設計Google Cloud的Data pipeline
這一篇我們會從設計模式的角度來看Data pipeline,外加一些其他不一樣的可供選擇的設計模式。同時我們也會介紹GCP有關於data pipeline服務,像是Dataflow, DataProc, Pub/Sub, Composer如何運用在Data pipeline。最後我們會稍微介紹如何將你地端機房的Hadoop cluster轉移到GCP上。
Data Pipeline 概觀
這是一個抽象的概念,是資料處理的連續過程從一個資料加工階段跳到下一個階段。Data pipeline 是基於directed acyclic graphs(DAGs-有向無環圖)被建模出來的。
一個graphs是指一群nodes它們之間的邊緣之間連結起來。directed graphs 是指在兩邊的邊緣之間有flow在流動,從一邊流動到另一邊。下圖展示三個node它們的邊緣之間有資料的流動。

但有時候graphs向上圖一樣一個點跳到下一個點(如下圖),有時也會跳回(loop)前一個點甚至loop回到自己身上。這種loop回到前一個邊緣(edge)就是我們所知道cyclic graphs(有循環的),而loop 就是cyclic.

然而在cyclic(也就是loop)在data pipeline是不被允許的。基於這個data pipeline的graphic就是有向無環圖。
上面的學術說法如果看不懂,我們可以就字面上來解釋 "有向無環圖"
有向:資料會順著同一個方向一直往後進行
無環:因為資料處理是一直往後的,所以它部會有循環
所以圖一才會是我們做data pipeline的標準做法
Data Pipeline各階段
在data pipeline DAG的pipeline 中的node呈現的是每個資料處理階段,哪edge就是呈現的就是node之間的資料流動。以下是在data pipeline 中四種型態的資料處理階段
- Ingestion
- Transformation
- storage
- Analysis
在整個data pipeline中每一個資料處理階段有時可能需要多個node才能處理完這個階段的工作。例如如果我們有五個data source 需要將資料送到data warehouse,這時我們在data ingestion就會有5個node。也不是每種data pipeline都需要完成上面四種階段的工作。例如我們有一個pipeline要ingest audit log資料,執行transformation然後將它以檔案型式放到Cloud storage但沒有要分析它。這些log資料可能永遠不會被使用(因為沒有稽核需求),但它會因為法規需求而要儲存它。資料放進clous storage之後就不會再次的執行其他的transformationc或其他形式的處理。不過還是會有一些極端的案例,有些的資料處理階段可能會是多於上所講的四個階段。
Ingestion
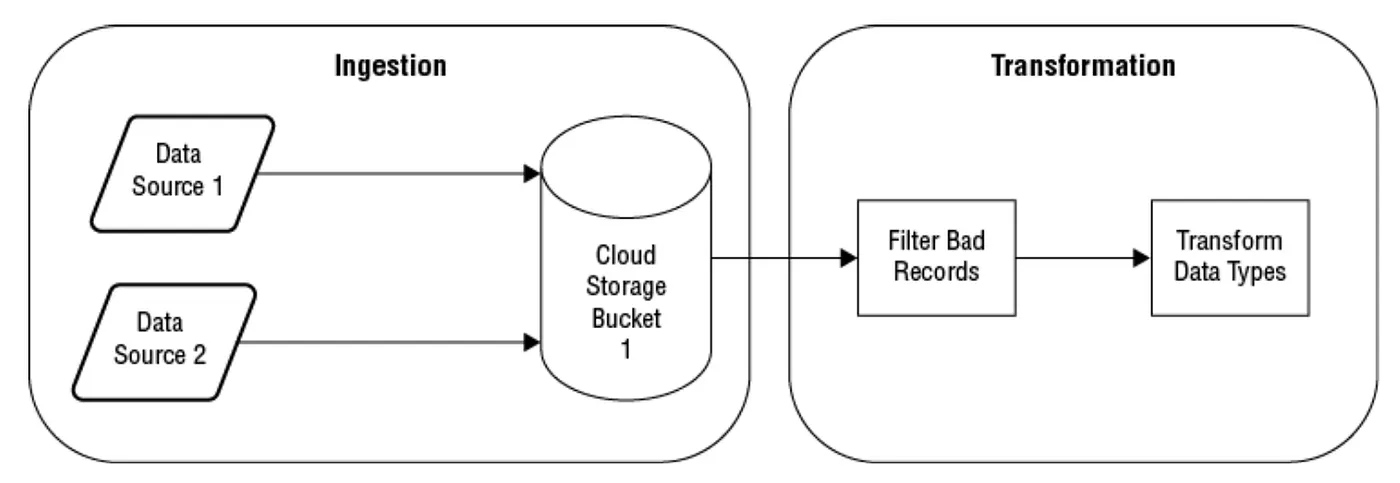
將資料倒進GCP中我們有streaming and batch mode兩種(如下圖範例)。
使用batch mode的方式我們通常是將一個或數個以上的檔案先copy到 Cloud storage中。通常有幾種方式將資料copye過去,你可以使用clous stroage專屬的command “gsutil” 或Transfer service 跟Transfer Appliance.
Streaming batch是只持續收到不斷新增的資料,通常會是single record或是 small batch record. Cloud Pub/Sub的Topic適合這樣的作業形式。

Transformation
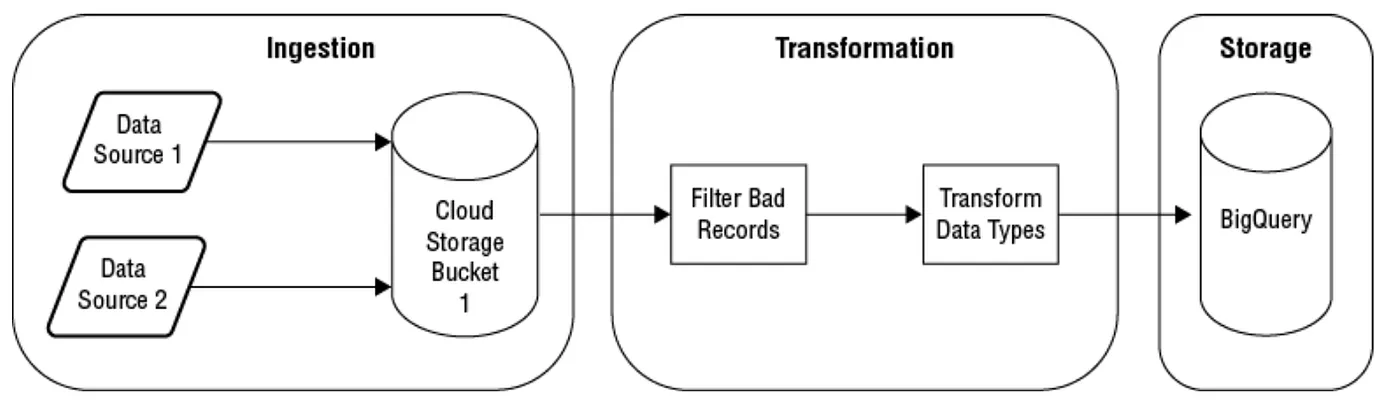
這是是指將來源端的資料結構轉換成適合在data pipeline 過程中適合儲存與分析這一階段的資料結構。以下是一些transformation的類型(如下圖範例):
- Converting data type, 例如將資料從文字現呈現轉換成日期格式來呈現。
- 填補原始資料中缺少的資料值,例如用預設值或推估值。
- Aggregating data, 例如將一台Server每五分鐘的Memory的使用率做平均計算。
- Filtering record, 例如不符合業務邏輯規則,像是我們的交易資料出現了未來日期的record.
- 資料擴增效應,我們join兩個不同的資料來源產生之後產生的效果。像是我們將員工資料的table跟銷售資料的table join再一起之後就知道誰的業績最好。
- 去除在資料集中我們不需要的column or attributes
- 加入(column or attributes)我們從輸入資料中衍生出來的data,例如我們要將公司某項商品的庫存每三個月做一次平均計算,並寫入成另一筆新的record。
GCP的Cloud Dataflow and Cloud Dataproc 經常使用在資料處理的transformation 階段(support batch and stream mode)。Cloud Dataprep 是使用在interactive view與資料分析的準備階段。
Storage
資料從Ingestion與transformation大都會經過儲存階段,有關詳細描述可參考建置與管理Google Cloud的儲存服務。
Analysis
這一階段有好幾種方式來實現,從使用簡單的SQL語法把report產生出來到使用Machine learning model training跟Data science analysis。
以Bigquery舉例,它一開是用SQL語法來分析資料。後來加上了一樣使用SQL語法來建立Machine Learning model的功能。
Data Studio是GCP的互動式reporting tool,功能是building reports與exploring data(一種有結構的,像是dimensional model). Cloud datalab,一種基於open source(Jupyter Notebook)的互動式的workbook。它是被使用在data exploration, Machine learning, data science, 與Virtualization.
大規模的Machine learning當要去access 支援Hbase interface的bigtable時可以使用有支援Spark machine learning libraries 的Dataproc服務。
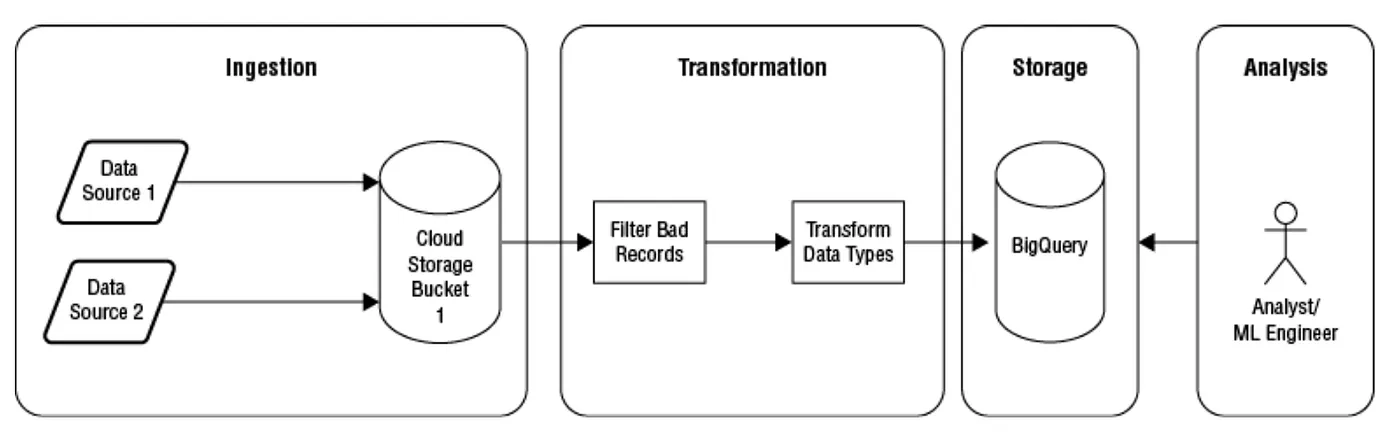
以上介紹的在data pipeline 四種基本階段的pattern 可以發展出根據不同的特徵而有不同種類的data pipeline。
Data Pipeline的種類
data pipeline的結構跟功能會因為根據你的使用場景而有不同的的型態。但一般來說會有以下以三種基本型態
- Data warehouse pipeline
- Stream processing pipeline
- Machine learning pipeline
Data warehouse pipeline
將多個資料來源集中到一處,而這種資料的結構通常都是Dimensioanl data model。這一類的Dimensional data的資料都是去正規化的,意思是他們跟RDBMS不一樣是不會遵守正規化的規則。而這種非正規化是需要你將資料從RDBMS轉過來時要刻意去做的,因為Data warehousing 是用來進行有效率的分析,如果沒有這麼做你的資源就會浪費在複雜的join語法與大量的DIsk I/O 操作上。你越把資料全部都集中在一個table上你所需要的join就越少。
從RDBMS系統中收集與重新結構資料通常需要多個步驟來完成。以下為一些data warehouse data pileline會用到common patterns :
- Extraction, Transformation, Load(ETL)
- Extraction, Load, Transformation(ELT)
- Extraction and Load
- Change data capture
以上這些通常都是batch processing pipeline, 但它們有一些streaming pipeline的特徵特別是Change data capture.
Extraction, Transformation and Load
這個流程是先將資料從一個或多個data source將資料提取出來。當有多個data source同時被提取時這一個流程中的所有動作都需要被協調。這是因為通常這類的資料提取動作都是time based的,所以重要的在於將資料提取出來時是要相同時間區間。例如,提取的流程可能是一個鐘頭跑一次而在下一個鐘頭提取資料前我們可能要將資料做完insert or modify的作業才能順利的進行下一次(下一個小時)的作業。
我們來看一種"貨品庫存"類型的Data warehousing的例子。某集團底下的所有子公司的DB都有產品(Product DB)與庫存數量(Inventory DB)的資料,而這個Data warehousing會提取所有子公司的這一類資料。產品會被定義成SKU(stock keeping unit)在Product DB。 Product DB會維護產品有關的所有詳細資料,向是產品描述,供應商,每個單位價格等。這個data warehouse會從這兩個DB提取資料 :
Product DB — 產品描述資訊
Inventory DB — Inventory資訊
假設有新的產品被加入了Product DB並有庫存資料在Inventory DB時, data warehouse就需要從這兩個DB 來update這一項資訊; 不過有可能會也有可能在取Inventory DB時會應對不到Product DB的描述性資料。
在ETL的pipeline中,資料從提取到落地到另一個DB中會經過transformation. 在過去 data warehousing的管理者會使用客製化的scripts或特定的工具來做這一類transformation的作業。不過這一類的作業都需要transformation code已經存在於scripts裡或當需要進行資料分析時,管理者需要有一些開發經驗才有辦法進行此類的工作。特定的工具可能還需要管理者去學習如何使用才能將SQL語法套進這個工具。
在GCP服務中transformation這個功能我們可以使用Cloud dataproc或Cloud dataflow. 使用Dataproc時我們寫的code可以是Spark or Hadoop support的語言。Spark使用的是 In-memory distributed data model來運作與分析資料。Spark program可以用Java, Scala, Python, R 跟SQL來完成。當使用Cloud dataproc時資料的transformation是基於Hadoop map reduce model或Spark 的distributed tabular data structure. 此外當你使用JAVA時,Hadoop提供了 一種稱為 pig的高階語言來運作資料。pig program compile到map reduce program中。
而在使用Cloud dataflow時,transformation 使用的是一種Apache Beam model的方式。它提供unified batch 跟streaming process model. Apache Beam被建模成pipeline 與有著明確support哪種pipeline構造,包含以下三個:
Pipelines : 執行資料操作的end-to-end 資料處理任務的封裝(encapsulation)。
Pcollection: A distributed dataset
PTransformation: 對資料的操作,像是grouping by , flattening, 跟data的partition.
Apache Beam program是用JAVA跟Python寫出來的。
當要寫資料到DB時,Cloud dataflow使用connector 連結到以下GCP的DB服務,像是Bigtable, Spanner, BigQuery.
Cloud dataproc中的ETL程序適合用來將你自己own的Hadoop or Spark轉移Cloud datarpoc中。而Cloud dataflow則適合用來開發新的ETL流程。因為它是serverless所以不需要管理這個服務的底層系統,它的processing model也是基於data pipelines的模式產生的。Cloud dataproc的 Hadoop與Spark平台是設計用來執行big data的分析流程,所以transformation可以在這個服務中執行。但是Cloud dataflow model則是基於Data pipelines產生的。
Extraction, Load and Transformation
這個過程跟ETL不太一樣的是,它是先進行資料擷取然後落地到目標地然後才進行Transformation. 這個方式有一些優於ETL的效益。
因為原始資料可以在沒有進行transformation保留一份。這個樣子可以讓data warehouse的管理者根據原始資料使用SQL語法進行基本的data quality check與收集特徵統計,像是有缺少幾筆的資料。
第二個好處是管理者可以直接用SQL語法進行data transformation. 這特別對SQL專家有幫助,因為不用像在ETL需要在transformation過程中需要有一點coding的經驗要求,只要會SQL語法就可以了。
Extraction and Load
這就是很簡單的搬移資料。而不做任何資料的任何變動,原來資料長甚麼樣就是怎麼樣。
Change data capture
這是指在source data有任何的資料異動,目的端馬上記錄異動了甚麼。這個有助於你想要知道在某一段時間內所有資料的異動,而不是跟上面三種一樣,只是去擷取當下DB資料最新的狀態。例如我們想知道某一樣商品過去三個月來每天的庫存數字,哪麼我們就需要知道在庫存總和這一欄每天數字的變化。
Data warehouse data pipeline通常都是以batch mode 方式在一定的週期性時間觸發運作。但如果資料是需要持續性被處理,我們就需要使用stream processing pipeline.
Stream processing pipeline
這是指不會中斷,持續性處理資料的模式。這種持續性的資料來源有很多種,例如
- IoT device,像是天氣的各項資料都是持續不斷傳送的
- 醫院的病人心跳資料
- 或是系統的Application 每15秒傳送效能資料來偵測系統的異常
我們以上面三個例子來看,如果以天氣資料來看也許需要用到即時的資料處裡與分析,因為天氣的變化需要長時間的資料收集。相反的病人的心跳就可能需要被及時的處理與分析,否則這個病人就可能陷入危急的狀況。Application 效能也是類似狀況,如果沒有及時的處理與分析可能系統就會有問題。從上述的例子來看絕大多數的stream data都是需要及時的處理與分析。
這種資料分析模式跟batch processing分析是不一樣的,從aggregate data, 尋找資料的異常模式,跟使用 charts/graphs來做視覺化資料。不同的點在於你group data的方式。在batch mode你是一次取得你所需要分析的全部資料。但這方法無法用在streaming data.
因為streaming data是持續性的,所以你只能挑選一段運作時間的data subsets。例如,你需要持續計算從IoT 感測器來每小時平均溫度,所以你選取的時間可能就是最新一小時傳送過來的資料。你也需會根據每小時平均溫度再次用四小時來平均上午或下午的平均溫度狀況。當然想要在某個地區計算每五分鐘的平均溫度當然也可以。
當我們要建立streaming data pipeline時,我們有以下因素需要考量:
- Event time and processing time
- Sliding and tumbling Windows
- Late-arriving data and watermarks
- Missing data
以上這些因素你在建立streaming data pipeline一定要考慮到的。
Event time and processing time
資料是依照資料的時間連續性依序被儲存的。假如有一組資料,其中資料 A到達的時間在資料B之前,哪麼依照時間邏輯這筆資料A的發生時間一定是在資料B之前。前面的描述隱含著一個重要但微妙的問題,哪就是你實際上是在stream processing處理中的兩個時間點的資料:
- Event time,這是指某件是發生時所產生的資料
- Processing time,這是指當資料被擷取進到我們目的端的endpoint的時間。Processing time可以被定為在整個data pipeline的每個階段的endpoint的到達時間,像是開始執行data transformation的時間。
當使用streaming data時,很重要的是一致地使用這些時間之一(Event time or processing time)來對stream 進行排序。以上面的例子(資料A與B)來說,data的Event time就是用來處理資料時間序列的方式。
假如資料的Event time時間序列跟到達endpoint的時間順序是一樣的話,哪排序自然就會一致。但大部分都會因為來源端或網路的關係Event time跟Processing time會經常不是同一個排序狀況。
Sliding and tumbling Windows
Windows指在stream的一組連續的數據點。Windows有固定的寬度與一種資料往前走的方式。資料往前走的資料組數小於Windows寬度稱為Sliding Window;如果資料組數大於Windows寬度就叫做tumbling windows。
讓我們看一下以下的一個範例(如下圖)
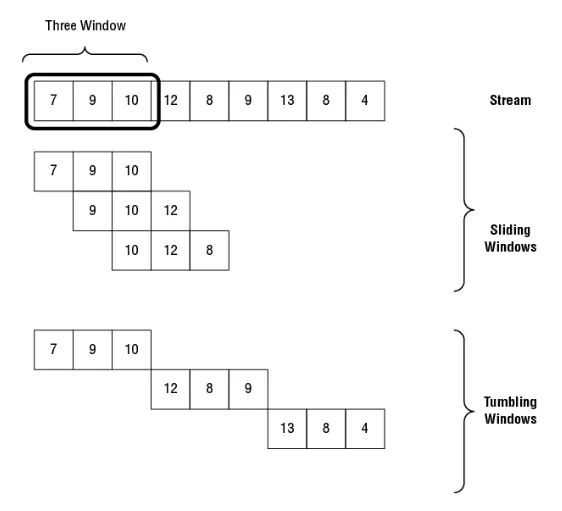
上圖我們看到有9個data point(7,9,10,12,8,9,13,8,4),每三個data point就是我們規定的Windows寬度,如 7,8,9。如果windows在這個stream移動到下一段哪就是會 9,10,12。再下一段就是10,12,8,每次都移動一個data point。這就是Sliding Window在stream前進的方式。Tumbling windows就每次前進的方式就是用Windows寬度來移動。
Sliding windows的使用時機是用在你要資料是怎樣被aggregate — 每次都隨間時間的推移對最後三個value做平均。Tumbling windows是用在你要在固定的時間間隔做平均。每次都是對三個數據做平均,而且每個data point都不會有被重複計算(上一個或下一個平均計算)。
Late-arriving data and watermarks
在處理streaming data,尤其是時間序列資料時,我們必須決定等待data到達的時間。 如果我們希望data大約每分鐘到達一次,我們可能願意為遲到的data等待三到四分鐘。 例如,如果streaming data來自醫療IoT device,並且我們希望盡可能記錄所有data point,那麼我們可能願意等待比使用data更新stream chart更長的時間。 在這種情況下,我們可能決定在兩分鐘後顯示最後三個data point的移動平均值,而不是等待更長時間。
當我們等待遲到的data時,我們將不得不在執行stream processing operation之前維護一個緩衝區來暫存data。 考量一個use case,您將一個stream作為輸入並輸出最後三分鐘的平均值stream。 如果我們收到了一分鐘前和三分鐘前但不是兩分鐘前的data,則必須將已到達的兩個data point保留在緩衝區中,直到我們收到兩分鐘前的data point,或者直到我們等待同樣長的時間 盡後將兩分鐘的data point視為lost掉的data。
在處理stream時,我們需要能夠假設在某個特定時間之前生成的data不會到達。 例如,我們可以決定任何遲到 10 分鐘的data都不會被ingest到stream中。 為了幫助stream processing applications,我們可以使用wantermarks的概念,它基本上是一個timestamp,表示不會在stream中出現早於該timestamp的data。
就目前所知,我們可以將stream視為有限且完整的data windows,就像我們以batch mode處理的dataset一樣。 在那種情況下,windows只是small batch的data,但實際情況更為複雜。 watermarks表示data延遲的邊界。 如果data point到達太晚以至於其event time發生在watermarks的timestamp之前,則stream將忽略它。 但這並不意味著我們應該完全忽略它。 系統狀態的高精確度會反映到將要包括遲到的data。
我們可以通過修改Ingest、transformation和存儲data的方式來適應遲到的data並提高精確性。
Hot path and Cold path ingestion
我們到現在只考量到了streaming-only ingestion process. 這個通常稱為Hot Path ingestion. 它反映的是我們盡可能用的是最新並且是可用的資料。我們可能會面臨失去準確性的潛在風險,從而提高回報data的及時性。
有許多use case顯示這種tradeoff是可以接受的。例如,進行限時搶購的在電商希望及時了解銷售資料,即使資料可能略有偏差。 進行限時搶購的銷售專業人員需要這些資料來調整銷售參數,並且近似但不一定準確的數據滿足他們的需求。
但的財務部門的會計人員有一種不同的需求。 他們不需要立即獲得資料,但需要完整的資料。 在這種情況下,即使資料太晚而無法在stream processing piepline中使用,它仍然可以寫入DB,在那裡它可以與包含在stream dataset集中的資料一起包含在報告中。 這條從ingestion到持久存儲的路徑稱為Cold path ingestion(如下圖)。

而將stream 與batch的 processing pipeliner結合起來並加上一些特定的步驟就可以變成Machine Learning pipeline。
Machine Learning pipeline
ML piepline與data warehouse pipeline的某些步驟相同,但還是有一些ML pipeline才獨有的步驟,以下是ML pipeline的步驟
- Data ingestion
- Data preprocessing(在data warehouse pipeline 稱作transformation)
- Feature engineering(ML自己獨有的transformation)
- Model training and evaluation
- Deployment
在Data ingestion這一階段所用的工具/服務跟data warehouse pipeline是一樣的。cloud stroage是儲存資料的地方,而Cloud Pub/Sub Topic 則是streaming data的ingestion.
而Cloud dataproc 與 Cloud dataflow則是用在程序化的data preprocessing. 而Cloud dataprep大多則是用在資料的ad hoc與 interactive preparation. Cloud Dataprep 在處理新的dataset時特別有用,可以根據各種屬性的value 的distribution、遺失資料的頻率以及發現其他資料質量問題來解讀資料。 理想情況下,一旦對來自特定來源的資料所需的preprocessing種類有了很好的認知,我們就會將該邏輯編碼到 Cloud Dataflow 流程中。
Feature engineering是一種ML實踐,其中將新的attributes引入dataset。 新的attributes源自一個或多個現有attributes。 有時,新的attributes的計算相對簡單。 在 IoT data stream發送天氣資料的情況下,我們可能想要計算溫度與壓力的比率以及濕度與壓力的比率,並將這兩個比率包含為新的attribute或特徵。 在其他情況下,Feature engineering可能更複雜,例如執行快速傅立葉變換以將數據流映射到頻域。
GCP pipeline components
GCP有著以下服務用在pipeline中
- Cloud Pub/Sub
- Cloud Dataflow
- Cloud Dataproc
- Cloud Composer
使用以上這些服務你可以組合出不同的processing model.
Cloud Pub/Sub
這是一個real-time的message 服務,它可以support push and pull的subscription model. 是全託管式服務,意味著你不用管理底層的機器。它會根據工作負載自動的執行scale 跟partition。
Working with message queue
這是使用在分散視系統中,在pipeline對服務decouple。這允許一個service產生比consuming service可以處理的更多的output,而不會對consuming service產生不好的影響。 當一個process的工作量激增時,這尤其有用。
使用 Cloud Pub/Sub 時,我們會create一個topic,這是用於組織message的邏輯結構。 create topic後,我們可以create對該topic的subscrption,然後向該topic發布message。 subscrption是一種邏輯結構,用於通過consuming process來組織message的接收。
當message queue接收message中的data時,它被視為publication event。 發布後,push subscrption將message傳送到endpoint。 一些常見類型的endpoint是 Cloud Functions、App Engine 和 Cloud Run 服務。 當我們希望consuming application控制何時從topic中檢索message時,將使用pull subscriptions。 具體來說,通過pull subscriptions,我們可以發送請求 N 條message的request,Cloud Pub/Sub 會使用next N 個或更少的message進行回應應。
可以在console或command 中create topic。 唯一需要的參數是topic ID,但我們也可以指定topic是應該使用 Google 還是Google-managed key or a customer-managed key進行加密。 create topic的command是 gcloud pubsub topics create; 例如:
gcloud pubsub topices create jason-kao-1
接下來就是要create subscriptions,一樣可以在console or command 進行。但在這邊我們需要將subscription 與 topic進行配對,範例如下
gcloud pubsub scriptions create — topic jason-kao-1 jasonkao-subscr-1
可以使用 API 和client libraries以及 gcloud 命令將message寫入。 寫入message的process稱為publishers或procuders; read message的服務稱為subscribers或consumers。
client libraries可用於多種語言,包括 C#、Go、Java、Node.js、PHP、Python 和 Ruby。 (在您閱讀此篇文章時可能已經添加了其他語言。)Cloud Pub/Sub 還支持 REST API 和 gRPC API。 command-line工具可用於測試你publish和consume來自topic 的message的能力。 例如,要publish帶有string的message,我們可以發出以下command:
gcloud pubsub topic publish jason-kao-1 — message “jason kao”
此命令將message insert或publish到 jason-kao-1 topic,該message可通過subscriptions讀取。 default情況下,當create一個topic時,它是作為請求subscriptions完成的。 從topic讀取message的 gcloud 命令是 gcloud pubsub subscriptions; 例如:
gcloud pubsub subscriptions pull — auto-ack jason-kao-1
auto-ack flag 表示message應該被自動確認。 確認向subscriptions表明message已被讀取和處理,以便可以將其從topic中刪除。 當一條message被發送但在它被確認之前,該message被認為是未完成的。 當message未發送給該subscriber時,它不會傳遞給同一subscriptions的另一個subscriber。 如果message未完成的時間大於subscriber確認message所允許的時間,則它不再被視為未完成,並將被傳遞給另一個subscriber。 subscriber確認message的時間可以使用 ackDeadline 參數在subscriptions command中指定。 message最多可以在topic中停留 7 天。
Pub/Sub不保證message接收順序與發布順序相同。 此外,可以多次傳遞message。 由於這些原因,我們的處理邏輯應該是; 也就是說,該邏輯可以應用多次並仍然提供相同的output。 一個簡單的例子是給一個數字加上 0。 不管你給一個數字加多少次 0,結果都是一樣的。
一個更有趣的例子,考慮一個接收message stream的過程,這些message具有identifiers和過去一分鐘系統中發生的特定類型事件的數量的計數。 時間表示為白天後跟午夜過後的分鐘數,因此每天的每一分鐘都有唯一的identifiers。 stream processing system需要保持每天運行的累計事件總數。 如果執行aggregation的process只是將它收到的每條message的計數添加到運行總數中,那麼重複的消息將多次添加它們的計數。 這不是idempotent操作。 但是,如果該過程保留接收數據的所有分鐘的列表,並且只添加之前未接收到的data point的計數,則該操作將是idempotent的。
如果我們需要保證只處理一次,就要使用 Cloud Dataflow PubsubIO,它會根據message ID 進行重複資料刪除。 Cloud Dataflow 還可用於確保按順序處理message。
Open source選擇: Kafka
Pub/Sub如同之前說的是一種全託管式的服務。但是你也可以選擇自建這一種服務: Apache Kafka. Kafka 用於publish 和subscribe message stream,並以容錯方式可靠地存儲message。
Kafka是運行在有一堆Server的Cluster 架構上。跟Kafka互動的方式是使用一下四種API
- Producer API
- Consumer API
- Streams API
- Connector API
Producer API是用來publish message的,在kafka稱作parlance。Consumer 支援topic subscription. Streams API 支援將data stream轉換為output stream的stream processing operation。 Connector API 用於使 Kafka 能夠與現有Application一起工作。
若是你原本在地端機房或是自建Kafka想要轉到託管式服務,哪麼就可以選用Cloud Pub/Sub. 若是要將兩個系統連結起來你可以使用CloudPubSubConnector或是Kafak connector. CloudPubSubConnector是GCP在維護的open source tool。
Cloud Dataflow
這可以使用在batch and stream 流程服務。Cloud dataflow是建立data pipeline的核心元件。過去,開發人員通常會create batch 或stream processing pipeline— — 例如,Hot path 和單獨的batch processing pipeline; 也就是cold path。 Cloud Dataflow 的pipeline是使用 Apache Beam API 編寫的,該 API 是組合stream和batch processing的模型。 Apache Beam 在data pipeline中加入了 Beam runners; Cloud Dataflow runners通常用於 GCP。 Apache Flink 是另一種常用的 Beam runner。
Cloud dataflow不需要去設定底層的instance或cluster — 它是no-ops 服務。Cloud dataflow的運行範圍是region level的。它使直接整合Cloud Pub/Sub, BigQuery, 還有Cloud ML engine. Cloud dataflow也可以整合Bigtable跟Apache kafka.
你使用 Cloud Dataflow 的大部分工作是使用 Apache Beam 支持的一種語言(目前是 Java 和 Python)對進行轉換編碼。
Cloud dataflow Conecpt
不論是cloud dataflow或是Apache Beam model都是基於以下幾個重要概念構築而成的
- Pipelines
- PCollection
- Transforms
- ParDo
- Pipeline I/O
- Aggregation
- User-defined functions
- Runner
- Triggers
Windowing 概念跟watermarks也是很種重要的概念,我們在本篇文章的稍早有提及到。
Cloud Dataflow 中的pipeline是應用於來自source data的一系列的資料運算。 每個運算都會發出計算結果,這些結果成為pipeline中下一個運算的input。 pipeline代表可以重複運行的工作。
PCollection abstraction是一個dataset,它是運行pipeline作業時使用的data。 在batch processing的情況下,PCollection 包含一組固定的data。 在stream processing的情況下,PCollection 是沒有邊界的。
Transforms是將input data映射到某些output的操作。 Transforms對作為輸入的一個或多個 PCollection 進行操作,並且可以產生一個或多個輸出 PCollections。 這些操作可以是數學計算、data類型轉換和data分組步驟,以及執行讀寫操作。
ParDo 是一種 parallel processing operation,它在 PCollection 中的每個element上運行用戶指定的函數。 ParDo 平行處理轉換data。 ParDo 從main PCollection 接收input data,但也可以通過使用side input從其他 PCollection 接收附加的input。 side input可用於執行join。 一樣的,雖然 ParDo 生成main output PCollection,但可以使用side output輸出其他Collections。 當想要額外的processing path時,side output特別有用。 例如,side output可用於未通過某些驗證檢查的data。
Pipeline I/O是將data從source端讀取到pipeline 並將data 寫入到Sink中。
Aggregation是從多個input valus計算結果的過程。 Aggregation可以很簡單,例如計算一分鐘內到達的message數量或對過去一小時內收到的values of metrics求平均值。
User-defined functions是User指定的用於執行某些操作的code,通常使用 ParDo。
Runner是將pipeline作為作業執行的software。
Triggers是確定何時發出aggregation結果的函數。 在batch processing作業中,當處理完所有data時會發出結果。 在對stream進行操作時,我們必須在stream上指定一個Window來定義有bounded subset,這是通過配置Window來完成的。
Job and Templates
Job是 Cloud Dataflow 中的execiting pipeline。 有兩種執行作業的方式:傳統方式和templates方式。
使用傳統方法,開發人員在development環境中create pipeline並從該環境運行作業。 templates方式將development與stage和Production分開。 使用templates方法,開發人員仍然在development環境中create pipeline,但他們也創建了一個templates,這是一個配置好的job specification。 specification可以具有在用戶運行templates時指定的參數。 GCP內建了許多templates,我們也可以create自己的template。 有關 GCP提供的templates,可以參考下圖。

在選定好templates之後你可以指定特定的參數,像是source and sink specification(如下圖-一個word count的templates)

Job可以用command-line或API的方式來驅動。例如你要用command-line來啟動一些Job, 如下範例
gcloud dataflow jobs run jason-job-1 \
— gcs-location gs://your/cloud/stroage/bucket/path/word-count-path
這個coomand 會用word count這個template 執行一個工作名稱為jason-job-1的Job 並把結果放在你指定的bucket.
Cloud dataproc
這是一個託管式的Hadoop and Spark服務,你必須要先預先設定Cluster相關的規格。典型的 Cloud Dataproc Cluster配置了 Hadoop 生態系統的常用component,包括以下內容:
- Hadoop:這是一open source源的大數據平台,使用 map reduce 模型進行分散式處理作業。 Hadoop 將intermediate操作的結果寫入HD。
- Spark:這是另一個運行分散式Application的開源大數據平台,但是將資料寫入memory中而不是像 map reduce 一樣將操作的結果寫入HD。
- Pig:這是一個complier,它用高階語言生成 map reduce 程序,用於呈現對data的操作。
- Hive:這是一個建立在 Hadoop 上的data warehouse服務。
當使用Cloud dataproc時,你必須知道如何管理data storage, 配置 cluster, 跟sumbit jobs.
Cloud Dataproc 允許使用“臨時(ephemeral)”cluster,其中可以create一個大型cluster來run jobs,然後在job結束後刪掉整個cluster 以節省成本。
Cloud dataproc的資料管理
在地端機房運行 Hadoop 時,你將data存儲在 Hadoop cluster上。 該cluster使用 Hadoop 分佈式文件系統 (HDFS),它是 Hadoop 的一部分。 當你使用自己的硬體來實現 Hadoop cluster時,這樣做是合理的。 但在cloud platform中,相對擁有一個長期運行的單一個 Hadoop cluster,在Cloud dataproc的使用方式,你會針對每一個job啟用一個dataproc cluster。然後在job完成後就關閉該cluster以節省長時間運行的費用。
這是比在cloud platform中維護長時間運行的cluster更好的選擇,因為 Cloud Dataproc cluster大概會在 90 秒內啟動,因此在空閒時關閉cluster幾乎沒有什麼障礙。 由於我們在使用 Cloud Dataproc 時傾向於使用 ephemeral cluster,因此如果我們想在此處使用 HDFS,則每次啟動cluster時都必須從 Cloud Storage 複製data。 更好的方法是直接使用 Cloud Storage 作為data storage。 這節省了必須將data複製到cluster的時間和成本。
配置一個Cloud Dataproc cluster
Cloud Dataproc cluster由兩種類型的node組成:master node和worker node。 master node負責分配和管理工作負載分配。 master node運行一個名為 YARN 的系統,它代表 Yet Another Resource Negotiator。 YARN 使用有關每個worker node上的工作負載和資源可用性等資訊來確定Job要跑在那些worker node上。
create cluster時,我們將指定許多配置參數,包括cluster名稱以及用於create cluster的region和zone。 cluster可以在single node上運行,這適合用在Development。 它們還可以與一個master node和一定數量的worker nodes一起運作。 這稱為標準模式。 HA模式使用三個master node和一定數量的工worker nodes。 我們可以為master node和worker node指定機器配置,它們不必是相同規格的。 Worker 節點可以包含一些搶占式(preemptible)機器,儘管 HDFS storage不在搶占式worker node上運作,這是使用 Cloud Storage 而不是 HDFS 的另一個原因。
通過指定位於 Cloud Storage 存bucket中的scripts文件,可以在create cluster時run 初始化腳本。
可以使用console或command-line create cluster。 例如,以下 gcloud dataproc clusters create command將使用default configuration 創建cluster:
gcloud dataproc clusters create jason-cluster-1
create cluster後,可以對其進行scale up or down。 只有worker node的數量可以改變 — — master node是固定的。 我們可以使用 gcloud dataproc clusters update command手動擴展cluster的大小,如下所示:
gcloud dataproc clusters update jason-cluster-1 \
— num-workers 10 \
— num-preemptible-workers 20
上面的command 將擴展cluster以運行 10 個常規worker nodes和 20 個搶占式worker nodes。
Cloud Dataproc 還通過為cluster create autoscaling policy來support autoscaling。 autoscaling policy 是在 YAML file並包含參數,例如
- MaxInstances
- scaleUpFactor
- scaleDownFactor
- cooldownPeriod
Autoscaling的工作原理是在每個cooldownPeriod結束時檢查有關memory使用的 Hadoop YARN metrics。 add或remove的node數量由當前數量和scaling factor決定。
Submitting a Job
Job的執行可以透過 API, gcloud command跟console. gcloud command的範例如下:

上面的command 是將工作名稱為pyspark 的job submit到 名稱為pde-cluster-1的cluster中執行。這個cluster 的地點是 us-west-1並且執行的腳本位於 pde-exam-cert/dataproc-scripts的cloud storage bucket的 analysis.py.
通常Dataproc cluster與要存取資料的Cloud storage bucket要位於同一個region. 另外若你要cluster的node要有比較好的 I/O效能就需要選擇SSD的硬碟而非HDD。
Cloud Composer
Cloud Composer 是一種實施 Apache Airflow 的託管服務,用於調度和管理workflow。 隨著pipeline變得更加複雜並且在發生錯誤時必須具有彈性,擁有一個管理workflow的框架變得更加重要,這樣我們就不會重寫code來處理錯誤和其他異常情況。
Cloud Composer 可自動安排和監控工作流。 工作流是使用 Python 定義的,並且是有向無環圖。 Cloud Composer 內置了與 BigQuery、Cloud Dataflow、Cloud Dataproc、Cloud Datastore、Cloud Storage、Cloud Pub/Sub 和 AI Platform 的整合。
在我們使用 Cloud Composer 運作workflow之前,我們需要在 GCP 中create一個環境。 環境在會跑Google Kubernetes Engine 上,因此我們必須指定node數量、位置、機器類型、硬碟大小以及其他node和網路配置參數。 我們還需要create 一個 Cloud Storage bucket。
遷移Hadoop and Spark到GCP
當我們要將Hadoop and Spark cluster遷移到GCP時,有以下事項需要列在我們的migration plan
- 遷移的data
- 遷移的Job
- 遷移的 Hbase 到 bigtable
我們在遷移時也需要同時轉換我們的觀點,如何地有效使用Cluster. 我們位於地端機房的Cluster通常都是不會停機且持續在運行多個Job的狀況。它們通常需要付出高額的管理成本。而在GCP的觀念中,我們應該用的是針對每一個Job使用一個專用但是是臨時性(ephemeral)的cluster. 這個方式讓我們減少地端cluster配置的複雜性並減少費用。
Hadoop 和 Spark 遷移可以增量進行,特別是因為我們將使用為特定job配置的臨時的cluster。 第一步是將一些data遷移到 Cloud Storage。 然後,我們可以部署臨時cluster來跑使用這個data的作業。 最好從低風險job開始,這樣我們就可以了解使用 Cloud Dataproc 的詳細運作方式。
在將某些job和data遷移到 GCP 時,可能需要保留on-premises cluster。 在這些情況下,我們必須在兩個環境之間保持data同步。 計劃實施workflow以保持data同步。 我們應該有辦法確定哪些job和data移動到cloud,哪些留在on-premises。
將 HBase DB遷移到 Bigtable 是一個很好的做法,它提供了一致的、可擴展的性能。 遷移到 Bigtable 時,我們需要將 HBase table export到sequence file並將其複製到 Cloud Storage。 接下來,我們必須使用 Cloud Dataflow import sequence file。 當要遷移的data大小大於 20 TB 時,使用 Transfer Appliance。 當大小小於 20 TB 且至少有 100 Mbps 的網路頻寬可用時,則推薦使用 Hadoop 分散式 copy命令 distcp 來copp data。 此外,重要的是要知道傳輸data需要多長時間,並擁有一種機制來使on-premises與 Cloud Storage 中的data保持同步。
