormalized Tables
類似STAR schema的方式,但主要schema的呈現方式是一個經正規化集中的fact table並連接著多個dimensions。Snowflake實際上是在 STAR schema中正規化dimension table的方法。當我們把所有fact table與dimension table全部擠在一個tbale中,看起來就會像雪花一樣。而GCP的BigQuery就是採用此種方式,有興趣的讀者可以參考本部落格GCP的文章。
另外有些人在DW的DB中會用aggregated table的方式來做,這跟上面提到的兩種做法是完全相反的。
Redshift中的Data Type
下表為Redshift所支援的data type

我們都知道根據資料選用正確的data type對DB的整體效能是有影響的。另一個有關效能的具體化經常運算的資料到一個pre-aggregated columns中或是使用materialized view。 Materialized views提供一個自動化的方式讓我們能預先運算一個資料聚合。
對於像 JSON 這樣的半結構化資料,我們應該以explicit columns的形式對有用的Application domain中的屬性進行建模。 explicit column的column可用於filter和join,但在JSON 資料裡不是explicit columns提取的其餘row則不能用於join和filter。 Redshift 提供了各種可用於處理 JSON columns的 JOSN function:
- IS_VALID_JSON
- IS_VALID_JSON_ARRAY
- JSON_ARRAY_LENGTH
- JSON_EXTRACT_ARRAY_ELEMENT_TEXT
- JSON_EXTRACT_PATH_TEXT
我們要謹記Redshift是columnar DB這件事,因為它會影響我們query data。
Redshift的資料分佈形式(Data Distribution Style)
Redshift是分布式的DB,它會因為我們的資料增長而會有水平擴充(horizontally scale)的情況。之前說到Redshift會有一個leader node與一群compute node。 Data distuibution style會影響我們query data的效能,Redshift提供以下四種形式
1 . KEY
會選擇Key distribution是因為我們的columns是High cardinality(高基數性)。當我們選擇 KEY distribution時,由Key選擇的column其分佈是經過hash的並且有著相同hash value會被放到在相同的slice上。 一個普遍的原則是 FACT table使用其table 中的row identifier來跨cluster進行分佈。
2. ALL
這個方式是我們會需要copy dimension table(小量又多個)到cluster中的每個node。這樣做在於能夠讓 FACT+Dimension 的join產生很高的效能。這種方式會將dimension table放在每一個node的第一個slice。
3. EVEN
這種方式就是我們甚麼狀況都不知道,Redshift在此模式下是用 round-robin方式平均的將資料分配到所有的node。
4. AUTO
這是Redshift的預設選項。這個選項一開始會採用 ALL的模式,然後當資料開始越長越大時就會自動轉換成EVEN的模式。
Redshift的Sort Keys
前面提到Redshift儲存在disk裡的資料是經過排序的。採用sort keys也能幫助我們達到像index一樣的效能。Redshift也使用zone maps的概念,這是一種Redshift會根據每一個data block的最大與最小的Values並存放所有的data block最大與最小值在記憶體之中。當執行query時,只要那些values不在那些data block的範圍中Redshift就會把它排除,以此減少不必要的I/O。
Redshift支援以下兩種sort keys:
Compound sort key(預設)
這是使用一個或一個以上column來當sort keys。sort keys中的columns排序非常重要,因為它會決定實際的資料在disk中的排序。根據最佳實踐我們的排序應該是cardinality(基數性)由低到高。這對我們後續的 filter或join的操作增進效能。
Interleaved Sort Keys
這種方式會把每一個columns的權重看成是一樣的。好處在於如果我們的Query使用不同的access path(存取路徑 — 通常存取路徑可用以表示資料間之邏輯關係,而存取路徑通常是透過索引或鏈結等方法來實現的。) 與不同的columns來filter或join,這種做法就是有用的。不過這種方式通常用在一些極端的案例中。
以下有一些在Redshift中使用sort keys時需要考量的:
- 大部分的人大都使用compound sory keys,但對新手/初學者來說用 Interleaved sort keys的吸引力比較大。因為不用知道組織的業務邏輯,給它大鍋炒就對了。但它會對效能產生很大的影響,特別會增加資料載入Redshift的時間與增加vacuum(資料清理)時間。
- sort keys中的coulmn 選擇應該是我們在SQL語法中會經常用在WHERE條件中。
- 重申,在sort keys中column 的排序很重要
- compound sort keys的coulmns數量建議在4個上下。過多的columns雖然會增強其效能的邊際效應但同時也增加了資料ingest時的overhead
- 如果tables需要經常join,哪應該用distribution key為在sort keys的第一個columns
- 在 predicate(無聯結述詞) clause使用 CAST function會導致full table scan並且不會用到sort keys
- 我們可以途中更改Sort keys,但Redshift需要時間對該table的資料重新排序
Redshit的臨時性tables
Redshift 支援 temporary tables. create temporary table 語法如下
CREATE TEMPORARY TABLE <TableName> {Table Definition}
CREATE TEMPORARY TABLE <TableName> as {Select Query}
SELECT….INTO #MYTEMPTAB FROM {tABLEnAME}temporary table顧名思義就是臨時性的,在Redshift中有temporary tables的session是有時間性的,session結束後table會被drop的。預設中這類的table沒有壓縮,而且資料是平均分配在cluster內的。temporary table提供了更快的I/O(因為它不需要mirror data到其他的node).我們可以使COPY 與 UNLOAD temporary tables.
這類的tables經常會做為整個ETL流程的一部分,但需要確認我們有針對這些table計算其統計資料。
Redshift的Materialized Views
這是一種根據已定義好的SQL query而預先運算其結果的View。這個materialized view的資料更新來自於 REFRESH command,Redshift會決定更新的方式是 incremental refresh or full refresh。
materialized view的效益是我們要跑的資料是複雜的,要跑很久的,要用掉很多資源的並且資料量很大。像ETL或BI tool這種定期且重複的大量運算就很適合。(SAP HANA對於這一類的view用得很多,並鼓勵user使用)
以下為使用materialized view(以下稱MV)使用上的考量:
- Query參閱 MV的運算全部都會跑在primary cluster而不是 concurrency scaling clusters。
- MV可以參閱所有的Redshift objects但以下除外,其他的MV standard view/ external tables/ system tables or view / temporary tables
- 某些SQL操作會需要 full-refresh(如outer join, 數學運算如RAND, window functions等等)
- 資料若在base table有異動,在MV的update就會自動REFRESH。
- 在base table加入新的column不會影響到MV,但若是 columns的 drop/rename, MV的rename 或 MV的SQL definition變動就要重新create MV。
- 有些初始化的操作(如 手動執行 vacuum, classic resize, alter distribution keys or sort keys 與truncate)會強制在下次run REFRESH 時完全重新運算 MV
Data Lake的資料建模
我們之前提到過Redshift Lakehouse使用Data Lake(in S3)的模式。其基本就是Redshift會知道檔案(實際資料)都在那些位置中。而實際資料在Redshift與在外部有著不同的考量:
- Data Lake中的檔案數量應該要是倍數於Redshift切片。Redshift Lakehouse可以針對Parquet, ORC, Bz2,文字格式等檔案類型自動拆分。
- 每個檔案的大小應該在 64- 512MB
- 檔案的大小需要統一(像Avro, Gzip等檔案無法被拆分)避免執行上發生落差;因為 Lakehouse 的query效能是follow最慢的哪一個node。
- 應該使用在Redshift Lakehouse專為Data Lake而優化讀取效能的檔案格式,像是Parquet與ORC。因為至這些檔案也跟Redshift一樣是columnar編碼的方式。
- Redshift Lakehouse也支援 Avro, CSV, JSON等檔案格式,但這些檔案與ORC/Parquet相比會在S3上占很大的空間
- Lakehouse會基於在S3的結構實行 partition pruning。有兩種:一種是基於 Hive Metastore pruning,這不是Redshift Lakehouse 特定的,它也適用於 EMR、Glue 。也可以使用 Glue Data Catalog partition columns.
- Partitions應該基於: 經常需要filter/join / WHERE clause的columns,或是業務單位,或是是日期與時間
- 如果是 Date-based的partition column有以下型態:
Full date在一個single value,經過格式化或不是yyyy-mm-dd 或yyyymmdd。如果是格式化過的哪資料型態只能是strings。如果要把date用在排序(order by)的功能只能使用 yyyy-mm-dd而不能是dd-mm-yyyy
資料的載入與卸載
將資料載入Redshift分為以下兩種情況
- 一次transaction
- 使用多次的transaction並都透過leader node
理論上來說,我們應該盡量減少transaction次數來載入資料,因為transaction的數量與載入的效能是反比的。而DW的載入效能經常是量測DW的KPI之一。如果是要用leader node來載入資料,哪麼每一個transaction資料量應該都要是少量的。如果是大量的資料應該是用單一transaction來處理,因為它可以讓compute node一起加入平行處理載入的資料。
以下是使用leader node在每一次的transaction支援的資料載入
- INSERT
- INSDERT(multi-value)
- UPDATE
- DELETE
單一transaction透過leader node與compute node
- COPY
- UNLOAD
- CTAS
- CREATE TABLE (LIKE…)
- INSERT INTO (SELECT)
- 從 S3, DynamoDB, EMR, SSH command載入資料
Redshift COPY command
這種方式會比單一row insert有著載入資料更高的效能,因為它會讓compute node一起加進載入資料的作業。一般的COPY command的語法如下:
COPY <TBALE> from <location>
credential “aws_access_key_id=<access)key>”;aws_secrt_access_key=<secret_key>
iam_role “arn”
region;
當我們使用COPY command時有下面的選項可以選
- 載入的檔案型態,CSV, JSON, AVRO
- 壓縮方式
- 加密方式
- 轉換方式
- 資料格式透過 DATEFORMANT, TIMEFORMANT
- APPECTINVCHAR 來取代無效的值,用 quest makr(?)
- 可選maiifest file可以指示 COPY command 僅載入資料加載所需的input file,以及在input file丟失的情況下如何回應
資料載入的最佳實踐
以下為Redshift載入資料的最佳實踐
- 盡可能的使用COPY command來載入資料
- 每個COPY command對應一個tbale。
Writes are serial per table
Commits are serial per cluster - 如果真的不能用COPY,哪應該使用multi-row insert。
Bulk insert的操作(INSERT INTO..SELECT and CREATE TABLE AS)可以提供高效的 data insertion - 使用stage tables
- 按sort keys順序載入資料來減少(自動)VACUUM 的可能需求
- 在正確的時機點使用time-series tables。
將資料組織為一系列的time-series tables,其中每個table都相同但包含不同time range的資料。
使用late-binding view來統一partitioned time-series tables。 - 拆分資料,基本上是要倍數於切片數量
- 壓縮資料
- 務必記住temporary tables上的column encoding和distribution keys。
- 在低工作負載期間,Redshift 會在背景自動執行VACUUM和ANALYZE,但 Redshift的user仍然有權再添加、刪除或修改大量rows (> 5%)。
- 如果載入相對於整個table大小的少量資料,則從 COPY disable column encoding analysis(COMPUPDATE) 和統計訊息更新 (STATUPDATE)
- 在Redshift 之外強制執行primary key、unique key或foreign key
- 考慮使用 DROP TABLE 或 TRUNCATE 而不是 DELETE
從其他AWS服務中載入資料
我們可以從 以下AWS服務載入資料
Kinesis Data Firehouse
Firehouse能自動的將資料載入Redshift中。基本上它使用了micro-batches streaming先將資料放到S3中然後再使用COPY command載到Redshift,這整段過程是使用manifest來自動化。我們可以更改的是batch size與在真的載入開始前可以暫停幾秒後開始。Kinesis Firehose 可以在載入之前對資料進行multi-AZ buffering,並管理所有壓縮和加密。
AWS EMR
資料會從HDFS載入到Redshift。但是,需要使用與Redshift相容的 bootstrap 來啟動EMR cluster從EMR 載入資料的COPY command如下
COPY <table> from 'emr://emr_cluster_id/hdfs_file_path' iam_role "arn"DynamoDB
從DynamoDB 載入檔案也是用COPY command。但COPY的效能取決與我們DynamoDB的RCU。COPY command如下
COPY <redshift_tablename>
from 'dynamodb://<dynamodb_table_name>' iam_role "arn" readration" '<integer>';SSH Endpoint
我們可以使用ssh的方式將資料載入。特別是我們地端機房的 NAS或使用SFTP的機器。它需要 SSH manifest(含有COPY command)在連結遠端的host並執行remote command。COPY的command如下
COPY <redshift_tablename>
from 's3://'ssh_manifest_file' iam_role arn" SSH [|optional-parameters];AWS Lambda
使用這個位於GitHub上的 aws-lambda-redshift-loader這個connector來將資料載入,但需要注意的是Lambda的session limit。
Federated Query
這個功能讓我們可以直接Query AWS的 RDS中的PostgreSQL與 Aurora PostgreSQL中的資料。意思是Redshift的intelligent optimizer可以對PostgreSQL下達查詢指令,PostgreSQL最後只送回查詢的結果。(PS.這個功能SAP HANA也有,但支援的他牌的DB比較多)。
用這個方法的好處是不用把資料搬來搬去了(就是不用搞ETL流程),可以直接做資料轉換。
從Redshift卸載資料
卸載資料通常會使用以下三種方式
- AWS Glue
- AWS Data Pipeline
- UNLOAD的command
使用UNLOAD command是比較直接的方式,它基本上就是反轉COPY command的程序(將資料從Redshift轉成 CSV or Parquet格式到S3)。UNLOAD的key semantics如下:
- 從 SELECT 語句運行。 由於資料的output通常很大並且其輸出效能是一個問題,因此該語法在所有compute nodes上平行運作。 如果想要output的資料是排序的,除了設定 PARALLEL=OFF 之外,我們還必須在 SELECT 語句中定義 ORDER BY。
- 加密與壓縮是自動的
- 產生出來的檔案數量會多於我們切片的數量
- 我們可以使用manifest file在我們的output operation,它有助於我們要將資料再移動到另一個Redshift cluster
- 我們可以控制寫入 S3 的最大file size以及是否要控制output的overwrite semantics。
Redshift的查詢最佳化
之前提到Redshift是一個ACID與ANSI SQL相容的DW solution,並且當要支援 stored procedures 與自訂義的 UDF(使用 SQL SELECT or Python)時會使用類似PostgreSQL的語法。一個典型的Redshift Query會有著以下階段
- Planning — 當我們 submit一個query後會被parse與優化成 query plan
- Compilation — Redshift 檢查其compile cache以查看是否可以找到query-plan match。 如果它可以找到query-plan match,它會reuse現有的compiled object; 否則,它將其轉換為sub-tasks,然後單獨編譯為 C++。
- Execution — 編譯後的code由compute nodes slices平行處理,然後由leader noder聚合其結果並傳回給requestor。
一個query plan是幫助我們了解與分析一個複雜查詢的基本工具。它讓我們看到了我們的query實際在cluster是如和運作的。當query plan的編譯完成後,execution engine會把query plan轉換成 steps, segments,與 stream
Step
step是執行query期間所需的單一操作
Segment
segment是需要由單一process完成的幾個step的編譯。 這是compute nodes的"單一切片可執行的最小編譯單元"。
Stream
stream是要分佈在可用compute nodes切片上的segment的集合。 一個stream中可以有多個segment,然後這些segment平行運作。
整個架構如下圖

Redshift的explain plan
我們可以在Redshift Query editor中使用 EXPLAIN statement來產生一個視覺化的explain plan。這個 explain plan是由下往上來讀取的,它能提供的資訊如下:
- Local 與 Lakehouse部分的執行步驟順序
- 預估每個step將會返回多少筆rows
- 每一個step中跨slice發出的資料總量(Network I/O是代價高昂的並應該盡可能優化)
- 一個step相關的操作代價
我們可以使用 STL_EXPLAIN table查看之前在系統上運行的query產生的explain plan的歷史趨勢。 來理解explain plan的關鍵組成部分之一是理解explain plan產生期間使用的術語。 如前所述,Redshift 是一個 MPP DB,其中許多compute node協同作業以產生高效能的作業,這意味著網路在資料處理過程中成為一個非常重要的部分,尤其是join processing。 在join的特定步驟中,我們可能需要處理未存儲在本地的資料,因此需要處理來自同一node上不同切片的資料,或者在最壞的情況下,可能需要擷取不同node的資料。 由於網路傳輸是到現在為止在query執行作業中的代價最高的操作,因此了解資料如何跨node移動非常重要。 下表描述了我們在explain plan中看到的術語。

編寫Query的最佳實踐
以下是在Redshift上編寫Query的指引
- 會使用Reshift的團隊或人員要制定 coding standard,包含SQL語法的style。例如我們可能喜歡用ANSI多餘 equijoin,但我們應該選擇其中一種。
- 一個理想的query應該只選擇跟我們的資料(row)有關聯到的column(千萬不要SELECT * , 這也是GCP BigQuery的強烈告誡)。這是使用 projection與 filters來管理的。
- 確認我們的 sort key, compression, distribution style, automated table maintenance(vacuum, analyze)與 workload management都有正確的使用
- sort keys的columns應該被使用在filter而不是functions。如果Application function(如 casting 成不同的format)是需的,我們應該要materialize成不同的column。
- 確認redshift的統計資料都是最新的
- 我們可以使用 SVL_QUERY_SUMMARY來評估我們的sort key是否是具有效能的
- 如果是 Lakehouse queries,確認我們最好是使用columnar encoding(Parquet or ORC)的檔案類型
Redshift的 Workload Management
WLM可幫助管理workload 中並避免比較短期、很快可以跑完的query卡在長時間運行的Query後面的queue中。 以下這三種 WLM 方法是互補的:
Queue(basic WLM)
這種方式會基於user group, query group, 或 WLM 規則(如, [return_row_count > 5000000])來將每一個query放到特定的queue中
Short-Query Acceleration(SQA)
這是用機器學習辨識 在cluster內short running query 的構成是甚麼。之後Redshift就會把這個辨識到的模式會套用到後面新的query並自動的把它放到 short-query queue中
Concurrency Scaling
這種方式我們之前有介紹過,一樣是Redshift透過ML方式來預測我們cluster的運作需要,在正確的時候自動加入暫時性的cluster來協助我們來執行作業。
如果我們的 parameter group使用的為預設的哪 Auto WLMc會自動啟用,如果是自定義的paremeter group則要開啟 Auto WLM就要在 Redshift console再去調整成Auto WLM模式。用Auto WLM會有一個queue來管理query,並且 memory與concurrency 在 main fields都是設定成自動的。但如果沒有啟用Auto WLM,手動式的WLM會要求我們對memory與concurrency設定一個allocation的值。
WLM queues可以定義一個特定的priority(相對來說比較重要的),query將繼承queue的priority。 Admin可以使用priority來確定不同workload(例如 ETL、ingestion、audit和 BI)的priority。 Redshift 在讓Query進入系統時使用priority來確定分配給Query的資源量,從而為High priority workload提供可預測的效能。 但是,這是以其他low priority的workload為代價。 重要的是要認識到,low priority的Query可能會運行更長時間,因為它們正在等待更重要的Query或使用較少的資源運行。 我們可以啟用concureency scalingx來處理low priority來達成這類作業的可預測效能。
WLM : Querying Monitoring Rules
我們都看到Production環境中的使用者會對資料進行代價高昂的join,導致系統可能會得到數十億筆rows並消耗所有資源(這產生了Cartesian product笛卡爾積)。 Redshift 提供了query monitoring rules(QMR),顧名思義,這是提供規則來監控query,尤其是失控的Query。
可以通過 Redshift console為 WLM queue定義QMR,這可能導致以下四種Query actions其中之一會發生,因為這些actions違反了規則:
- LOG — 這是有關Query的資訊,這些資訊會放在 STL_WLM_RULE_ACTION的table中。
- ABORT — 紀錄 query action並終止它
- HOP — 紀錄這個query action並將它移動到其他較適合的queue,但如果這個適合的Queue不存在就終止這個query action
- PRIORITY — 更改query的priority
Redshift的Security
Redshift提供以下四個level來保護我們的資料
Cluster Management — 透過AWS IAM來控制在 redshift console的query editor 或 使用ODBC/JDBC來對 Cluster進行 create/configure/delete
Cluster Connectivity — 使用Security Group來控制連接
Database Access — 在Redshift DB的 user accounts中對Object level(tables or view)進行access control
暫時性DB的credentials與SSO (single sign-on)— 可以利用IAM credentials來logging 到DB或透過能與 SAML 2.0相容的 identify provider的federated SSO方式。
Redshift Cluster的VPC架構
compute nodes 是位在 AWS所管理的private VPC 中,該 VPC 只能由 Redshift leader node 存取。 leader node位於compute nodes的private/internal VPC 和我們的 VPC 中,以允許存取Redshift cluster並處理compute node之間的資料分佈。 High bandwidth connection和自定義communication protocol在leader node和compute nodes之間提供private、非常高速的網路。可參考下圖

Redshift 的網路拓璞圖與Security Group
Redshift沒有跟大多數的AWS服務擁有較高的可用度。Redshift目前支援跨兩個 AZ。而Redshift cluster預設是lock down的,意思是是用白名單的方式管裡。為了讓我們可以存取到Redshift cluster,第一步要做的就是設定Security Group。我們除了用Security Group也可以用 Cross Account Access(建議使用的方式)。
基本上建議每個Application都不同的cluster security group。我們之前也介紹到Redshift與S3的整合度非常高,哪Redshift在與S3連結時可以透過 Internet Gateway, Egress-only NAT gateway, NAT gateway, private S3 endpoint, 與 enhanced VPC routing(EVR)。
Redshift使用EVR的方式適用於 COPY, UNLOAD, backup與 Redshift ,它是透過customer VPC endpoint的方式來取代走Internet的方式。EVR也會有 VPC flow logs的log,我們可以把它apply在VPC endpoint policies中。
Redshift的Data Security
Redshift對其資料保護的方式於其他DB相似,使用 schemas, users, usergroup:
Schemas DB tables與其他DB objects的集合(類似namespace)
Users 能夠連結DB的user account
Groups 使用者群組
我們依據上面三個概念可以設定user 對DB中特定的Object實行access control。根據預設值 object 的cretaor會就是它的owner,並且有權給予其他account權限來access。
而最高權限者稱為 master user(superuser),從provision cluster到cluster所有的DB與Object都可以進行管理。而如果權限管理需要精細到甚麼user可以access甚麼 rows 或columns,則有以下三種方式
- 使用Materialized view,這樣user就不用進到table中讀取資料
- 指定user可以使用到的column,這種方式必需要用Redshift 預設的lock down方式才會有作用
- 可以使用 Redshift的Lake Formation 在裡面實行 fine-grained column-level policies。
Encryption of Data in Motion
Redshift在與其他AWS services溝通時是使用硬體加速的SSL方式來加密傳送資料。若我們將參數 require_ssl設定為true的話,哪我們就將強制只能使用SSL連結到Redshift。
當我們載入資料到Redshift時,Redshift支援以下三種加密方式
- 在client-side使用 symmetric key來加密資料,symmetric keys會包含在COPY command中
- 透過 S3使用 KMS(SSE-KMS)做server-side加密
- 使用S3 SSE加密
資料被加密傳輸到每個執行資料載入的compute node,並使用我們的symmetric key在node上執行解密。 也可以使用 KMS encryption keys或symmetric key卸載資料。
Encryption of Data at rest
Redshift使用256-bit key來為在Redshift local driver做加密,如同資料存放在S3相同。配合Redshift的Key management我們可以使用 KMS或自己的 HSM。若Redshift使用到S3當作data block其加密也是使用Redshift的encryption key。為了減低CPU的負載,Redshift使用hardware-base的加密模組。
AWS建議使用KMS的加密方式來加密Redshift at rest的資料。我們可以針對key來做到最高四層式的加密,Master key, Cluster encryption key, Database encryption key, Data encryption key。可參考以下架構圖

Redshift的Audit Logging
Redshift提供 三種 audit logging DB-level activities的選項可用
- Audit logs: 這會存放三種檔案在S3中,分別是 connection log, user log, user activity log。預設沒有啟動所以必須指定啟用。基本上這檔案會永存在,除非我們對其進行生命週期管理。
- System (STL) tables: Redshift會有多個system tables(如svl_STATEMENTTEX, SVL_CONNECTION_LOG),這些system table都包含了audit logs。 superuser對這些tables才有控制權。這些logs紀錄會根據log usage與disk大小保留2–5天的紀錄。我們可以將這些資料定期的備份或使用前上衣種方式。
- CloudTrail log: 熟悉AWS的人都知道這一個audit log services,不過它只能提供到 services-level activities的紀錄,像是request是成功還是失敗與request的來源。
Kinesis Data Analytics
這是針對 data stream的即時資料分析。其主要目標是減少在build、manage和integrate streaming application與其他 AWS 服務相關的複雜性。Kinesis data analytics可以使用template 與interactive SQL editor的方式來 build整個 streaming Application。
在分析即時資料的過程中, Kinesis data analytics會視負載來自動擴展所需要的分析資源。
下圖為Kinesis data analytics的運作架構圖。它可以與很多的streaming application整合(如圖所示),並且在分析之後將其結果傳送到再傳送到其它分析工具。

作業方式
Kinesis data analytic是對其streaming data直接使用SQL語法處理期資料,並可以把處理結果對外輸出。每個Kinesis data analytics Application都包含三個部分
- Input
每個Kinesis data stream都會有資料來源,如我們之前所講的。這個來源我們可以把它想成是一個持續不斷update table的動作,但我們可以對其這個不斷被update的tbale使用 SELECT 與 INSERT的SQL語法
2. Application code
就是能讓我們處理 input資料的一串連續的SQL statement,並且能輸出結果。這個SQL statement除了可以處理streaming data同時也可以reference table並對這兩個來源做join。
雖然我們處裡的streaming data是一直流動的,雖然我們處理資料通常以row-level來處理是比較合理的。但大部分的狀況都是以時間區間來處理資料(例如每五分鐘)或一個資料總量(例如過去100筆交易)。
一個例子可能是金融機構查看過去 24 小時的現金提取資料,以查看用戶是否已按照每日限額從其賬戶中提取資金。
而Kinesis data analytic提供給我們使用 windowed SQL query的方式來處理資料。這是以時間區間(time-based windows)或records筆數(row-based windows)作為一段資料處裡的邊界。若是以time-based windows來說我們就要訂出一個明確時間(例如過去的一小時),但time-based windows的方式需要在我們的資料中要有time-stamp column。 row-based windows比較好解決,就是計算到一定的row就開始處裡資料。
Kinesis Data Analttics有三種windes type的資料處理方式
Staggered Windows: 這種方式用於當我們到達的資料順序與source發出的是不一致的。它們對於解決沒有落在一個特定 time-restricted windows的records導致發生tumbling window issue是有用的。Windows在match partition的第一個event到達時打開,而不是在固定的時間間隔內打開,並根據遇到第一條record和打開窗口時測量的window age來關閉。
Tumbling windows: 這是資料會依順序並在一定的時間內到達的資料。所以每個window之間不會有overlap。每筆record只會被處理一次。
Sliding windows: 當我們根據是某些內部變量分析資料時,sliding windows是適合這個狀況的,這些內部變量根據最新時間或最新record移動。 例如,如果我們正在計算過去 5 分鐘的平均值,則每次運行query的結果可能會有所不同,具體取決於運行query的時間
3. Output
我們可以對其處裡結果輸出到其他的服務(如我們之前提到的)或是暫存這個結果(類似temp table)
Batch Processing 服務比較
AWS提供了一堆不同的資料處理服務。到目前為止我們看過 AWS Glue與ASWS EMR。在這兩種data processing服務如何根據我們的需求來選擇呢?我們可以參考下表,針對每個不同的data processing服務來與另一個相比的不同之處

整合AWS服務成自動化資料處理Pipeline
簡單的來說就是 我們的 Data orchestration。怎麼自動化並組合這些AWS資料處理的服務成為一個end-to-end的自動處理流程,之前我們介紹過 AWS Glue workflow與AWS Data Pipeline。另外我們也可以使用 AWS Step Functions,這是一個全託管的服務。這可以讓我們把這些服務組合成一個worflow,並且具有error-handling與retry支援。Step Function還具有視覺化監控並可以稽核執行步驟。
下標為AWS具有ETL功能與open source tool的比較表

