設計GCP資料庫的高可用、高可靠、高擴充性
Availability/Reliability/Scalability
這一篇我們要來介紹GCP資料庫(Bigtable/ Spanner/ Bigquery)的Availability/Reliability/Scalability。同時也會介紹這一些資料庫在設計schema與Query data的最佳實踐。在每一種的資料庫服務上根據它們的DB特性的優勢來設計我們的業務需求。
我們先前在建置與管理Google Cloud的儲存服務有強調 GCP 資料庫的一些功能。 這一篇我們將要更詳細的說明如何針對以下三種GCP 資料庫來設計availability/reliability/scalability。
- Cloud Bigtable
- Cloud Spanner
- Cloud BigQuery
在這邊不介紹Cloud SQL的原因在於,目前Cloud SQL的scalability只能在region level. 如果我們需要RDBMS能跨越region level的scability就需要使用Cloud Spanner. 不過GCP Cloud SQL現在提供的跨region的資料複寫服務,可以達到一定程度的availability。
本文讓我們理解如何實行design schema, query data, 與利用每種資料庫的物理特性設計的最佳實踐。
Cloud Bigtable DB
一種基於sparse three-dimensional map的NoSQL 資料庫. 三個維度(Dimension)是指 rows,columns與cells. 通過了解這一種 3D map的架構,我們就能找到如何設計Cloud bigtable schemas 與 table的最佳方式來達到 scalability/reliability/availability的目的。以下是我們所需要考量的事項:
- Cloud Bigtable的Data modeling
- row-keys的設計
- time-series data的設計
- 使用replication 來強化scalability 與availability
Cloud Bigtable的Data modeling
Cloud bigtable的3D map架構讓它得以實現一種分佈式的實作。Cloud bigtable DB部署一種資源集被稱為instance. (這與 compute engine的VM instance 是不一樣的事) Instance是由一群node所組成的,node就是VM,以及一組儲存在Google Colossus filesystem中的 排序過的string tables與log data。下圖為Cloud Bigtable的基本架構

上圖中我們可以看到Bigtable使用了由VM組成的cluster與google 底層的 Colossus filesystem來儲存,存取跟管理資料。
當我們create Bigtable insatnce時,我們就是在指定一群nodes. 這些nodes其實是在管理bigtable DB的metadata,而實際的資料則是存放在這些node之外的 Colossus filesystem. 在Colossus filesystem資料是被排序過的string table,或是SStables(也稱為tablets,這是GCP自己的術語)所組織起來的。顧名思義,資料按排序順序存儲。 SSTable 也是不可變的。
將metadata從data分離出來有以下的效益:
- tablets從一個node到另一個node的快速重新平衡
- 只可以只通過migrate metadata來恢復故障node的能力
- Colossus filesystem對資料的scalability/reliability/availability
在cluster中的master process是平衡工作負載, 包括tablets的分割與合併。
在Big table中, row是由 row-key來做indexes, 類似於RDBMS的primary key。資料會讓row-key按字母順序排序的儲存。通過使用row-key指定特定的row或使用row-key range指定一組連續的row,從 Bigtable 中檢索資料。 Cloud Bigtable 中沒有secondary indexes,因此擁有一個主要在支援與資料庫一起使用的query patterns的row-key非常重要。
Columns是第二個維度。 它們可以被群組成一個column family。這個方式可以很有效率的讀取一群經常被放在一起讀取的資料. 例如街道地址,城市,鄉鎮,郵遞區號這幾個欄位就是經常會被一起讀取的。所以我們可以將這幾個column組成一個column family。在column family中cloumn也是按字母順序被排序存放的。
Cells(就是row 與 column的交集點)是第三個維度, 而且會隨著時間的推移在cells中的值會有多個版本。例如,cell儲存了一個客戶的電話號碼。當對這個號碼做update時,新的電話版本被加入並同時會用timestamp對其做indexes。 預設中, 在做資料查訊時bigtable會返回的值是這個cell中的最新timestamp版本。
Cloud bigtable tables是 spares的 — 意思是,如果沒有data放在特定的 row/column/cell 時,就不會使用到儲存空間。
當我們在設計tables時,我們應該使用幾個大的tables而不是很多個小的tables. 小的table問題在於,它需要比大的table更多的backend connection overhead。 此外如果我們的table size大小不一差異太大,哪就會中斷background的負載平衡作業。
所有在row level的操作都是atomic的。這有利於將相關資料保留在single row中,這樣當對相關資料進行多次修改時,它們都會"一起"成功或失敗。 但是,在single row中應該存儲多少資料是有限制的。 GCP建議在單一cell中存儲不超過 10 MB,在single row中存儲不超過 100 MB.
Row-keys的設計
在bigtable最重要的設計選擇之一是 row-key的選擇。原因是bigtable的performance scalability是來自於read/write operation是分散到nodes與tablets的。如果read/write操作都擠在一群數量小的nodes與tablets, 哪整體效能就會變得很差。
設計Row-keys的最佳實踐
一般來說我們應該避免在key的開頭使用單純的增加數字或值(例如1234567..這樣加上去),與使用的字串會按字母順序(像是ABCDE….),因為這樣會導致hotspots.
GCP特別打破了這一規則,並建議當entity可以表示為domain name並且有很多domain name時,使用反向domain name作為row-key。例如, jason.kao.example.com 可以反轉以建立名為 com.example.kao.jason 的row-key。如果某些data在多個row有重複,這將很有幫助。在這種情況下,Cloud Bigtable 可以有效地壓縮重複的資料。如果沒有足夠的不同domain來在node之間適當分配資料,則不應將反向domain用作row-key。
此外,當使用multitenant Cloud Bigtable 資料庫時,最好在row-key中使用tenant prefix。這將確保所有客戶的資料保存在一起,但不會搞不清楚資料是哪一個客戶的。在這種情況下,row-key的first part可能是customer ID 或其他客戶特定的代碼。
String identifers,例如customer ID 或sensor ID,是拿來當row-key的好選擇。 timestamp可以用作row-key的一部分,但它們不應是整個row-key或row-key的開頭。 當我們需要根據時間執行範圍掃描時,timestamp是有用的。 包含timestamp的row-key的first part應該是High-cardinality(即大量可能的值)屬性,例如sensor ID,3893436#1597749261 是一個sensor ID,它與一個以時期過去的秒數為單位的timestamp連接。 只要sensor以相當隨機的順序回報,這種排序就會起作用。
將timestamp作為row-key的first part是另一種field promotion屬性的作法. 一般而言要這樣做資料庫內值的變異是要很大的。
另外一種避免hotspots的方式稱為salting, 意思是在我們的key中加一些料(加一些value)讓這些vlaue變得不是連續性的。例如,我們可以對使用node number對timestamp使用hash. 這個方式將平均分散的將資料寫到所有的node.
Row-key的不好的設計
以下因素會讓我們的row-key設計變差
- Domain names
- ID是有順序的數字
- 經常update的identifiers
- Hashed values
domain names 與 有順序數字的ID會讓 read/write operation有hotspot的情形。而identifiers則不應該經常被update,因為update的操作會對底層的tablet(儲存的row也會被經常update)造成過載。
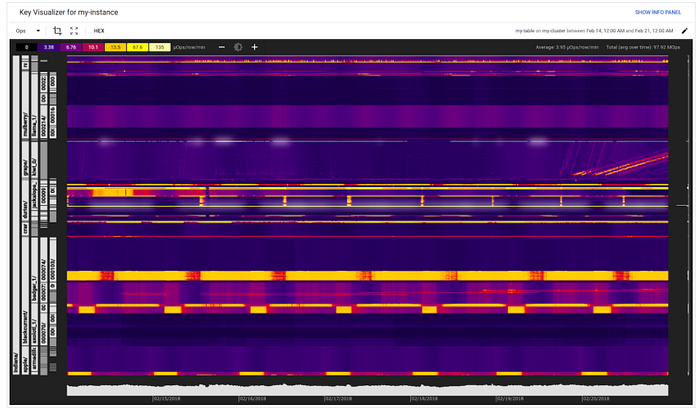
Key Visualizer
這是一個Bigtable 的工具。主要在了解我們的 bigtable 資料庫的usage patterns.這個工具能夠協助我們確認以下狀況
- hotspots狀況發生在哪裡
- Rows的資料也許太大了
- 工作負載在table中所有row的分佈
Key Visualizer 每小時和每天掃描一次table,這些table在某個時間點至少要有 30 GB 的data,並且在過去的 24 小時內平均每秒至少有 10,000 次read和write。 來自 Key Visualizer 的資料顯示在heatmap中,其中暗區活動度低,亮區活動度高.如下圖所示
設計Time Series 類型的資料
Time series 類型的資料適合table型態是row很多但是column數少。time-series 資料被query的方式通常都是以時間區間來filter資料。舉例來說,從IoT device送過來的很多資料時間常是同一天同一小時同一分鐘,這些都被bigtable存放在一起。這樣的存放模式可以大大減少在查詢時需要scan的資料量。
GCP建議了幾種方式來設計time-series資料:
讓names長度是短的 . 這可以減少metadata的size. 因為names與data values是儲存在一起的。
盡量使用的是many rows with few columns(也稱作 tall and narrow tables). 基本上每一個event 都是一筆row,不要讓一個row有多個event。這會讓查詢是容易的。況且多個event在同一筆row也可能讓row size爆表。
使用tall and narrow table的方式會變成是one table per modeled entity. 舉例來說,我們有兩種sensor, 一個是收集天氣的溫度/濕度/大氣壓力,而另一個是計算車輛經過的數量。兩種device都位在同一個地點並且同時一種頻率送出資料。雖然兩種sensor的資料都會被同一個Application所使用,但這兩種sensor的資料我們應該是用兩個table來個別存放。
row-keys的設計是用來找尋single value或一個區間的values. 掃描一個時間區間的資料對time-series的資料是很普遍的。Bigtable 的table只有一個indexes. 假如我們要在不同的排序資料來scan區間資料,哪麼我們就應該需要把這些資料做分正規化,並且依據我們要的排序方式做成另一個table存放。例如,我們有一個IoT application會用 sensor type 與被監控的device type來group資料,我們應該使用兩個table都各自的row-key來存放這兩種不同的資料。為了減少儲存成本,只有IoT Application會query到的這兩個type收集到的資料才被需要儲存在額外的table.
使用Replication達成Availability and Scalability
Bigtable 的replication功能可以讓你的cluster的資料有多個副本,不管是跨AZ或是跨region. 這樣可以達成資料的availability 與 durability. 我們也可以利用這個特性達到負載分散到多個cluster. 當我們create bigtable instance時我們可以create 多個cluster(如下圖)

Cloud bigtable最高可以支援到4個 replicated cluster. 所以Cluster 可以是regional 或multi-regional。當有以下異動時它會自動replica到其他的cluster:
- Updating data in tables
- Adding and deleting tables
- Adding and deleting column families
- Configuring garbage collection
這邊需要說明一下, Cloud bigtable沒有所謂的primary cluster。所有的cluster都可以做read/write的操作。Bigtable是eventually cocsistent的,所以所有的replicas應該在數秒鐘至數分鐘後資料會一致。當然我們的資料越多有可能同步就要越久。
如果我們永遠都不想要讀取到的資料比最近寫入的舊,我們可以在app profile裡設定 read-your-write consistency。 App profiles 是來明定如何來handle client request的設定檔。如果我們要的是strong consistency,我們同樣也要在app profiles中設定,在strong consistency設定下,我們就無法對其他的cluster 做read/write, 除非我們要實行failover. 在region之間如果我們的failover要是自動化的,我們需要使用multicluster routing.
設計 Cloud Spanner DB的 Scalability and Reliability
這是Google的 globally scalable relational DB,它提供的是許多NSQL DB才有的scalability效益。但它同時也保持relational DB才有的key feature, 像是資料的正規化與交易型資料的support. 我們應當瞭解有哪些設計因素會影響Spanner的效能與scalbility。
以下幾個方面我們需要注意
- Relational DB features
- Interleaved tables
- Primary keys and hotspots
- DB splits
- secondary indexes
- Query best practices
Relational DB features
Spanner的許多功能與一般的relational DB是一樣的。Data model以table為中心,table由表示屬性的row和表示單個entity的屬性值集合的columns組成.Relational DB是strongly typed. 而Spanner支援一下的類型:
Array: 零個或多個non-array type元素的ordered list
Bool: 布林代數 TRUE or FALSE
Bytes: 長度不一的binary data
Date: 日曆的日期
Float64: 具有小數分量的近似數值
INT64: 帶有小數部分的數值
String: 長度不一的字串
Struct: 有順序類型field的容器
Timestamp: 特定時間(奈秒級的精確度)
Cloud Spanner也支援primary and secondary indexes. Primary index當在table指定primary key時就會自動產生了。其他的column或其他columns的組合可以被作為secondary indexes. 特別提一下Cloud bigtable沒有secondary indexes的原因是Cloud bigtable是將資料非正規化與將資料重複來支援不同的query pattern。然而在Cloud bigtable中我們需要duplicate data以在不引用primary key的情況下高效查詢資料,在Cloud spanner要達到高效查詢就要有secondary indexes並支援不同的query pattern.
Interleaved tables
Cloud Spanner 的另一個重要性能特性是它能夠交錯相關table中的data。 這是通過parent-child relationship完成的,其中parent data(例如order table中的一行row)與child data(例如order line items)一起存儲。 這使得從兩個table中同時檢索data比單獨存儲data更有效,並且在執行join時特別有用。 由於來自兩個table的data位於同一位置,因此DB必須執行較少的查找來獲取所有需要的data。
Cloud Spanner 最多支持七層交錯table。 使用 CREATE TABLE 語句中的 INTERLEAVE IN PARENT 子句交錯table。 例如,要將訂單(order table)與下訂單的客戶(customer table)交錯,我們可以使用以下命令:

當table頻繁join時使用交錯方式。 通過將相關data存儲在一起,與獨立存儲相比,可以使用更少的 I/O operation來執行joins。
Primary key與Hotspots
Cloud Spanner是 horizontally scalable, 所以它也會有一些Cloud bigtable的特徵。Spanner底層也是一群server,它使用key range將資料分散在這一群server中。這也有可能會造成hotspots的狀況。例如,有順序的做key的遞增就會造成跟Cloud bigtable 一樣會有read/write operation只在少數幾個server而不是將這些負載平均的分佈在所有的server上。
以下也跟bigtable一樣有一些避免hotspots的方式:
Using a Hash of the Natural key Cloud bigtable 不建議使用這種natural key的hash在cloud bigtable, 但是無意義的key是被經常使用在realtional DB的。
交換key中的columns順序以提升Higher-Casrdinality屬性 這樣做會使key的開頭更可能是非順序的。
使用Using a Universally Unique Identifier (UUID),特別是version 4 或更高版本 一些較舊的 UUID 將timestamps儲存在high-order bits,這可能導致hotspots。
使用Bit-Reverse Sequential Values 使用這個可以在最合適的primary key遞增時使用。 通過Bit-Reverse Sequential Values,我們可以消除hotspots的可能性,因為Bit-Reverse Sequential Values會跟下一個values有著差異。
此外,與 Cloud Bigtable 一樣,Cloud Spanner 必須管理將dataset分解為可跨Server分佈的可管理大小的單元。
拆分資料庫
Cloud Spanner會將資料分拆成chunk, 也稱為splits. 每一個splits大小會是4G左右,splits是一個top table 的row的區間 — 意思是,這種table是沒有跟其他table交錯的。在splits的row是根據primary key進行排序的,第一個與最後一個row就稱為splits boundaries.
如果這個row是交錯的,哪它就會與parent row保持一致。例如,如果有一個帶有交錯order table 的customer table, order table之下有一個交錯的order line item table,則所有order和order line item row都與相應的customer row保持在相同的splits中。在這裡,在create交錯的table時牢記splits和splits limits很重要。 定義parent-child realtionship會搭配data,這可能會導致超過 4 GB 的資料交錯。 4 GB 是分割限制,超過它會導致performance下降。
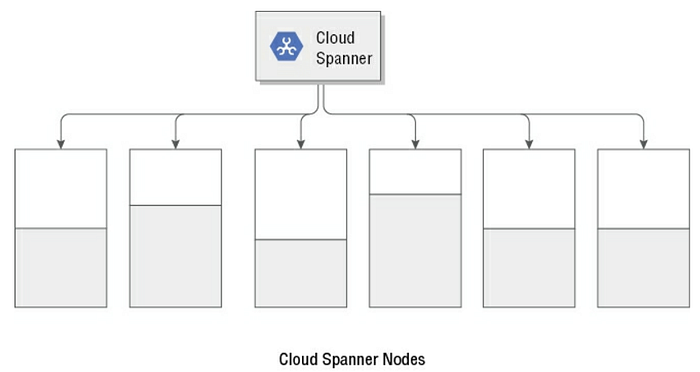
Cloud spanner 使用了splits這個方式來減緩hotsopts的狀況。假如Cloud spanner偵測到大量的read/write opertion集中在一個splits, 它就會將這個splits再把它分成兩個splits這樣這兩個splits就會在不同的server上。下圖為一個範例,一個cloud spanner instance底下有六個node,每個nodes的資料量不一(灰色部分顯示資料量)。Cloud Spanner有時是根據read/write operation的負載來決定分散資料到所有的node, 不僅是整個跨節點的資料量。這樣才能避免read/write的hotspot 發生在某一個node上。
Secondary Indexes
Cloud Spanner 為primary key以外的column 或column group提供secondary indexes。 當我們create primary key時indexes就自動被建立了,但secondary indexes就必須手動指定。
Secondary indexes在使用 WHERE 子句過濾查詢時很有用。 如果 WHERE 子句中引用的column有index,則可以使用index進行過濾,而不是scan full table再過濾。 當我們需要以primary key順序以外的排序順序return rows時,secondary indexes也很有用。
Create Secondary indexes時,這個indexes將存儲以下內容:
- base table中所有的primary key columns
- indexes中包含的所有column
- 任何額外在STORING 子句中被指定的column
STORING 子句允許我們指定要存儲在indexes中的其他column,但不包括這些column作為index的一部分。例如,你要指定customer table中的郵遞區號為secondary index, 指定的語法如下
CREATE INDEX CustomerByPostalCode ON Customers(PostalCode);
假設你在查找郵遞區號時需要經查連帶的找客戶的姓氏,你的secondary indexes就可以使用STROING子句指定LastName 這個column跟郵遞區號存放在一起, 語法如下
CREATE INDEX CustomerByPostalCode ON Customers(PostalCode) STORING (LastName);
由於indexes具有 primary key columns, secondary index coulmns, 於額外的LastName column, 因此任何query要查詢這些columns都可以從index中查詢而不需要去從base table中查詢。
當 Cloud Spanner 制定execution plan來檢索data時,它通常會選擇要使用的最佳indexes set。 如果測試之後顯示Query沒有選擇最佳選項,我們可以在 SELECT 查詢中指定 FORCE_INDEX 子句,讓 Cloud Spanner 使用指定的indexes。自動選擇最佳化的語法如下
SELECT CustomerID, LastName, PostalCode FROM Customers WHERE PostalCode = ‘10633’
上面的語法是使用在Secondary index的PostalCode來查詢,假如Cloud Spanner 的execution plan builder沒有選擇用這個indexs來查詢,我們可以使用FORCE_INDEX子句來強制它使用這個indexes, 語法如下
SELECT CustomerID, LastName, PostalCOde
FROM Customers@{FORCE-INDEX=CustomerByPostalCode}
WHERE PostalCode = ‘10633’
Query Best Practices
以下為使用Cloud Spanner的其他的best practices
使用Query參數
執行Query時,Cloud Spanner 會構建execution plan。 這涉及分析有關資料分佈、現有secondary indexes和這個Query中table的其他特徵的統計資訊。 如果僅更改某些過濾條件(例如郵遞區號)而重複Query,哪我們可以使用參數化的方式來替代我們只會更改的過濾條件,來避免每次Cloud Spanner都要rebuild 整個execution plan,這個方式稱為parameterized queries.
考量一個Application function,它返回給定郵遞區號的customer ID lists。 可以使用郵遞區號的字面上的value來編寫查Query,我們可以寫成如下語法:
SELECT CustomerID
FROM Customers
WHERE PostalCode = ‘10633’
上面的語法中如果我們只有要查詢的郵遞區號數字會經常性的變動,而整個語法結構都沒有變,哪我們就可以使用參數化的方式(用@符號)來取代這個會變動的數字,語法如下
SELECT CustomerID
FROM Customers
WHERE PostalCode = @postCode
該參數的value在 ExecuteSQL 或 ExecuteStreamingSQL API request的 params field中指定。
使用EXPLANI PLAN來理解Execution plans
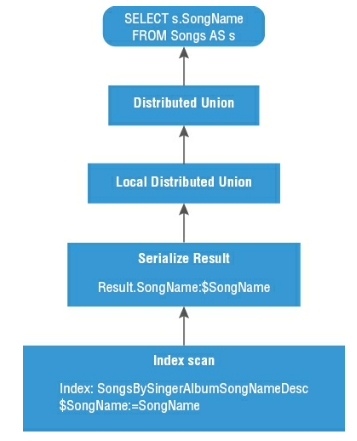
Query execution plan是一連串主要在檢索data與回應query的步驟。由於Cloud Spanner將data儲存分散在cluster node的splits中,因此execution plan一定會有在每一個node的subplans,然後每一個subplan的result就會全部aggregate起來成為最後的result.
下圖為一個範例,顯示了從songs table中選擇歌曲名稱的Query的execution plan的邏輯。
避免長時間Lock
當執行transaction時,DB可能會使用lock來保護資料的完整性。在某些狀況下我們應當使用lock read/write operation, 包括:
- 如果write取決於一次或多次的read 的result, 哪麼read與write應該在同一個 read/write的transaction中。
- 如果必須同時commit多個write operation,則這個write 應該要在 read/write transaction中。
- 如果根據read result可能有一個或多個write,則這個write應該要在read/write operation中。
當我們使用read/write transaction時,我們會希望將讀取的row保持在最低限度。這是因為在read/write transaction期間,在transaction commits 或roll bacl之前,沒有其他的processes可以修改這些row。避免在read/write transaction 進行full table scan 或大型的joins。如果真的要進行這些operation我們應該要在沒有要lock row的transaction執行。
為Data warehouse 設計BigQuery DB
BigQuery是一個被設計用來為Data warehousing, machine learning (ML), 與相關分析工作的分析式資料庫。雖然BigQuery可以使用Standard SQL作為查詢語言,但它不是relational DB。但有些relational DB的data modeling practices還是適用在BigQuery DB,不過有些還是沒有。在這一段,我們將看到如何設計可擴展的 Bigquery DB,同時還能保有它的高性能和成本效益。我們將會針對以下重點:
- Schema design for Data warehousing
- Clustered and partitioned tables
- Querying data
- External data access
- BigQuery ML
主要聚焦在如何運用Bigquery的feature來支援大規模的data warehousing.其他的features我們則已經在建置與管理Google Cloud的儲存服務討論過了。
Schema design for Data warehousing
Data warehousing 是為主要分析操作create和使用DB的practices。 這不同於為交易處理而設計的DB,例如用於銷售產品的電子商務應用程序或用於追踪這些產品的庫存管理系統。
分析資料存儲的類型
data warehousing這個名詞的使用廣泛通常包含一系列的資料儲存來支援資料分析使用。包含以下這些名詞
Data Warehouse 這些是企業組織的集中式且有組織的分析資料存儲庫
Data Marts 這些是專注於特定業務或部門的data warehosue的subset
Data Lake 這些是用於原始資料和輕度處理的資料結構化程度較低的資料存儲
Bigquery是被設計用來支援data warehouse and data marts。而Data Lake大都在GCP的 Cloud storage 與 Cloud Bigtable上實現。
Projects, Datasets, and Tables
從Highest levels來看, BigQuery data由三個層次組成,分別是projects, datasets與tables.
Projects是用於組織 GCP service和resources使用的High level結構。 API 的使用、計費和權限在project level進行管理。 從 BigQuery 的角度來看,Projects包含用於使用 BigQuery 的datasets以及角色和權限集。
Datasets存在於peojects中,是table和view的容器。 create datasets時,我們需要為該dataset指定在哪個region。 dataset的位置是不可變的。 對tables和view的acess是在datasets level定義的。 例如,對datset具有read access權限的user將有權acess dataset中的所有的table。
Tables是以row和column的集合,稱為columnar format也稱為Capacitor format,主要在支援壓縮和執行優化。 資料以 Capacitor format編碼後,寫入 Colossus distributed filesystem。
BigQuery tables受到以下限制:
- 在同一個dataset的table name必須是unique
- 當我們要copy table時,目的端要是同一個region(意思是copy不能跨region).
- 當我們要copy 多個table到同一個table時,所有source table的schema要是一樣的。
Table的column支援以下型態
Array: 零個或多個non-array type元素的ordered list
Bool: 布林代數 TRUE or FALSE
Bytes: 長度不一的binary data
Date: 日曆的日期
Datetime: 格式呈現會有 year, month, day, hour, minute, second 與subsecond;這種資料型態不會包含time zone
Numeric: 具有 38 位數整數的十進制數字
Float64: 具有小數分量的近似數值
INT64: 帶有小數部分的數值
Geography(標準SQL中的地理函數): 表示地球表面的點集或子集的點、線和多邊形的集合
String: 長度不一的字串;必須為UTF-8的編碼
Struct: 有順序類型field的容器
Time: 獨立日期之外的時間
Timestamp: 特定時間(奈秒級的精確度)包含time zone
以上這些數值通常都是atomic units或是scalar values, 但array / struct型態卻是比較複雜的巢狀式資料結構。
雖然BigQuery也支援join操作,通常data warehouse也支援join操作,像是SAP HANA(基於 fact tables and dimension table),不過我們將資料非正規化還是有一些效益存在。以這種非正規化的狀況來說,Bigquery就使用nested and repeated columns。
包含nested and repeated data的row被定義為 RECORD 資料類型,並在 SQL 中作為 STRUCT 來access。 基於object-based schema fformats的資料(例如 JavaScript object Notation(JSON) 和 Apache Avro files)可以直接載入到 BigQuery 中,同時保留其nested and repeated結構。
BigQuery 最多支持 15 層nested structure。
Clustered and Partitioned Tables
當我們可以最大限度地減少為查詢而scan的資料量時,BigQuery 最具成本效益。 BigQuery 沒有像Relational DB或Document DB之類的indexes,但它支援partition和cluster,這兩者都有助於限制Query期間scan的資料量。
Partitioning
Partitioning是將table劃分成segments也稱作partitions的過程。 通過對數據進行segment,BigQuery 可以利用有關partitions的metadata來確定應scan哪些partition以回應Query。 BigQuery 具有三種partition類型:
- Ingestion time partitioned tables
- Timestamp partitioned tables
- Integer range partitioned tables
當table是用ingestion time來劃分partition時,Bigquery是依每天來切成一個partition,所以每一天有一個自己的partition. 基於資料的timestamp存儲在名為 _PARTITIONTIME 的pseudo-column中,可以在 WHERE 子句中引用它以將scan限制在指定時間段內create的partitions。
Timestamp partitioned tables的劃分依據是根據table中的 DATE 或TIMESTAMP column。Partitiong是一天的資料。 對timestamp partition table的查詢不使用 _PARTITIONTIME,而是引用用於partition data的 DATE 或 TIMESTAMP column。 DATE 或 TIMESTAMP column中具有null value的row存儲在 __NULL__ partition中,日期超出允許範圍的row存儲在 名為 __UNPARTITIONED__ 的partition。
timestamp partition table比shared tables具有更好的性能,shared tables為每個data subset使用單獨的table,而不是單獨的partition。
Integer range partitioned tables 是基於column 的data type為INTEGER. Integer range partition的定義如下
- 一個INTEGER column
- partitions的range有start value
- partitions的range有end value
- partition內每個range的間隔
create的partition總數是end value和start value之間的差除以間隔大小。例如,start value 是0 , end value是500, 而間隔是25, 這樣就會是20個partition(500/25).與timestamp partitions tables一樣, __NULL__ 與__UNPARTITIONED__ partitions是來儲存那些row沒有符合條件一般正常partition的要求。
當我create以上三種任一種的partition. 我們可以指定對該table的任何query都必須包含基於partition structure的filter.
Clustering
在 Bigquery 中,Clustering是按其存儲格式對data進行排序。 對table進行cluster時,會指定一到四個column以及這些column的順序。 通過選擇最佳的column組合,我們可以將經常access的data並置在存儲中。 只有partation table 可support clustering,並且在經常使用filter或aggregations時使用它。
一旦create了cluster table, clustering column就不能更改。 clustering column必須是以下數據類型之一:
- Date
- Bool
- Geography
- INT64
- Numeric
- String
- Timestamp
partition與cluster這兩種方式在我們使用filter or aggregation query時都可以增強query的效率。
Querying Data in BigQuery
BQ支援兩種Query方式: interactive and batch query. Interactive query是會被立即執行的,而batch query則是會被queue起來並在resource available時才會執行。Intertative query則是預設的。
使用batch query的優勢在於資源是從共享資源池中提取的,batch query不計入concurrent rate limits,即 100 個comcurrent query。 Dry-run query僅估算掃描的資料量,也不計入該限制。 query最多可以運行六個小時,但不能更長。
當我們要run query時,在BQ就是一個Job. 運行Job需要有bigquery.jobs.create的這一個權限,這個權限可以被assign給 這些roles: bigquery.user, bigquery.jobUser, bigquery.admin. BQ也與Cloud spanner一樣 support parameterized query. BQ也使用相同的語法。參數被在符號@後被接續。
BQ也支援一次同時query多個table,這個方式在 FROM子句中在table name使用wildcard的方式。 這個wildcard的特徵是使用星號(*),例如我們有5個table的名稱是 jasonproject.jasondataset.jastable1 到 jastable5. 哪我們在FROM的子句就可以寫成如下
FROM ‘jasonproject.jasondataset.jastable1*’
wildcard query的方式只能用在tables,無法用在view and external tables.
External Data Access
BQ也可以access外部的resource,稱為federated sources. 我們可以create 一個外部的source reference來取代將資料載入BQ中。 BQ的external source可以是 Cloud bigtable/ cloud storage / Google drive.
這個外部的resource我們在BQ中可以create成臨時或永久的external tables. 永久的table代表我們會在BQ裡對這一個external resource有一個相對應的的dataset. 所以Dataset-level control就可以apply在這些tables. 如果是暫時性的table,哪BQ就會為這些table create一種只能存活24小時的dataset。暫時性table的好處是針對一次性的操作,像是載入資料到data warehouse裡。
以下是當我們需要對external table做查詢時在BQ裡所需要的權限:
- bigquery.tables.create
- bigquery.tables.getdata
- bigquery.job.create
從BigQuery對Cloud Bigtable做查詢
當我們要在BQ對Cloud bigtable裡的資料做查詢時,我們需要知道資料的位址,也就是URI。 URI會包含了該cloud bigtable的project ID與 instance ID還有table name. 當然在對bigtable做查詢時我們需要有以下權限
- bigquery.dataViwer 在dataset level或更高
- bigquery.user 在project level或更高來run query jobs
- bigtable.reader 的role, 這是為了能得取目標bigtable對其metadata read-only的權限
取決我們從BQ讀取bigtable資料效能的因素會有,有多少的row要被讀取,讀取的資料總量,與parallelization的level. 當讀取的bigtbale的資料是column families時,在BQ呈現的格式會是 一個array的column。
從BigQuery對Cloud storage做查詢
BQ對Cloud storage裡的檔案格式支援以下幾種:
- Comma-spearated values
- Newline-delimited JSON
- Avro
- Optimized Tow Columnar(OCR)
- Parquet
- Datastore exports
- Firestore exports
這些被讀取的資料位置可以是Regional/Milti-Regional/Nearline/Coldline storage.
而Cloud storage 對BQ的URI就是bucket name 與filename.
在權限的部分我們需要有storage.objects.et的權限。如果要query多個file就需要有wildcard — storage.objects.list的權限。
從BigQuery對Google drive做查詢
BQ對Google Drive裡的檔案格式支援以下幾種:
- Comma-spearated values
- Newline-delimited JSON
- Avro
- Google Sheets
Google Drive的URI是Google drive 中該檔案的file ID。在 Google Drive 中註冊和查詢外部data source需要 OAuth scope。 必須授予user查看作為外部data source的 Google Drive 文件的訪問權限.
BigQuery ML
BQ在一開始只能用standard SQL到現今加上Machine Leaning的功能。這讓我們可以直接在BQ裡建立ML models而不需要使用像Python, R, JAVA 等其他的外部語言來建模。
Bigquery支援以下ML演算法
- Linear regression
- Binary logistic regression
- Multiclass logistic regression
- K-means clustering
- TensorFlow models
在BQ中使用ML功能有以下六個基本步驟
- 針對這個model create一個dataset
- 檢查和預處理data以將其map為適合與 ML 演算法一起使用的形式
- 將資料劃分成training/validation/testing 這幾種dataset
- 使用training data 來create一個model(使用 CRETAE MODEL command)
- 使用ML.EVALUATE函數來評估model的precision, recall, accuracy和其他屬性
- 當model已經有足夠的training data來訓練,使用ML.PREDICT函數來apply到model
這只是初步的BigQuery ML初步的介紹,我們將會在後面有專篇介紹此一功能。
