使用 TFX、Kubeflow pipeline和 Cloud Build 的 MLOps 架構
此篇出自Google Cloud的 Cloud Architecture Center。主要講述如何使用TXF(TensorFlow Extended) library的ML整體架構,並且在CI/CD還有CT的原則下使用 Cloud Build與kubeflow pipeline。
這篇文章適用於希望調整其 CI/CD practices以將 ML 解決方案遷移到 Google Cloud 上的生產環境,並希望幫助確保其 ML pipeline的quality、maintainability和adaptability的資料科學家和 ML 工程師。
這篇會包含以下的一些主題:
- 了解ML中的CICD與自動化
- 使用TFX來設計一個整合式的ML pipeline
- 使用kubeflow pipelines 來編排(orchestrate) 與自動化 MLpipeline
- 使用Cloud build來建立一個具有CI/CD系統的 ML pipeline
MLOps
要將 ML 系統整合到production環境中,我們需要編排(orchestrate) ML pipeline中的步驟。 此外,我們需要自動執行pipeline以持續訓練模型。 要嘗試新的想法和features,我們需要在pipeline的new implementations中採用 CI/CD practices。 以下部分對 ML 中的 CI/CD 和 CT 做了一些High level的overview。
ML pipeline的自動化
在某些use cases中,訓練、驗證和部署 ML 模型的手動過程其實就足夠了。 如果我們的團隊僅管理幾個不用重新訓練或不經常更改的 ML 模型,哪這種手動方法還是有效。 然而,在實踐中,模型在現實世界中部署時經常會掛掉,因為它們無法適應環境是動態的或能看見資料動態的變化。
為了讓我們的 ML 系統適應這些變化,我們需要應用以下 MLOps 技術:
- 自動執行 ML pipeline以根據新資料重新訓練新模型以擷取任何新的模式。
- 建立CD系統以頻繁部署整個 ML pipeline的new implementation。
我們可以自動化 ML production pipeline,以使用新資料重新訓練我們的模型。 我們可以by on demand、on schedule、根據新資料的可用性、模型效能下降、資料統計屬性的顯著變化或基於其他條件等來觸發pipeline。
CI/CD pipeline與 CT pipeline的比較
新資料的可用性是重新訓練 ML 模型的一個觸發點。 ML pipeline的 new implementation(包括 new model architecture/feature engineering/hyperparameters)的可用性是重新執行 ML pipeline的另一個重要觸發因素。 ML pipeline的這種new implementation充當模型預測服務的新版本,例如,具有用於online serving的 REST API 的microservice。兩種情況的區別如下:
- 為了使用新資料訓練新的 ML 模型,需要執行之前部署的 CT pipeline。 但沒有部署新的pipeline或component; 在pipeline的末端只提供新的預測服務或新訓練的模型。
- 為了使用new implementation訓練新的 ML 模型,需要通過 CI/CD pipeline部署新的pipeline。
要快速部署新的 ML pipeline,我們需要設置 CI/CD pipeline。 這個pipeline負責在new implementation是可用並被批准用於各種環境(例如development, test, staging, pre-production, canary,production)時自動部署新的 ML pipeline和component。
下圖展示了 CI/CD pipeline和 ML CT pipeline之間的關係。

上圖的pipeline的output如下:
- 如果是implementation,有效的 CI/CD pipeline將部署新的 ML CT pipeline。
- 如果是新資料,有效的 CT pipeline將提供新的模型預測服務。
設計一個 TFX-based的ML系統
以下部分討論如何使用 TFX設計一個整合式的 ML 系統,為 ML 系統設置 CI/CD pipeline。 儘管有多種建置 ML 模型的框架,但 TFX 是一個整合的 ML 平台,用於開發和部署production ML 系統。 TFX pipeline是實現 ML 系統的一系列components。 這個TFX pipeline專為可擴展的高性能 ML 任務而設計。 這些任務包括建模、訓練、驗證、serving inference和部署管理。 TFX的key libraries如下:
- TensorFlow Data Validation (TFDV):用於檢查資料中的異常
- TensorFlow Transform (TFT):用於資料的preprocessing與feature engineering
- TensorFlow Estimators and Keras:用於建置與訓練ML模型
- TensorFlow Model Analysis (TFMA):用於ML模型的評估與分析
- TensorFlow Serving (TFServing):將 ML 模型作為 REST 和 gRPC API 來提供服務。
TFX ML system overview
下圖由各種 TFX libraries整合成ML 系統。
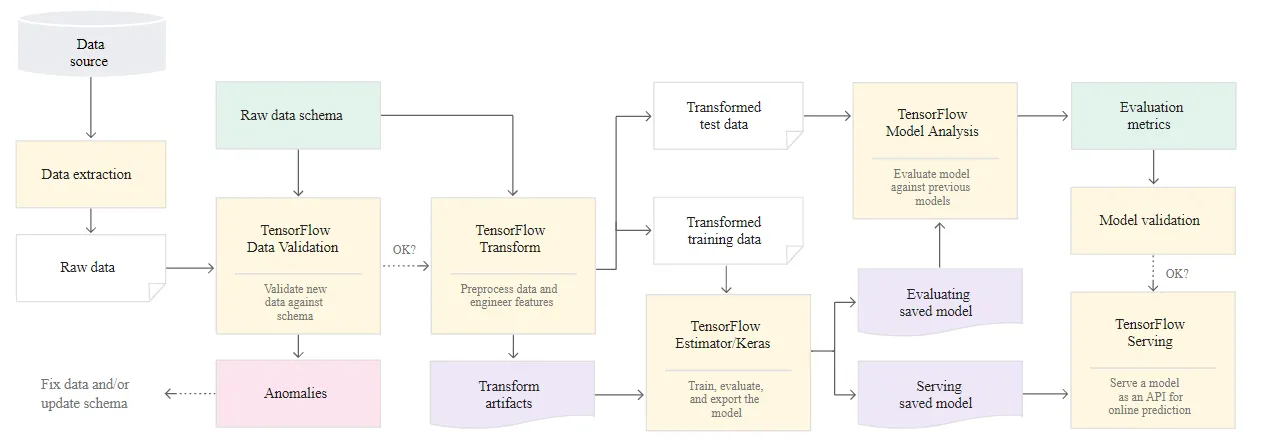
上圖顯示了一個典型的TFX-based ML system. 以下的步驟說明可以是手動或是自動的pipeline:
- Data ertraction:從data source中提取新的training data。此步驟的output是用於訓練和評估模型的data file。
- Data validation:TFDV 根據預期(raw)data schema來驗證資料。data schema是在開發階段、系統部署之前建立和修正的。data validation步驟檢測與data distrubution和schema skews相關的異常。此步驟的output是z否異常和是否執行downstream steps的決定。
- Data transformation:資料經過驗證後,通過使用 TFT 執行data transofmration和feature engineersing操作來拆分資料並為 ML task做好準備。此步驟的output是用於訓練和評估模型的data file,通常轉換為 TFRecords 格式。此外,產生的transformation artifacts有助於構建模型input和在訓練後export的模型。
- Model training and tuning:要implement和training ML 模型,使用 tf.estimator 或 tf.Keras API 以及上一步驟產生的已轉換過的資料。要選擇export最佳模型的參數設置,我們可以使用 Keras tuner(Keras 的hyperparameter tuning library),也可以使用 Katib 等其他服務。此步驟的output是一個用於評估的已導出的模型,以及另一個用於模型online serving以進行預測的模型。
- Model evaluation and validation:當模型在訓練步驟後export時,它會在text dataset上進行評估,以使用 TFMA 評估模型品質。 TFMA 從整體上評估模型品質,並確定資料模型的哪個部分沒有執行。這種評估有助於保證模型只有在滿足品質標準時才會被提升服務。該標準可以包括在各種data subsets上的合理效能,以及與先前模型或benchmark model相比的改進效能。此步驟的output是一組效能指標以及是否將模型提升到生產環境的決定
- Model serving for prediction:在驗證新訓練的模型後,將其部署為microservice,以使用 TensorFlow Serving 提供online prediction service。此步驟的output是已訓練並部署在生產環境的ML 模型。我們可以通過將經過訓練的模型存儲在model registry來替換此步驟。隨後啟動了一個單獨的模型服務 CI/CD 流程。
Google Cloud的 TFX ML system
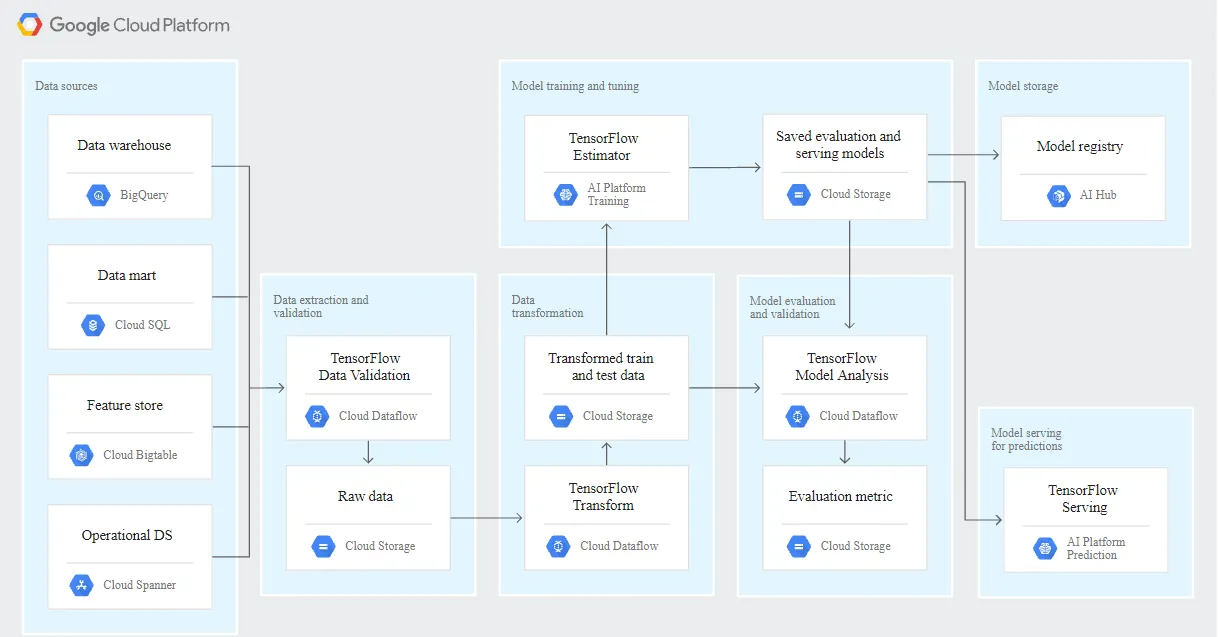
在生產環境中,system component必須在可靠的平台上大規模運作。 下圖顯示了 TFX ML pipeline的每個步驟如何使用 Google Cloud 上的託管服務運作,從而確保大規模的敏捷性、可靠性和效能。
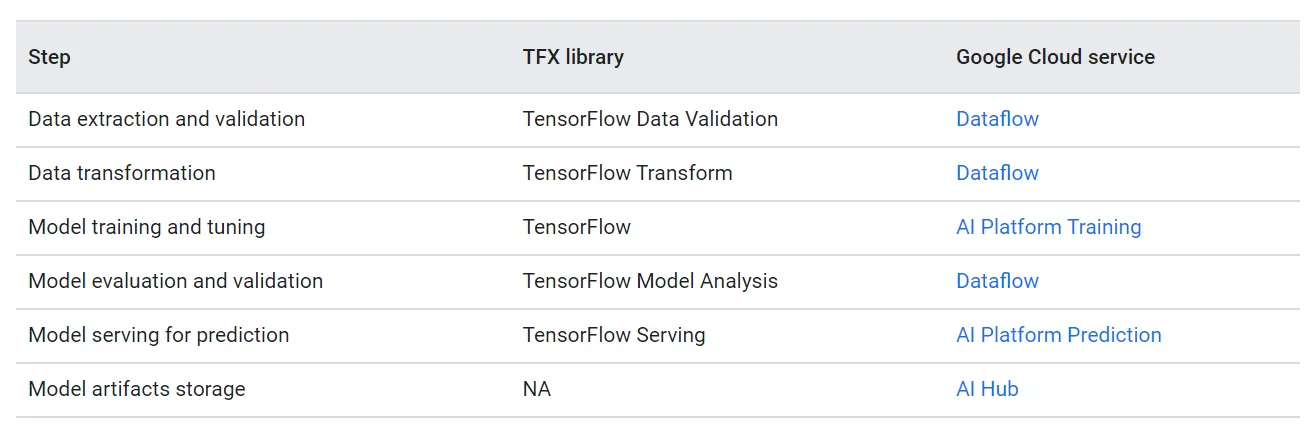
下表描述了GCP的服務對應整體TFX-based ML system
Dataflow 是一項全託管、serverless的服務,用於在 Google Cloud 上大規模運作的 Apache Beam pipeline。 Dataflow 用於擴展以下流程:
- 計算統計資料以驗證傳入dataflow的資料。
- 執行data preparation and transformation。
- 在大型資料集上評估模型。
- 計算評估資料集不同方面的metrics。
Cloud Storage 是一種用於binary large objects的high available和durable storage。 Cloud Storage 託管在 ML pipeline執行過程中產生的artifacts,包括以下:
- 資料是否異常
- 已轉換的資料與artifacts
- export已經訓練好的model
- 模型的評估指標
AI Hub 是一個企業等級的託管repository,用於discovering、sharing和reusing的AI和 ML 資產。 要存儲經過訓練和驗證的模型及其相關metadata,我們可以使用 AI Hub 作為model registry。
AI Platform 是一項託管服務,用於大規模訓練和服務 ML 模型。 AI Platform Training 不僅支援 TensorFlow、Scikit-learn 和 XGboost 模型,還支援使用客戶自己的容器在任何框架中implement的模型。 此外,還提供可擴展的、基於貝葉斯(Bayesian)優化的hyperparametering tuning。 經過訓練的模型可以作為具有 REST API 的microservice部署到 AI Platform Prediction。
使用 Kubeflow pipeline 編排 ML system
本篇介紹瞭解如何設計基於 TFX 的ML系統,以及如何在 Google Cloud 上大規模運行系統的每個component。 但是,我們需要一個orchestrator來將系統的這些不同compoenent連接在一起。 orchestrator按順序運作pipeline,並根據定好的條件自動從一個步驟跳到另一個步驟。 例如,如果評估指標滿足已經定好的thresholds,則定好的條件(condition)可能會在模型評估步驟之後執行模型上線的步驟。 編排 ML pipeline在開發和生產階段都是有效的:
- 在開發階段,orchestration幫助資料科學家運作 ML experiment,而不是手動執行每個步驟。
- 在生產階段,orchestration有助於根據schedule或某些觸發條件自動執行 ML pipeline。
ML與 Kubeflow pipeline
Kubeflow 是一個開源的Kubernetes 框架,用於開發和運行portable的 ML workload。 Kubeflow Pipelines 是一個 Kubeflow service,可以讓我們compose、orchestrate和自動化 ML 系統,其中系統的每個component都可以在 Kubeflow、Google Cloud 或其他cloud platform上運行。 Kubeflow Pipelines 平台包括以下內容:
- 一個使用者介面來管理與追蹤experiments, jobs與runs.
- 用於scheduling multistep ML workflow的engine。 Kubeflow pipeline使用 Argo 來編排 Kubernetes resources。
- 用於定義和操作pipeline和component的 Python SDK。
- 使用 Python SDK 與系統交互的Notebooks。
- 一個 ML metadata store,用於保存有關executions、models、datasets和其他artifacts的資訊。
下面說明如何建置一個kubeflow pipeline:
- 一組容器化的 ML tasks或component。 pipeline component是一種打包成Docker image的self-contained code。 component會take input arguments, produces output files,,並在pipeline中執行一個step。
- ML tasks順序的規範,通過 Python DSL來定義。 workflow的topology是通過將upstream step的output連接到downstream step的input來定義的。 pipeline definition中的一個step會調用pipeline中的一個component。 在複雜的pipeline中,component可以循環執行多次,也可以有條件地執行。
- 一組pipeline input parameters,其values傳遞給pipeline的component,包括filter資料的標準以及pipeline產生的artifacts的存儲位置。
下面顯示了一個簡單的 kubeflow pipelines圖解
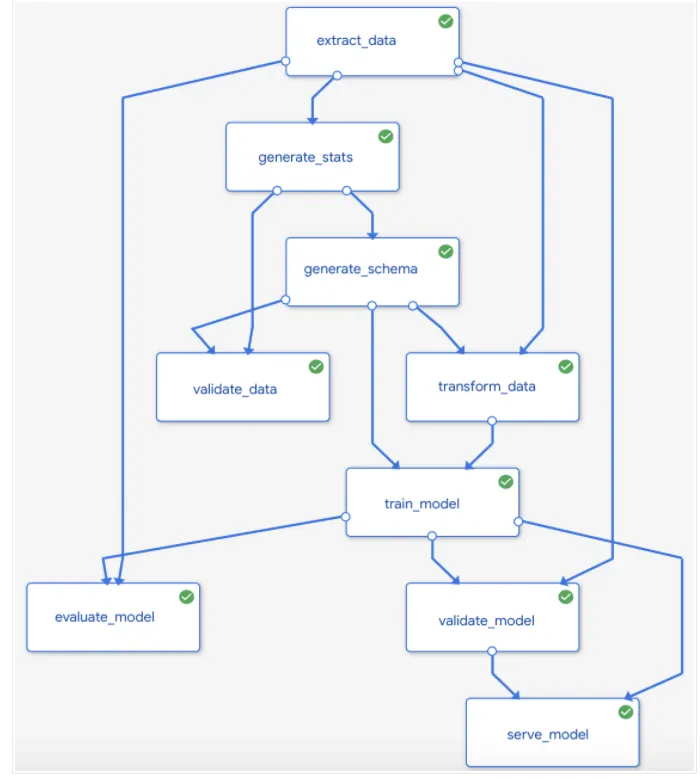
Kubeflow Pipeline components
對於要在pipeline中調用的component,我們需要建立一個 component op。 我們可以使用以下方法create component op:
- 實現lightweight Python component:這個component不需要我們為每次的code change建立新的container image,並且主要用在Notebook環境中的快速iteration。 我們可以使用 kfp.components.func_to_container_op function從 Python function建立lightweight component。
- Create reusable component:這個功能要求我們的component在 component.yaml 中包含component specification。 component specification在參數、要執行的 Docker container image URL 和output描述了 Kubeflow pipeline的component。 component ops是在pipeline compilation期間使用 Kubeflow Pipelines SDK 中的 ComponentStore.load_components function從 component.yaml 自動建立的。 reusable的 component.yaml specification可以共享到 AI Hub,以便在不同的 Kubeflow Pipelines project中進行組合。
- 使用predefined GCP component:Kubeflow Pipelines 提供預定義的component,這些component通過提供所需的參數在 GCP 上執行各種託管服務。 這些component可幫助我們使用 BigQuery、Dataflow、Dataproc 和 AI Platform 等服務執行task。 這些預定義的 Google Cloud component也可在 AI Hub 中使用。 與使用reusable component類似,這些component ops是通過 ComponentStore.load_components 根據預定義的component specification自動建立的。 其他預定義component可用於在 Kubeflow 和其他平台中執行作業。
我們還可以使用 TFX Pipeline DSL 與TFX component。 TFX component封裝了metadata functionality。 Driver 通過查詢metadata store向executor提供metadata。 Publisher接受executor的結果並將其存儲在metadata中。 我們還可以實現與metadata具有相同integration的自定義component。 TFX 提供了一個CLI,可將pipeline的 Python code編譯為 YAML file並描述 Argo workflow。 然後我們可以將這個file submit到 Kubeflow Pipelines。
下圖顯示了在 Kubeflow Pipelines 中,containerized task如何調用其他services,例如 BigQuery jobs、AI Platform(分佈式)訓練作業和 Dataflow jobs。
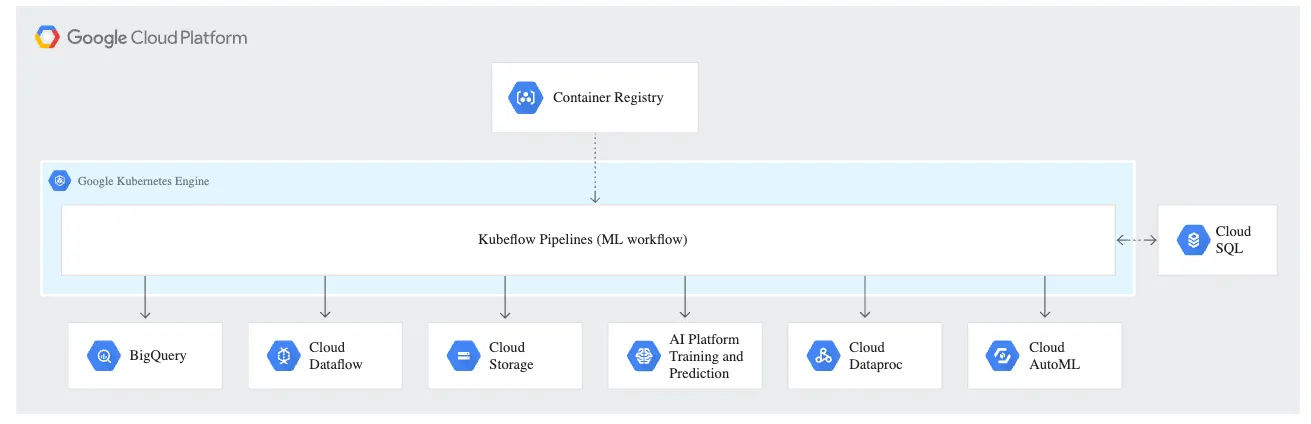
Kubeflow Pipelines 可讓我們通過執行所需的 GCP services來編排和自動化production ML pipeline。 上圖中,Cloud SQL 用作 Kubeflow Pipelines 的 ML metadata store。
Kubeflow Pipelines component不僅限於在 GCP 上執行與 TFX 相關的services。 這些component可以執行任何與data相關和compute相關的服務,包括用於 Dataproc for SparkML jobs、AutoML 與其他相關的compute workloads。
Kubeflow Pipelines 中的containerizing tasks具有以下優點:
- decouple 執行環境與code runtime。
- 在開發和生產環境之間提供代碼的reproducibility,因為我們測試的東西是要與production環境中是相同的。
- 隔離pipeline中的每個component; 每個都可以有自己的runtime version、不同的language和不同的libraries。
- 有助於複雜pipeline的組合。
- Integrate ML metadata store以實現traceability和reproducibility。
觸發與scheduling Kubeflow Pipelines
當我們將 Kubeflow pipeline部署到生產環境時,我們需要自動化來執行,具體取決於 我們在“ML與 Kubeflow pipeline”部分中討論的場景。
Kubeflow Pipelines 提供了一個 Python SDK 來以寫程式的方式操作pipeline。 kfp.Client class包括用於建立experiments以及部署和運行pipeline的 API。 通過使用 Kubeflow Pipelines SDK,我們可以使用以下service調用 Kubeflow Pipelines:
- 如果是排程作業,使用Cloud Scheduler
- 如果是event base, 使用 Pub/Sub 與Cloud functions. 例如,當有新的檔案到達Cloud storage bucket
- 如果是更大的資料與process workflow,使用 Cloud Composer或 Cloud Data Fusion
Kubeflow Pipeline同時也有內建的scheduler功能來負責重複性的pipelines.
在 Google Cloud設定 CI/CD
Kubeflow Pipelines 使我們能夠編排涉及多個步驟的 ML 系統,包括data preprocessing, model training and evaluation, model deployment。 在資料科學探索階段,Kubeflow Pipelines 有助於對整個系統進行快速實驗。 在生產階段,Kubeflow Pipelines 使我們能夠根據新資料自動執行pipeline來train or retrain ML 模型。
CI/CD 架構
以下是針對Kubeflow pipelines的CI/CD High-level overview.

該架構的核心是 Cloud Build,就是 infrastructure 。 Cloud Build 可以從 Cloud Source Repositories、GitHub 或 Bitbucket 導入source code,然後根據我們的specification執行build,並產生artifacts,例如 Docker containers或 Python tar 檔。
Cloud Build 將我們的build作為一系列build steps執行,在build configuration file(cloudbuild.yaml) 中定義。每個build step都在 Docker container中運行。我們可以使用 Cloud Build 提供的受支援的build step,也可以編寫自己的build steps。
Cloud Build process為我們的 ML 系統執行所需的 CI/CD,可以手動或通過自動build triggers執行。只要將changes推送到buils source,trigger就會執行我們配置的build steps。我們可以設置build trigger以在對source repository進行changes時執行build routine,或者當change符合特定條件時才執行build routine。
此外,我們可以有根據不同的response而有不同trigger而執行的build routine(Cloud Build configuration)。例如,我們可以進行以下設定:
- 當development branch發生commit時,build routine就會開始執行
- 當master branch發生commit時,build routine就會開始執行
我們可以使用configuration variable substitutions在build時定義環境變數。 這些substitutions是從trigger的build中擷取的。 這些變數包括 $COMMIT_SHA、$REPO_NAME、$BRANCE_NAME、$TAG_NAME 和 $REVISION_ID。 其他非基於trigger的變數是 $PROJECT_ID 和 $BUILD_ID。 substitutions對於在build時才知道其value的變數是有幫助,或者可以reuse具有不同變數value的現有build request。
CI/CD workflow case
一個source code repository通常包含以下的項目:
- 用於implement Kubeflow Pipelines component的 Python source code,包括資料驗證、資料轉換、模型訓練、模型評估和model serving。
- Python unit tests來測試component中implement的方法。
- Create Docker container image所需的 Dockerfile,每個 Kubeflow Pipelines component對應一個。
- 定義pipeline component specification的 component.yaml files。 這些specification用在pipeline定義中生成component ops。
- 定義Kubeflow Pipelines workflow的 Python module(例如,pipeline.py module)。
- 其他scripts和configuration files,包括 cloudbuild.yaml file。
- 用於EDA、模型分析和模型交互實驗的Notbook。
- Setting file(例如 settings.yaml),包括pipeline input parameters的configuration。
下面的範例是,當開發人員將source code從其資料科學家深的環境推送到development branch時,會觸發build routine。

上圖中 Cloud Build做了以下的動作:
- source code repository複製到 Cloud Build runtime environment的 /workspace 目錄下。
- 運行Unit testing。
- Optional-運行Static code analysis,如 Pylint。
- 如果測試通過,則build Docker container image,每個 Kubeflow Pipelines component一個。images用 $COMMIT_SHA 參數標記。
- Docker container image 將上傳到 Container Registry。
- image URL 在每個 component.yamlfiles 中使用create和tag的 Docker container image進行更新。
- compile Kubeflow Pipelines workflow以產生workflow.tar.gz file。
- workflow.tar.gz file上傳到 Cloud Storage。
- 將compile好的pipeline部署到 Kubeflow Pipelines 中,包括以下步驟:
a. 從 settings.yaml file中讀取pipeline parameters。
b. create an experiment(或使用現有的)。
c. 將pipeline部署到 Kubeflow Pipelines(並用版本標記名稱)。 - Optional-使用parameter values運行pipeline作為integration test或production execution的一部分。執行的pipeline最終將模型部署為 AI Platform 上的 API。
額外的考量
當我們在Google Cloud上設定ML CI/CD 架構時需要注意以下事項:
- 對於資料科學家自己的開發環境,我們可以使用桌機或基於深度學習 VM (DLVM) 的 Notebooks instance。
- 我們可以設定自動化 Cloud Build pipeline 跳過trigger,例如,如果僅編輯文檔或修改experimentation notebooks。
- 我們可以將integration and regression testing 的pipeline作為build test。在pipeline部署到目標環境之前,我們可以使用 wait_for_pipeline_completion 方法在sample dataset上執行pipeline來測試這個pipeline。
- 作為使用 Cloud Build 的替代方案,我們可以使用其他build system,例如 Jenkins。 Google Cloud Marketplace 上提供了現成的 Jenkins 的部署。
- 我們可以根據不同的trigger自動部署到不同的環境來可以configure pipeline,包括development, test, staging,。此外,我們可以手動部署到特定環境,例如pre-production或production,通常是在獲得發布批准後。我們可以為不同的trigger或不同的目標環境設置多個build routine。
- 我們可以將 Apache Airflow用於通用的workflow,我們也可以使用完全託管的 Cloud Composer service運行這些workflow。
- 當我們將模型的新版本部署到production中時,將其部署為canary release以了解它將如何執行(CPU、memory和disk usage使用情況)。在正式上線之前,我們還可以執行 A/B testing。將真實流量的10–20 %導入到新的模型。如果新模型的效能優於當前模型,我們可以將所有流量導入到模型。否則,就rollback到上一個良好的模型版本。
